Giới thiệu
Trong SQL Server 2012, tổng hợp theo nhóm (vectơ) có thể sử dụng thực thi chế độ hàng loạt song song, nhưng chỉ cho tổng hợp một phần (mỗi luồng). Tổng hợp toàn cầu được liên kết luôn chạy ở chế độ hàng, sau Luồng phân vùng lại trao đổi.
SQL Server 2014 đã thêm khả năng thực hiện tổng hợp nhóm theo chế độ hàng loạt song song trong một Tổng hợp kết hợp băm duy nhất nhà điều hành. Điều này đã loại bỏ quá trình xử lý chế độ hàng không cần thiết và loại bỏ nhu cầu trao đổi.
SQL Server 2016 đã giới thiệu xử lý chế độ hàng loạt nối tiếp và tổng hợp đẩy xuống . Khi kéo xuống thành công, việc tổng hợp được thực hiện trong Columnstore Scan chính nhà điều hành, có thể hoạt động trực tiếp trên dữ liệu nén và tận dụng các hướng dẫn của SIMD CPU.
Các cải tiến hiệu suất có thể có với tổng hợp đẩy xuống có thể rất đáng kể. Tài liệu liệt kê một số điều kiện cần thiết để đạt được tính năng đẩy xuống, nhưng có những trường hợp thiếu "hàng tổng hợp cục bộ" không thể giải thích đầy đủ chỉ từ những chi tiết đó.
Bài viết này đề cập đến các yếu tố bổ sung ảnh hưởng đến tổng hợp kéo xuống cho GROUP BY chỉ truy vấn . Đẩy xuống tổng hợp vô hướng (tổng hợp không có GROUP BY mệnh đề), bộ lọc đẩy xuống và biểu thức kéo xuống có thể được đề cập trong một bài đăng trong tương lai.
Bộ nhớ Columnstore
Điều đầu tiên cần nói là tổng hợp kéo xuống chỉ áp dụng cho dữ liệu nén, vì vậy các hàng trong cửa hàng delta không đủ điều kiện. Ngoài ra, quá trình đẩy xuống có thể phụ thuộc vào loại nén được sử dụng. Để hiểu điều này, trước tiên cần phải xem lại cách hoạt động của bộ lưu trữ columnstore ở cấp độ cao:
Một nhóm hàng được nén chứa phân đoạn cột cho mỗi cột. Các giá trị cột thô được mã hóa ở dạng số nguyên 4 byte hoặc 8 byte sử dụng giá trị hoặc từ điển mã hóa.
Mã hóa giá trị có thể giảm số lượng bit cần thiết để lưu trữ bằng cách dịch các giá trị thô bằng cách sử dụng bộ điều chỉnh độ lớn và độ lệch cơ sở. Ví dụ:các giá trị {1100, 1200, 1300} có thể được lưu trữ dưới dạng (0, 1, 2) bằng cách chia tỷ lệ đầu tiên theo hệ số 0,01 để cho {11, 12, 13}, sau đó giảm lại ở 11 để cho {0, 1, 2}.
Mã hóa từ điển được sử dụng khi có các giá trị trùng lặp. Nó có thể được sử dụng với dữ liệu không phải số. Mỗi giá trị duy nhất được lưu trữ trong từ điển và được gán một id số nguyên. Sau đó, dữ liệu phân đoạn sẽ tham chiếu đến các số id trong từ điển thay vì các giá trị ban đầu.
Sau khi mã hóa, dữ liệu phân đoạn có thể được nén thêm bằng cách sử dụng mã hóa thời lượng chạy (RLE) và đóng gói bit:
RLE thay thế các phần tử lặp lại bằng dữ liệu và số lần lặp lại, ví dụ:{1, 1, 1, 1, 1, 2, 2, 2} có thể được thay thế bằng {5 × 1, 3 × 2}. Tiết kiệm không gian RLE tăng lên theo độ dài của các lần chạy lặp lại. Chạy ngắn có thể phản tác dụng.
Đóng gói bit lưu trữ dạng nhị phân của dữ liệu trong một cửa sổ chung càng hẹp càng tốt. Ví dụ:các số {7, 9, 15} được lưu trữ dưới dạng số nguyên nhị phân (byte đơn cho khoảng trắng) là {00000111, 00001001, 00001111}. Việc đóng gói các bit này vào một cửa sổ bốn bit cố định sẽ cho luồng {011110011111}. Biết có kích thước cửa sổ cố định có nghĩa là không cần dấu phân cách.
Mã hóa và nén là các bước riêng biệt, vì vậy RLE và đóng gói bit được áp dụng cho kết quả của mã hóa giá trị hoặc mã hóa từ điển dữ liệu thô. Hơn nữa, dữ liệu trong cùng một phân đoạn cột có thể có hỗn hợp của RLE và nén đóng gói bit. Dữ liệu nén RLE được gọi là nguyên chất và dữ liệu nén được đóng gói theo bit được gọi là không tinh khiết . Một phân đoạn cột có thể chứa cả dữ liệu thuần túy và không tinh khiết.
