T-SQL Thứ Ba # 78 đang được tổ chức bởi Wendy Pastrick và thử thách trong tháng này chỉ đơn giản là "tìm hiểu một cái gì đó mới và viết blog về nó." Sự nổi bật của cô ấy nghiêng về các tính năng mới trong SQL Server 2016, nhưng vì tôi đã viết blog và trình bày về nhiều tính năng trong số đó, nên tôi nghĩ mình sẽ khám phá một thứ gì đó khác mà tôi luôn thực sự tò mò.
Tôi đã thấy nhiều người nói rằng một đống có thể tốt hơn một chỉ mục nhóm cho một số trường hợp nhất định. Tôi không thể không đồng ý với điều đó. Tuy nhiên, một trong những lý do thú vị mà tôi đã nêu là Tra cứu RID nhanh hơn Tra cứu khóa. Tôi là một người yêu thích các chỉ mục theo cụm chứ không phải là một fan cuồng của đống, vì vậy tôi cảm thấy điều này cần một số thử nghiệm.
Vì vậy, hãy thử nghiệm nó!
Tôi nghĩ sẽ rất tốt nếu tạo một cơ sở dữ liệu có hai bảng, giống hệt nhau ngoại trừ một bảng có khóa chính được phân nhóm và bảng còn lại có khóa chính không được phân cụm. Tôi đã có thời gian tải một số hàng vào bảng, cập nhật một loạt các hàng trong một vòng lặp và chọn từ một chỉ mục (buộc Tra cứu khóa hoặc RID).
Thông số hệ thống
Câu hỏi này thường xuất hiện, vì vậy để làm rõ các chi tiết quan trọng về hệ thống này, tôi đang sử dụng máy ảo 8 lõi với 32 GB RAM, được hỗ trợ bởi bộ nhớ PCIe. Phiên bản SQL Server là 2014 SP1 CU6, không có thay đổi cấu hình đặc biệt hoặc cờ theo dõi đang chạy:
Microsoft SQL Server 2014 (SP1-CU6) (KB3144524) - 12.0.4449.0 (X64)13 tháng 4 2016 12:41:07
Bản quyền (c) Microsoft Corporation
Developer Edition (64- bit) trên Windows NT 6.3
Cơ sở dữ liệu
Tôi đã tạo cơ sở dữ liệu với nhiều dung lượng trống trong cả dữ liệu và tệp nhật ký để ngăn bất kỳ sự kiện tự động duyệt nào can thiệp vào các bài kiểm tra. Tôi cũng đặt cơ sở dữ liệu thành khôi phục đơn giản để giảm thiểu tác động đến nhật ký giao dịch.
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
Các bảng
Như tôi đã nói, hai bảng, với sự khác biệt duy nhất là khóa chính có được nhóm hay không.
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
Bảng để chụp thời gian chạy
Tôi có thể giám sát CPU và tất cả những thứ đó, nhưng thực sự thì sự tò mò hầu như luôn xoay quanh thời gian chạy. Vì vậy, tôi đã tạo một bảng ghi nhật ký để nắm bắt thời gian chạy của mỗi bài kiểm tra:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
Kiểm tra Chèn
Vì vậy, mất bao lâu để chèn 2.000 hàng, 100 lần? Tôi đang lấy một số dữ liệu khá cơ bản từ sys.all_objects và kéo theo định nghĩa cho mọi thủ tục, hàm, v.v.:
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Kiểm tra cập nhật
Đối với bài kiểm tra cập nhật, tôi chỉ muốn kiểm tra tốc độ ghi vào một chỉ mục được phân cụm so với một đống theo kiểu từng hàng một. Vì vậy, tôi đã đặt 200 hàng ngẫu nhiên vào bảng #temp, sau đó tạo một con trỏ xung quanh nó (bảng #temp chỉ đảm bảo rằng 200 hàng giống nhau được cập nhật trong cả hai phiên bản của bảng, điều này có thể là quá mức cần thiết).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Kiểm tra lựa chọn
Vì vậy, ở trên bạn đã thấy rằng tôi đã tạo một chỉ mục với Name làm cột quan trọng trong mỗi bảng; để đánh giá chi phí thực hiện tra cứu cho một số lượng hàng đáng kể, tôi đã viết một truy vấn chỉ định đầu ra cho một biến (loại bỏ I / O mạng và thời gian hiển thị ứng dụng khách), nhưng buộc sử dụng chỉ mục:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Đối với điều này, tôi muốn chỉ ra một số khía cạnh thú vị của kế hoạch trước khi đối chiếu kết quả thử nghiệm. Việc chạy chúng đối đầu trực tiếp với nhau cung cấp các số liệu so sánh sau:

Thời lượng là không quan trọng đối với một câu lệnh, nhưng hãy nhìn vào những lần đọc đó. Nếu bạn đang sử dụng bộ nhớ chậm, đó là sự khác biệt lớn mà bạn sẽ không thấy ở quy mô nhỏ hơn và / hoặc trên SSD phát triển cục bộ của mình.
