Bài viết này cho thấy cách SQL Server kết hợp thông tin mật độ từ nhiều thống kê cột đơn, để tạo ra ước tính số lượng cho một tập hợp trên nhiều cột. Các chi tiết hy vọng là thú vị trong chính họ. Chúng cũng cung cấp thông tin chi tiết về một số cách tiếp cận và thuật toán chung được sử dụng bởi công cụ ước tính bản số.
Hãy xem xét truy vấn cơ sở dữ liệu mẫu AdventureWorks sau đây, truy vấn này liệt kê số lượng sản phẩm tồn kho trong mỗi thùng trên mỗi kệ trong nhà kho:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin;
Kế hoạch thực thi ước tính hiển thị 1.069 hàng đang được đọc từ bảng, được sắp xếp vào Shelf và Bin đặt hàng, sau đó được tổng hợp bằng toán tử Tổng hợp Luồng:
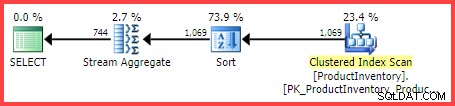
Kế hoạch thực hiện ước tính
Câu hỏi đặt ra là, làm cách nào mà trình tối ưu hóa truy vấn SQL Server đến ước tính cuối cùng là 744 hàng?
Thống kê có sẵn
Khi biên dịch truy vấn ở trên, trình tối ưu hóa truy vấn sẽ tạo thống kê cột đơn trên Shelf và Bin các cột, nếu số liệu thống kê phù hợp chưa tồn tại. Ngoài những thứ khác, những thống kê này cung cấp thông tin về số lượng giá trị cột riêng biệt (trong vectơ mật độ):
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Shelf]
)
WITH DENSITY_VECTOR;
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Bin]
)
WITH DENSITY_VECTOR; Kết quả được tóm tắt trong bảng dưới đây (cột thứ ba được tính từ mật độ):
| Cột | Mật độ | 1 / Mật độ |
|---|---|---|
| Giá | 0,04761905 | 21 |
| Thùng | 0,01612903 | 62 |
Thông tin vectơ mật độ thùng và giá
Như tài liệu lưu ý, nghịch đảo của mật độ là số lượng các giá trị khác biệt trong cột. Từ thông tin thống kê được hiển thị ở trên, SQL Server biết rằng có 21 Shelf riêng biệt các giá trị và 62 Bin riêng biệt trong bảng, khi thống kê được thu thập.
Nhiệm vụ ước tính số hàng được tạo bởi GROUP BY mệnh đề là tầm thường khi chỉ có một cột duy nhất được tham gia (giả sử không có vị từ nào khác). Ví dụ:có thể dễ dàng thấy rằng GROUP BY Shelf sẽ tạo ra 21 hàng; GROUP BY Bin sẽ sản xuất 62.
Tuy nhiên, không rõ ngay lập tức SQL Server có thể ước tính số lượng (Shelf, Bin) riêng biệt như thế nào kết hợp cho GROUP BY Shelf, Bin của chúng tôi truy vấn. Đặt câu hỏi theo một cách hơi khác:Cho 21 kệ và 62 thùng, sẽ có bao nhiêu sự kết hợp kệ và thùng độc đáo? Bỏ qua các khía cạnh vật lý và kiến thức khác của con người về miền vấn đề, câu trả lời có thể nằm ở bất kỳ đâu từ max (21, 62) =62 đến (21 * 62) =1,302. Nếu không có thêm thông tin, không có cách nào rõ ràng để biết nơi đưa ra một ước tính trong phạm vi đó.
Tuy nhiên, đối với truy vấn mẫu của chúng tôi, SQL Server ước tính 744.312 hàng (làm tròn thành 744 trong dạng xem Plan Explorer) nhưng dựa trên cơ sở nào?
Sự kiện mở rộng ước tính bản số
Cách được tài liệu hóa để xem xét quy trình ước tính bản số là sử dụng Sự kiện mở rộng query_optimizer_estimate_cardinality (mặc dù nó đang ở trong kênh "gỡ lỗi"). Trong khi một phiên thu thập sự kiện này đang chạy, các toán tử kế hoạch thực thi có được một thuộc tính bổ sung StatsCollectionId liên kết các ước tính của nhà điều hành riêng lẻ với các phép tính tạo ra chúng. Đối với truy vấn ví dụ của chúng tôi, id bộ sưu tập thống kê 2 được liên kết với ước tính bản số cho nhóm bằng toán tử tổng hợp.
