Năm ngoái, tôi đã đăng một mẹo có tên Cải thiện hiệu quả máy chủ SQL bằng cách Chuyển sang INSTEAD OF Trigger.
Lý do lớn nhất mà tôi có xu hướng ủng hộ trình kích hoạt INSTEAD OF, đặc biệt là trong những trường hợp mà tôi mong đợi có nhiều vi phạm logic nghiệp vụ, là do có vẻ trực quan rằng việc ngăn chặn hoàn toàn một hành động sẽ rẻ hơn là tiếp tục và thực hiện nó (và ghi lại!), chỉ để sử dụng trình kích hoạt SAU KHI xóa các hàng vi phạm (hoặc quay lại toàn bộ hoạt động). Kết quả hiển thị trong mẹo đó đã chứng minh rằng thực tế là trường hợp này - và tôi nghi ngờ rằng chúng sẽ còn rõ ràng hơn với nhiều chỉ mục không phân cụm bị ảnh hưởng bởi hoạt động.
Tuy nhiên, đó là trên ổ đĩa chậm và trên CTP đầu tiên của SQL Server 2014. Khi chuẩn bị trang trình bày cho bản trình bày mới, tôi sẽ thực hiện trong năm nay về trình kích hoạt, tôi nhận thấy rằng trên bản dựng mới hơn của SQL Server 2014 - kết hợp với phần cứng được cập nhật - sẽ phức tạp hơn một chút khi chứng minh cùng một vùng đồng bằng về hiệu suất giữa một trình kích hoạt SAU và INSTEAD OF. Vì vậy, tôi bắt đầu tìm hiểu lý do tại sao, mặc dù ngay lập tức tôi biết rằng đây sẽ là công việc nhiều hơn tôi từng làm cho một trang trình bày.
Một điều tôi muốn đề cập là trình kích hoạt có thể sử dụng tempdb theo những cách khác nhau và điều này có thể giải thích cho một số khác biệt này. Trình kích hoạt SAU KHI sử dụng kho phiên bản cho các bảng giả đã được chèn và đã xóa, trong khi trình kích hoạt INSTEAD OF tạo bản sao của dữ liệu này trong bảng làm việc nội bộ. Sự khác biệt là nhỏ, nhưng đáng để chỉ ra.
Các biến
Tôi sẽ thử nghiệm các tình huống khác nhau, bao gồm:
- Ba trình kích hoạt khác nhau:
- Trình kích hoạt SAU KHI xóa các hàng cụ thể bị lỗi
- Một trình kích hoạt SAU KHI quay lại toàn bộ giao dịch nếu bất kỳ hàng nào không thành công
- Trình kích hoạt INSTEAD OF chỉ chèn các hàng vượt qua
- Các mô hình khôi phục khác nhau và cài đặt cách ly ảnh chụp nhanh:
- ĐẦY ĐỦ với SNAPSHOT được bật
- ĐẦY ĐỦ với SNAPSHOT bị tắt
- ĐƠN GIẢN với SNAPSHOT được bật
- ĐƠN GIẢN với SNAPSHOT bị tắt
- Các bố cục đĩa khác nhau *:
- Dữ liệu trên SSD, đăng nhập trên 7200 RPM HDD
- Dữ liệu trên SSD, đăng nhập trên SSD
- Dữ liệu trên 7200 RPM HDD, đăng nhập trên SSD
- Dữ liệu trên HDD 7200 RPM, đăng nhập trên HDD 7200 RPM
- Tỷ lệ thất bại khác nhau:
- Tỷ lệ thất bại 10%, 25% và 50% trên:
- Chèn hàng loạt 20.000 hàng
- 10 lô gồm 2.000 hàng
- 100 lô gồm 200 hàng
- 1.000 lô gồm 20 hàng
- 20.000 hạt chèn singleton
*
tempdblà một tệp dữ liệu duy nhất trên đĩa 7200 RPM chậm. Điều này là có chủ đích và nhằm khuếch đại bất kỳ tắc nghẽn nào do việc sử dụngtempdbkhác nhau gây ra . Tôi dự định sẽ truy cập lại bài kiểm tra này vào một lúc nào đó khitempdbtrên SSD nhanh hơn. - Tỷ lệ thất bại 10%, 25% và 50% trên:
Được rồi, TL; DR Đã có!