Và sau đó là các kế hoạch hiển thị hai cách tra cứu khác nhau, sử dụng SQL Sentry Plan Explorer:

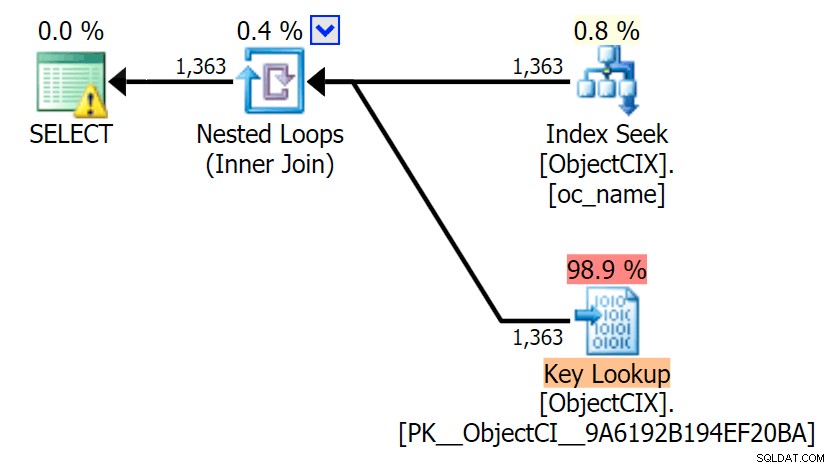
Các kế hoạch trông gần như giống hệt nhau và bạn có thể không nhận thấy sự khác biệt về số lần đọc trong SSMS trừ khi bạn đang nắm bắt I / O Thống kê. Ngay cả chi phí I / O ước tính cho hai lần tra cứu cũng tương tự - 1,69 cho Tra cứu khóa và 1,59 cho tra cứu RID. (Biểu tượng cảnh báo trong cả hai kế hoạch đều dành cho chỉ mục bao trùm bị thiếu.)
Điều thú vị cần lưu ý là nếu chúng tôi không buộc phải tra cứu và cho phép SQL Server quyết định phải làm gì, thì nó sẽ chọn quét tiêu chuẩn trong cả hai trường hợp - không có cảnh báo chỉ mục bị thiếu và xem các lần đọc gần hơn bao nhiêu:

Trình tối ưu hóa biết rằng quét sẽ rẻ hơn nhiều so với tìm kiếm + tra cứu trong trường hợp này. Tôi đã chọn một cột LOB để chỉ định biến chỉ có hiệu lực, nhưng kết quả cũng tương tự khi sử dụng cột không phải LOB.
Kết quả kiểm tra
Với bảng Thời gian tại chỗ, tôi có thể dễ dàng chạy các bài kiểm tra nhiều lần (tôi đã chạy hàng chục bài kiểm tra) và sau đó đưa ra giá trị trung bình cho các bài kiểm tra với truy vấn sau:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