Đầu ra có liên quan từ Sự kiện mở rộng cho truy vấn thử nghiệm của chúng tôi là:
<data name="calculator">
<type name="xml" package="package0"></type>
<value>
<CalculatorList>
<DistinctCountCalculator CalculatorName="CDVCPlanLeaf" SingleColumnStat="Shelf,Bin" />
</CalculatorList>
</value>
</data>
<data name="stats_collection">
<type name="xml" package="package0"></type>
<value>
<StatsCollection Name="CStCollGroupBy" Id="2" Card="744.31">
<LoadedStats>
<StatsInfo DbId="6" ObjectId="258099960" StatsId="3" />
<StatsInfo DbId="6" ObjectId="258099960" StatsId="4" />
</LoadedStats>
</StatsCollection>
</value>
</data> Chắc chắn có một số thông tin hữu ích ở đó.
Chúng ta có thể thấy rằng kế hoạch để lại các giá trị riêng biệt của lớp máy tính (CDVCPlanLeaf ) đã được sử dụng, sử dụng thống kê cột đơn trên Shelf và Bin làm đầu vào. Phần tử thu thập số liệu thống kê khớp với phân đoạn này với id (2) được hiển thị trong kế hoạch thực thi, cho thấy ước tính về số lượng của 744.31 và thêm thông tin về id đối tượng thống kê cũng được sử dụng.
Thật không may, không có gì trong kết quả sự kiện để nói chính xác cách máy tính đưa ra con số cuối cùng, đó là điều chúng tôi thực sự quan tâm.
Kết hợp các số lượng riêng biệt
Đi theo một lộ trình ít tài liệu hơn, chúng tôi có thể yêu cầu một kế hoạch ước tính cho truy vấn với các cờ theo dõi 2363 và 3604 được bật:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin
OPTION (QUERYTRACEON 3604, QUERYTRACEON 2363); Thao tác này trả về thông tin gỡ lỗi cho tab Thông báo trong SQL Server Management Studio. Phần thú vị được tái hiện dưới đây:
Begin distinct values computation
Input tree:
LogOp_GbAgg OUT(QCOL: [INV].Shelf,QCOL: [INV].Bin,COL: Expr1001 ,) BY(QCOL: [INV].Shelf,QCOL: [INV].Bin,)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=0)
Plan for computation:
CDVCPlanLeaf
0 Multi-Column Stats, 2 Single-Column Stats, 0 Guesses
Loaded histogram for column QCOL: [INV].Shelf from stats with id 3
Loaded histogram for column QCOL: [INV].Bin from stats with id 4
Using ambient cardinality 1069 to combine distinct counts:
21
62
Combined distinct count: 744.312
Result of computation: 744.312
Stats collection generated:
CStCollGroupBy(ID=2, CARD=744.312)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
End distinct values computation Điều này hiển thị nhiều thông tin giống như Sự kiện mở rộng đã làm ở định dạng (được cho là) dễ sử dụng hơn:
- Toán tử quan hệ đầu vào để tính toán ước tính bản số cho (
LogOp_GbAgg- nhóm logic theo tổng hợp) - Máy tính được sử dụng (
CDVCPlanLeaf) và thống kê đầu vào - Chi tiết thu thập thống kê kết quả
Phần thông tin mới thú vị là phần về việc sử dụng tính chất môi trường xung quanh để kết hợp các số lượng riêng biệt .
Điều này cho thấy rõ ràng rằng các giá trị 21, 62 và 1069 đã được sử dụng, nhưng (thật khó chịu) vẫn không chính xác các phép tính nào đã được thực hiện để đi đến 744.312 kết quả.
Tới Trình gỡ lỗi!
Việc đính kèm trình gỡ lỗi và sử dụng các ký hiệu công khai cho phép chúng tôi khám phá chi tiết đường dẫn mã được theo sau trong khi biên dịch truy vấn mẫu.