Nếu bạn chỉ muốn biết kết quả, hãy bỏ qua. Mọi thứ ở giữa chỉ là nền tảng và giải thích về cách tôi thiết lập và chạy các bài kiểm tra. Tôi không đau lòng rằng không phải ai cũng sẽ quan tâm đến tất cả những điều vụn vặt.
Tình huống
Đối với tập hợp các bài kiểm tra cụ thể này, tình huống thực tế là tình huống trong đó người dùng chọn tên màn hình và trình kích hoạt được thiết kế để bắt các trường hợp tên đã chọn vi phạm một số quy tắc. Ví dụ:nó không thể là bất kỳ biến thể nào của "ninny-muggins" (bạn chắc chắn có thể sử dụng trí tưởng tượng của mình ở đây).
Tôi đã tạo một bảng với 20.000 tên người dùng duy nhất:
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
Sau đó, tôi tạo một bảng sẽ là nguồn để kiểm tra các "tên nghịch ngợm" của tôi. Trong trường hợp này, nó chỉ là ninny-muggins-00001 thông qua ninny-muggins-10000 :
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
Tôi đã tạo các bảng này trong model cơ sở dữ liệu để mỗi khi tôi tạo cơ sở dữ liệu, nó sẽ tồn tại cục bộ và tôi dự định tạo nhiều cơ sở dữ liệu để kiểm tra ma trận kịch bản được liệt kê ở trên (thay vì chỉ thay đổi cài đặt cơ sở dữ liệu, xóa nhật ký, v.v.). Xin lưu ý, nếu bạn tạo các đối tượng trong mô hình cho mục đích thử nghiệm, hãy đảm bảo rằng bạn xóa các đối tượng đó khi hoàn tất.
Ngoài ra, tôi sẽ cố ý loại bỏ các lỗi vi phạm chính và xử lý lỗi khác, tạo ra giả định ngây thơ rằng tên đã chọn được kiểm tra tính duy nhất rất lâu trước khi thử chèn, nhưng trong cùng một giao dịch (giống như kiểm tra lại bảng tên nghịch ngợm có thể đã được lập trước).
Để hỗ trợ điều này, tôi cũng đã tạo ba bảng gần giống nhau sau đây trong model , cho mục đích cách ly thử nghiệm:
USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
Và ba trình kích hoạt sau, một trình kích hoạt cho mỗi bảng:
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO Bạn có thể muốn xem xét xử lý bổ sung để thông báo cho người dùng rằng lựa chọn của họ đã được khôi phục hoặc bị bỏ qua - nhưng điều này cũng bị loại bỏ vì đơn giản.
Thiết lập thử nghiệm
Tôi đã tạo dữ liệu mẫu đại diện cho ba tỷ lệ thất bại mà tôi muốn kiểm tra, thay đổi 10 phần trăm thành 25 và sau đó là 50, đồng thời thêm các bảng này vào model :
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ Mỗi bảng có 20.000 hàng, với sự kết hợp khác nhau của các tên sẽ đạt và không đạt, và cột số hàng giúp dễ dàng phân chia dữ liệu thành các kích thước lô khác nhau cho các thử nghiệm khác nhau, nhưng với tỷ lệ thất bại có thể lặp lại cho tất cả các thử nghiệm.
Tất nhiên chúng ta cần một nơi để nắm bắt kết quả. Tôi đã chọn sử dụng một cơ sở dữ liệu riêng cho việc này, chạy mỗi bài kiểm tra nhiều lần, chỉ cần nắm bắt thời lượng.