Một biểu đồ thanh đơn giản cho thấy cách họ so sánh:
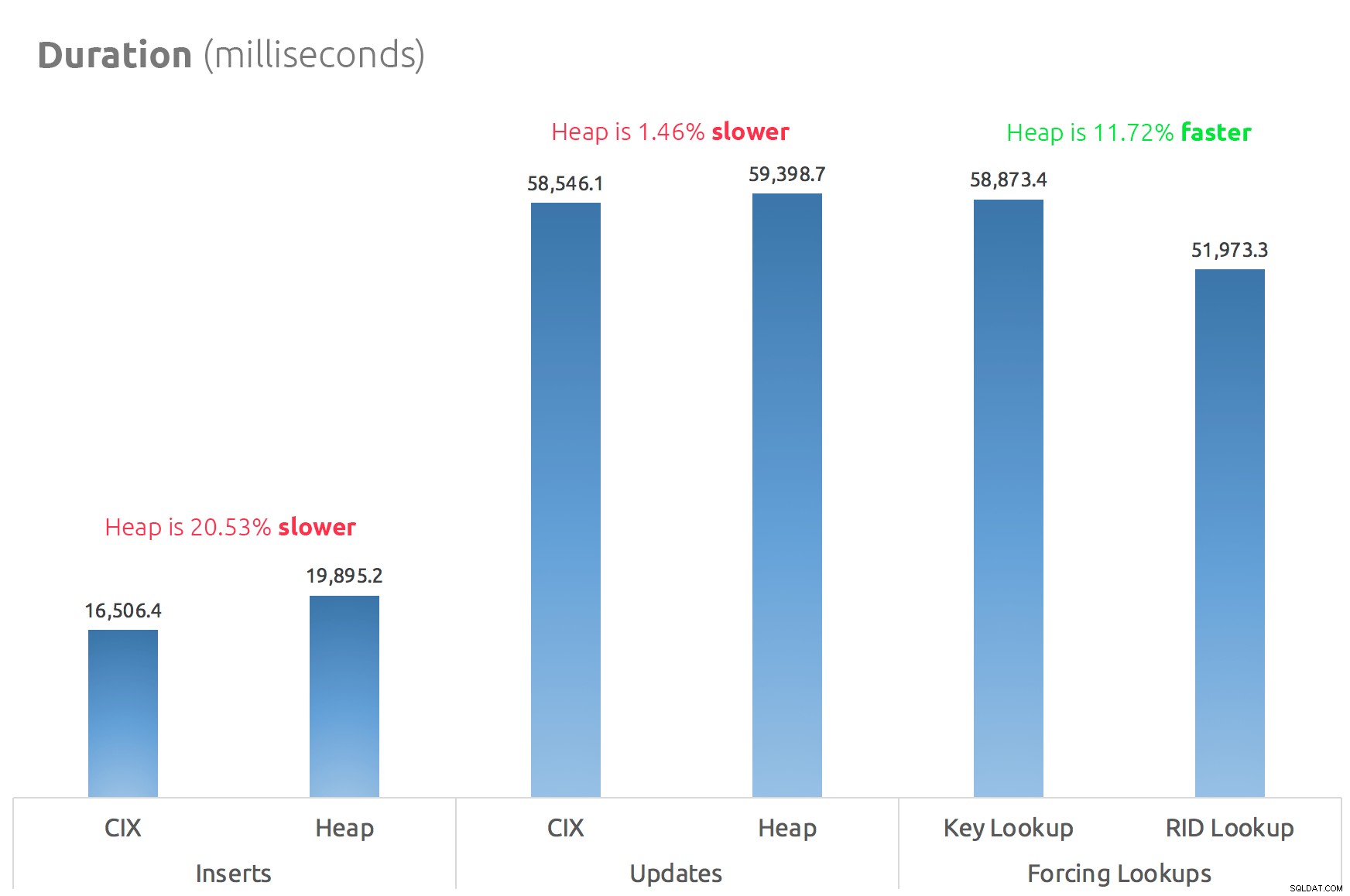
Kết luận
Vì vậy, tin đồn là đúng:ít nhất trong trường hợp này, Tra cứu RID nhanh hơn đáng kể so với Tra cứu khóa. Truy cập trực tiếp vào tệp:page:slot rõ ràng là hiệu quả hơn về mặt I / O so với việc theo dõi b-tree (và nếu bạn không sử dụng bộ lưu trữ hiện đại, delta có thể đáng chú ý hơn nhiều).
Cho dù bạn muốn tận dụng điều đó và mang theo tất cả các khía cạnh khác của heap, sẽ phụ thuộc vào khối lượng công việc của bạn - heap đắt hơn một chút cho các hoạt động ghi. Nhưng đây là không dứt khoát - điều này có thể thay đổi rất nhiều tùy thuộc vào cấu trúc bảng, chỉ mục và mẫu truy cập.
Tôi đã thử nghiệm những thứ rất đơn giản ở đây và nếu bạn đang ở trong hàng rào về điều này, tôi thực sự khuyên bạn nên thử nghiệm khối lượng công việc thực tế của mình trên phần cứng của riêng bạn và tự so sánh (và đừng quên kiểm tra cùng một khối lượng công việc khi có các chỉ mục); bạn có thể sẽ nhận được hiệu suất tổng thể tốt hơn nhiều nếu bạn có thể đơn giản loại bỏ hoàn toàn việc tra cứu). Đảm bảo đo lường tất cả các chỉ số quan trọng đối với bạn; chỉ vì tôi tập trung vào thời lượng không có nghĩa đó là thời lượng bạn cần quan tâm nhất. :-)