Ảnh chụp nhanh bên dưới cho thấy phần trên của ngăn xếp cuộc gọi tại một điểm đại diện trong quy trình:
MSVCR120!log sqllang!OdblNHlogN sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement sqllang!CCardUtilSQL12::CardDistinctMunged sqllang!CCardUtilSQL12::CardDistinctCombined sqllang!CStCollAbstractLeaf::CardDistinctImpl sqllang!IStatsCollection::CardDistinct sqllang!CCardUtilSQL12::CardGroupByHelperCore sqllang!CCardUtilSQL12::PstcollGroupByHelper sqllang!CLogOp_GbAgg::PstcollDeriveCardinality sqllang!CCardFrameworkSQL12::DeriveCardinalityProperties
Có một vài chi tiết thú vị ở đây. Làm việc từ dưới lên, chúng tôi thấy rằng cardinality đang được lấy bằng CE đã cập nhật (CCardFrameworkSQL12 ) khả dụng trong SQL Server 2014 trở lên (CE gốc là CCardFrameworkSQL7 ), cho nhóm theo toán tử logic tổng hợp (CLogOp_GbAgg ).
Tính toán bản số riêng biệt bao gồm việc kết hợp (trộn) nhiều đầu vào, sử dụng lấy mẫu mà không cần thay thế.
Tham chiếu đến H và một logarit (tự nhiên) trong phương pháp thứ hai từ trên xuống cho thấy việc sử dụng Shannon Entropy trong tính toán:
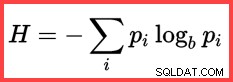
Shannon Entropy
Entropy có thể được sử dụng để ước tính mối tương quan thông tin (thông tin lẫn nhau) giữa hai thống kê:
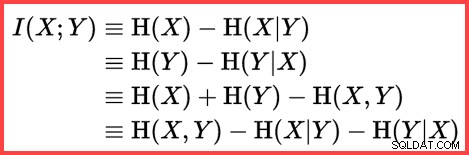
Thông tin lẫn nhau
Kết hợp tất cả những điều này lại với nhau, chúng ta có thể tạo một tập lệnh tính toán T-SQL phù hợp với cách SQL Server sử dụng lấy mẫu mà không cần thay thế, Shannon Entropy và thông tin lẫn nhau để tạo ra ước tính số lượng cuối cùng.
Chúng tôi bắt đầu với các số đầu vào (số lượng môi trường xung quanh và số lượng các giá trị riêng biệt trong mỗi cột):
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62; Tần suất của mỗi cột là số hàng trung bình cho mỗi giá trị riêng biệt:
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2; Lấy mẫu mà không cần thay thế (SWR) là một vấn đề đơn giản trừ số hàng trung bình cho mỗi giá trị riêng biệt (tần suất) từ tổng số hàng:
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2; Tính toán entropies (N log N) và thông tin lẫn nhau:
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Using logarithms allows us to express
-- multiplication as addition and division as subtraction
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4); Bây giờ chúng tôi đã ước tính mức độ tương quan của hai bộ thống kê, chúng tôi có thể tính toán ước tính cuối cùng:
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2;
Kết quả của phép tính là 744.311823994677, là 744.312 làm tròn đến ba chữ số thập phân.
Để thuận tiện, đây là toàn bộ mã trong một khối:
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62;
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2;
-- Sample without replacement
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2;
-- Entropy
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Mutual information
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4);
-- Final estimate
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2; Lời kết
Ước tính cuối cùng không hoàn hảo trong trường hợp này - truy vấn mẫu thực sự trả về 441 hàng.
Để có được ước tính được cải thiện, chúng tôi có thể cung cấp cho trình tối ưu hóa thông tin tốt hơn về mật độ của Bin và Shelf sử dụng thống kê nhiều cột. Ví dụ:
CREATE STATISTICS stat_Shelf_Bin ON Production.ProductInventory (Shelf, Bin);
Với thống kê đó tại chỗ (như đã cho, hoặc là một tác dụng phụ của việc thêm một chỉ mục nhiều cột tương tự), ước tính bản số cho truy vấn ví dụ là chính xác. Tuy nhiên, hiếm khi tính được một tổng hợp đơn giản như vậy. Với các vị từ bổ sung, thống kê nhiều cột có thể kém hiệu quả hơn. Tuy nhiên, điều quan trọng cần nhớ là thông tin mật độ bổ sung được cung cấp bởi thống kê đa cột có thể hữu ích cho việc tổng hợp (cũng như so sánh bình đẳng).
Nếu không có thống kê nhiều cột, một truy vấn tổng hợp với các vị từ bổ sung vẫn có thể sử dụng logic thiết yếu được hiển thị trong bài viết này. Ví dụ:thay vì áp dụng công thức cho số lượng bảng, nó có thể được áp dụng cho các biểu đồ đầu vào từng bước một.
Nội dung liên quan:Ước tính số lượng cho một vị từ trên một biểu thức COUNT