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
Tôi đã điền dbo.Tests bảng với tập lệnh sau, để tôi có thể thực thi các phần khác nhau để thiết lập bốn cơ sở dữ liệu phù hợp với các tham số kiểm tra hiện tại. Lưu ý rằng D:\ là SSD, trong khi G:\ là đĩa 7200 RPM:
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) Sau đó, thật đơn giản để chạy tất cả các thử nghiệm nhiều lần:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
Trên hệ thống của tôi, quá trình này mất gần 6 giờ, vì vậy hãy chuẩn bị để quá trình này chạy không bị gián đoạn. Ngoài ra, hãy đảm bảo rằng bạn không có bất kỳ kết nối đang hoạt động nào hoặc cửa sổ truy vấn nào đang mở đối với model cơ sở dữ liệu, nếu không, bạn có thể gặp lỗi này khi tập lệnh cố gắng tạo cơ sở dữ liệu:
Không thể có được khóa độc quyền trên 'mô hình' cơ sở dữ liệu. Thử lại thao tác sau.
Kết quả
Có nhiều điểm dữ liệu để xem xét (và tất cả các truy vấn được sử dụng để lấy dữ liệu được tham chiếu trong Phụ lục). Hãy nhớ rằng mỗi thời lượng trung bình được biểu thị ở đây là hơn 10 lần kiểm tra và đang chèn tổng số 100.000 hàng vào bảng đích.
Đồ thị 1 - Tổng thể Tổng thể
Biểu đồ đầu tiên hiển thị tổng thể tổng thể (thời lượng trung bình) cho các biến khác nhau một cách riêng biệt (vì vậy * tất cả * kiểm tra bằng cách sử dụng trình kích hoạt SAU sẽ xóa, * tất cả * kiểm tra bằng cách sử dụng trình kích hoạt SAU quay trở lại, v.v.).
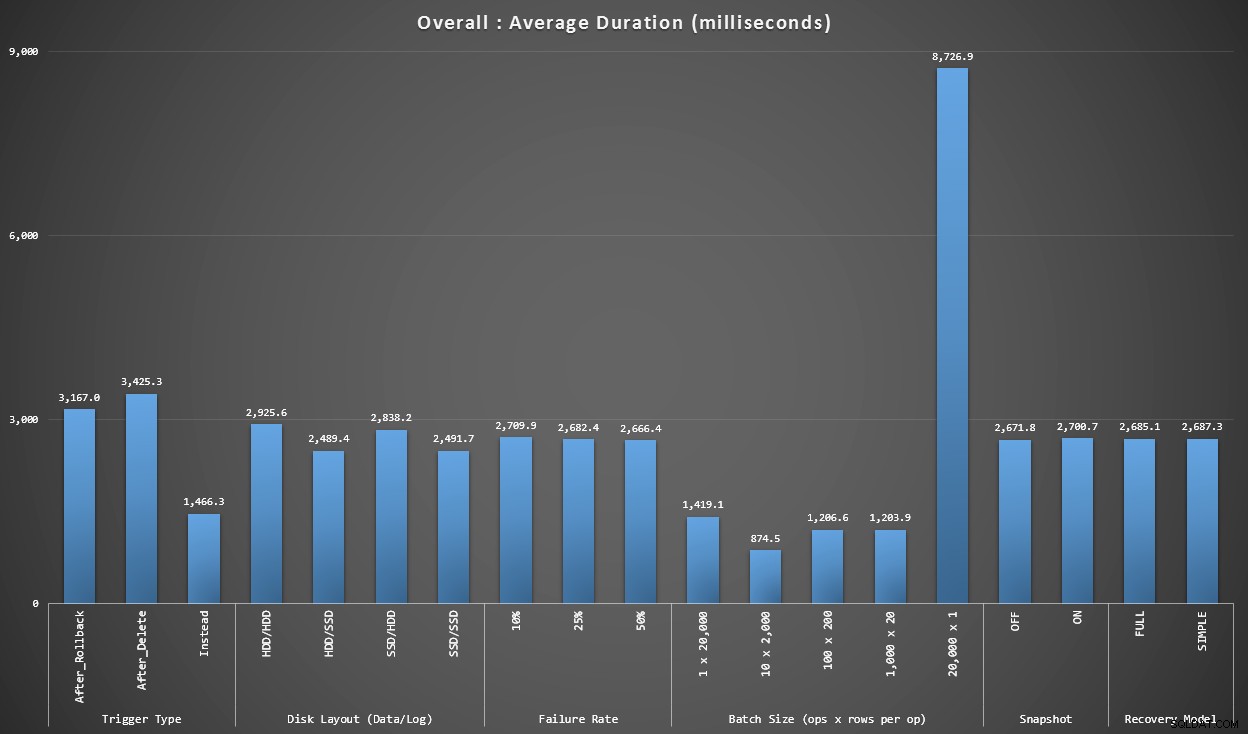
Thời lượng trung bình, tính bằng mili giây, cho từng biến riêng biệt
Một vài điều khiến chúng tôi bật ra ngay lập tức:
- Trình kích hoạt INSTEAD OF ở đây nhanh gấp đôi so với cả hai trình kích hoạt SAU.
- Việc có nhật ký giao dịch trên SSD đã tạo ra một chút khác biệt. Vị trí của tệp dữ liệu ít hơn nhiều.
- Lô 20.000 miếng chèn singleton chậm hơn 7-8 lần so với bất kỳ đợt phân phối hàng loạt nào khác.
- Việc chèn hàng loạt 20.000 hàng duy nhất chậm hơn bất kỳ bản phân phối không phải đơn lẻ nào.
- Tỷ lệ lỗi, mô hình cách ly và khôi phục ảnh chụp nhanh có rất ít tác động đến hiệu suất.
Biểu đồ 2 - Tổng thể 10 Tốt nhất
Biểu đồ này hiển thị 10 kết quả nhanh nhất khi mọi biến được xem xét. Đây là tất cả các trình kích hoạt INSTEAD OF trong đó tỷ lệ hàng lỗi lớn nhất (50%). Đáng ngạc nhiên là tốc độ nhanh nhất (mặc dù không nhiều) có cả dữ liệu và đăng nhập trên cùng một ổ cứng (không phải SSD). Có sự kết hợp của bố cục đĩa và mô hình khôi phục ở đây, nhưng cả 10 đều đã bật tính năng cô lập ảnh chụp nhanh và 7 kết quả hàng đầu đều liên quan đến kích thước lô hàng 10 x 2.000.
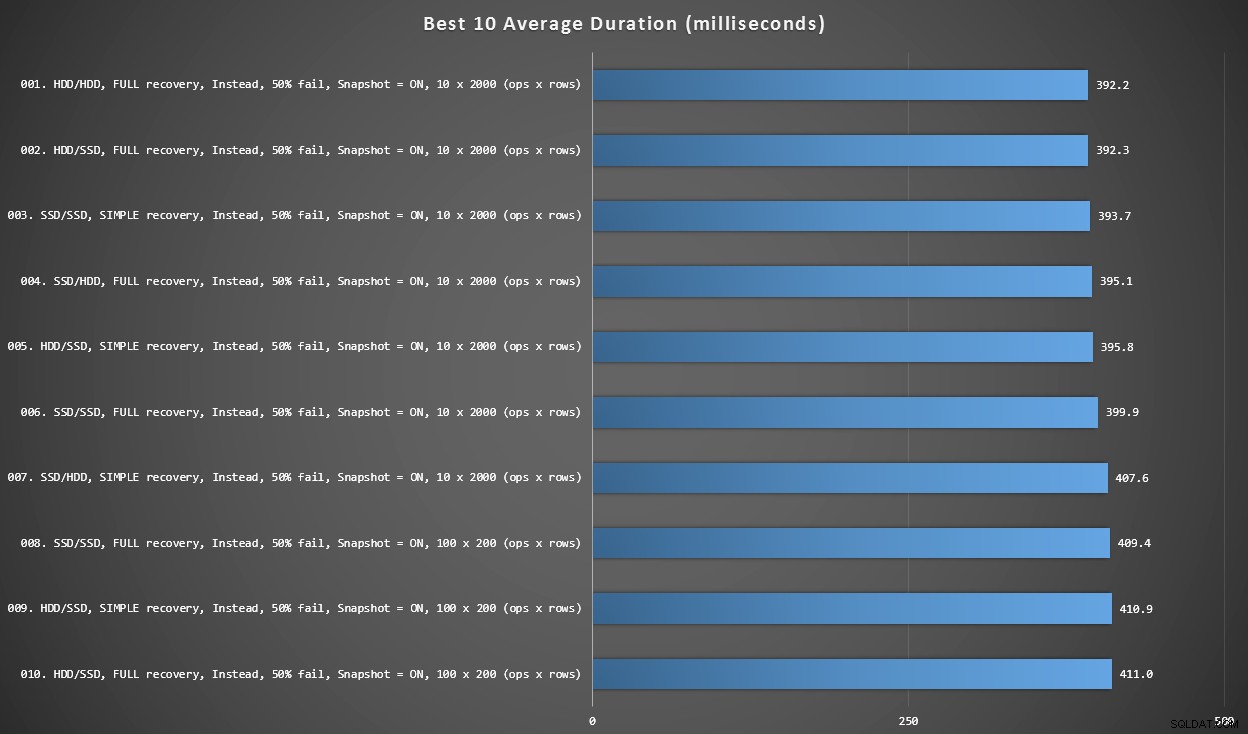
10 thời lượng tốt nhất, tính bằng mili giây, xem xét mọi biến
Trình kích hoạt SAU KHI nhanh nhất - một biến thể ROLLBACK với tỷ lệ lỗi 10% ở kích thước lô hàng 100 x 200 - ở vị trí # 144 (806 mili giây).
Biểu đồ 3 - Nhìn chung là tệ nhất 10
Biểu đồ này hiển thị 10 kết quả chậm nhất khi mọi biến được xem xét; tất cả đều là biến thể SAU KHI, tất cả đều liên quan đến 20.000 hạt chèn singleton, và tất cả đều có dữ liệu và đăng nhập trên cùng một ổ cứng chậm.
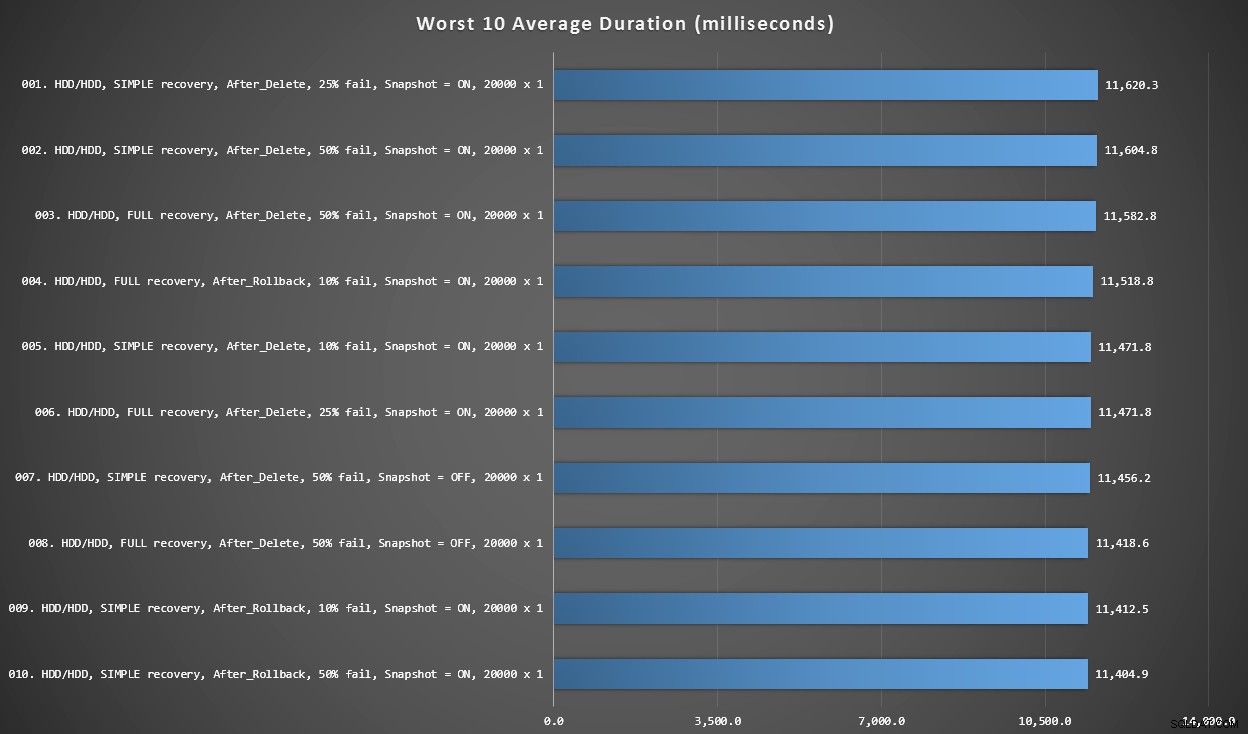
10 thời lượng tồi tệ nhất, tính bằng mili giây, xem xét mọi biến
Thử nghiệm INSTEAD OF chậm nhất là ở vị trí số 97, với tốc độ 5.680 mili giây - thử nghiệm chèn 20.000 tấn đơn trong đó 10% không đạt. Cũng rất thú vị khi quan sát thấy rằng không có một lần kích hoạt SAU KHI sử dụng kích thước lô 20.000 tấn chèn đơn lẻ hoạt động tốt hơn - trên thực tế, kết quả tồi tệ thứ 96 là thử nghiệm SAU (xóa) với tốc độ 10,219 mili giây - gần gấp đôi kết quả chậm nhất tiếp theo.
Đồ thị 4 - Loại đĩa ghi nhật ký, Chèn Singleton
Các biểu đồ trên cho chúng ta một ý tưởng sơ bộ về những điểm khó khăn lớn nhất, nhưng chúng được phóng to quá mức hoặc không được phóng to đủ. Biểu đồ này lọc xuống dữ liệu dựa trên thực tế:trong hầu hết các trường hợp, kiểu hoạt động này sẽ là một phép chèn singleton. Tôi nghĩ rằng tôi sẽ chia nhỏ nó theo tỷ lệ lỗi và loại đĩa mà nhật ký đang sử dụng, nhưng chỉ xem xét các hàng trong đó lô được tạo thành từ 20.000 lần chèn riêng lẻ.
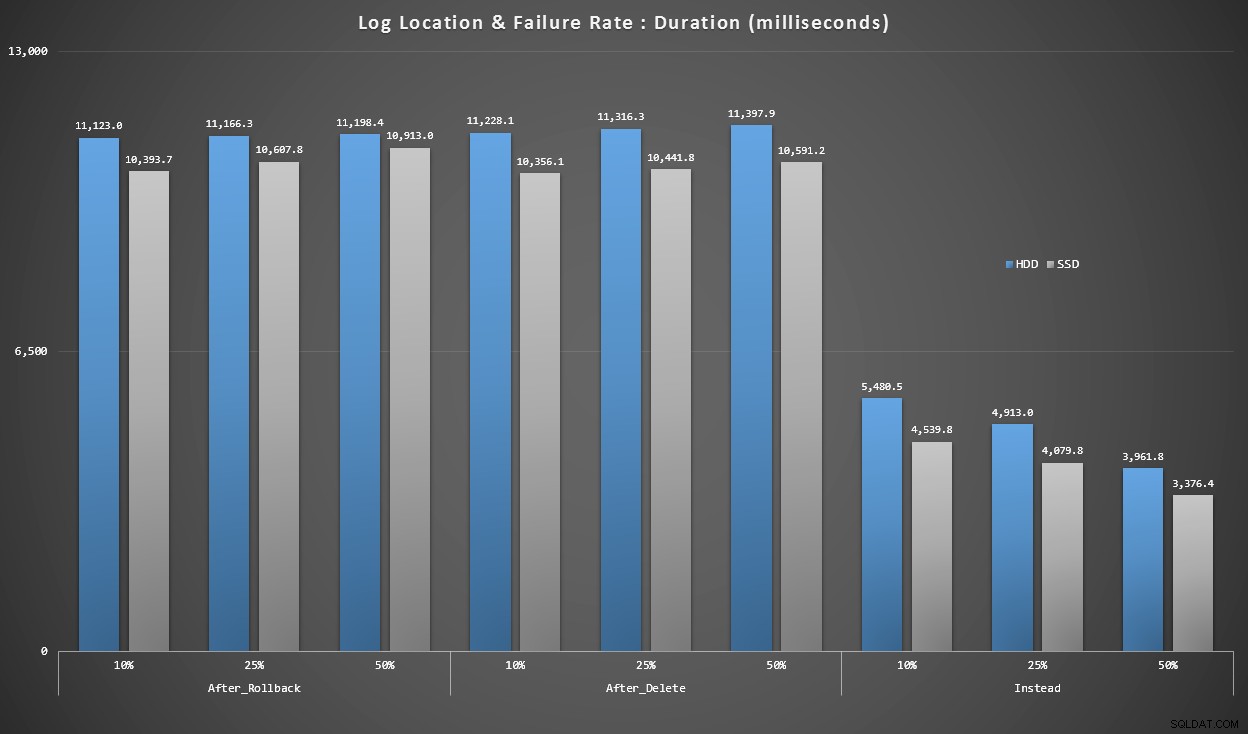
Thời lượng, tính bằng mili giây, được nhóm theo tỷ lệ lỗi và vị trí nhật ký, cho 20.000 lần chèn riêng lẻ
Ở đây, chúng tôi thấy rằng tất cả các kích hoạt SAU KHI trung bình trong phạm vi 10-11 giây (tùy thuộc vào vị trí nhật ký), trong khi tất cả các kích hoạt INSTEAD OF đều thấp hơn rất nhiều so với mốc 6 giây.
Kết luận
Cho đến nay, tôi thấy rõ ràng rằng trình kích hoạt INSTEAD OF là người chiến thắng trong hầu hết các trường hợp - trong một số trường hợp còn hơn những trường hợp khác (ví dụ:khi tỷ lệ thất bại tăng lên). Các yếu tố khác, chẳng hạn như mô hình phục hồi, dường như ít ảnh hưởng hơn đến hiệu suất tổng thể.
Nếu bạn có ý tưởng khác về cách chia nhỏ dữ liệu hoặc muốn có một bản sao dữ liệu để thực hiện việc cắt và phân loại dữ liệu của riêng bạn, vui lòng cho tôi biết. Nếu bạn muốn được trợ giúp thiết lập môi trường này để bạn có thể chạy các bài kiểm tra của riêng mình, tôi cũng có thể giúp bạn.
Mặc dù thử nghiệm này cho thấy rằng các kích hoạt INSTEAD OF chắc chắn đáng xem xét, nhưng đó không phải là toàn bộ câu chuyện. Tôi thực sự đã ghép các trình kích hoạt này lại với nhau bằng cách sử dụng logic mà tôi nghĩ là hợp lý nhất cho mỗi tình huống, nhưng mã kích hoạt - giống như bất kỳ câu lệnh T-SQL nào - có thể được điều chỉnh để có kế hoạch tối ưu. Trong một bài đăng tiếp theo, tôi sẽ xem xét một cách tối ưu hóa tiềm năng có thể làm cho kích hoạt SAU có tính cạnh tranh hơn.
Phụ lục
Các truy vấn được sử dụng cho phần Kết quả:
Đồ thị 1 - Tổng thể Tổng thể
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
Đồ thị 2 &3 - Tốt nhất &Tồi tệ nhất 10
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; Đồ thị 4 - Loại đĩa ghi nhật ký, Chèn Singleton
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;