Tiết kiệm không gian có thể đạt được thông qua mã hóa và nén có thể phụ thuộc vào thứ tự. Tất cả các phân đoạn cột trong một nhóm hàng phải được sắp xếp ngầm theo cùng một cách để SQL Server có thể cấu trúc lại các hàng hoàn chỉnh từ các phân đoạn cột một cách hiệu quả. Biết rằng hàng 123 được lưu trữ ở cùng một vị trí (123) trong mỗi đoạn cột có nghĩa là số hàng không phải được lưu trữ.
Một nhược điểm của cách sắp xếp này là thứ tự sắp xếp phổ biến phải được chọn cho tất cả các phân đoạn cột trong một nhóm hàng. Một thứ tự cụ thể có thể rất phù hợp với một cột, nhưng lại bỏ lỡ các cơ hội quan trọng trong các cột khác. Đây là trường hợp rõ ràng nhất với nén RLE. SQL Server sử dụng công nghệ Vertipaq để xác định cách sắp xếp tốt các cột trong mỗi nhóm hàng nhằm mang lại kết quả nén tổng thể tốt.
SQL Server hiện chỉ sử dụng RLE trong một phân đoạn cột khi có tối thiểu là 64 các giá trị lặp liền nhau. Các giá trị còn lại trong phân đoạn được đóng gói bit. Như đã lưu ý, việc các giá trị lặp lại có xuất hiện liền nhau trong một phân đoạn cột hay không phụ thuộc vào thứ tự được chọn cho nhóm hàng.
SQL Server hỗ trợ SIMD chuyên biệt giải nén bit cho các độ rộng bit từ 1 đến 10 bao gồm, 12 và 21 bit. SQL Server cũng có thể sử dụng kích thước số nguyên tiêu chuẩn, ví dụ:16, 32 và 64 bit với tính năng đóng gói bit. Những con số này được chọn vì chúng vừa vặn trong một đơn vị 64-bit. Ví dụ, một đơn vị có thể chứa ba đơn vị con 21 bit hoặc 5 đơn vị con 12 bit. SQL Server không vượt qua ranh giới 64 bit khi đóng gói các bit.
SIMD sử dụng thanh ghi 256-bit khi bộ xử lý hỗ trợ các lệnh AVX2 và thanh ghi 128-bit khi có các lệnh SSE4.2. Nếu không, bạn có thể sử dụng tính năng giải nén không phải SIMD.
Điều kiện đẩy xuống tổng hợp được nhóm
Hầu hết các kế hoạch có Hash Match Aggregate toán tử ngay trên Columnstore Scan nhà điều hành sẽ có khả năng đủ điều kiện cho việc đẩy xuống tổng hợp được nhóm theo các điều kiện chung được lưu ý trong tài liệu.
Các bộ lọc và biểu thức bổ sung đôi khi cũng có thể được thêm vào mà không cản trở việc đẩy xuống tổng hợp được nhóm lại. Quy tắc chung là bộ lọc hoặc biểu thức cũng phải có khả năng đẩy xuống (mặc dù các biểu thức tương thích vẫn có thể xuất hiện trong một Tính vô hướng riêng biệt ). Như đã lưu ý trong phần giới thiệu, những khía cạnh này có thể được đề cập chi tiết trong các bài viết riêng biệt.
Hiện không có gì trong kế hoạch thực thi để chỉ ra liệu một tổng hợp cụ thể có được coi là tương thích chung hay không có đẩy xuống tổng hợp được nhóm hoặc không. Tuy nhiên, khi kế hoạch thường đủ điều kiện đối với quảng cáo kéo xuống tổng hợp được nhóm lại, cả đường dẫn mã kéo xuống (nhanh) và không đẩy xuống (chậm) đều có sẵn.
Mỗi lô đầu ra quét (lên đến 900 hàng) đưa ra một quyết định về thời gian chạy giữa các đường dẫn mã nhanh và chậm. Tính linh hoạt này cho phép càng nhiều lô càng tốt để hưởng lợi từ việc đẩy xuống. Trong trường hợp xấu nhất, sẽ không có lô nào sử dụng đường dẫn nhanh trong thời gian chạy, mặc dù có gói "tương thích chung".
Kế hoạch thực thi hiển thị kết quả của quá trình xử lý đường dẫn nhanh kéo xuống dưới dạng ‘các hàng được tổng hợp cục bộ’ không có đầu ra hàng tương ứng từ quá trình quét. Các lô đường dẫn chậm xuất hiện dưới dạng các hàng đầu ra từ quá trình quét tại kho cột như bình thường, với việc tổng hợp được thực hiện bởi một nhà điều hành riêng biệt thay vì tại quá trình quét.
Một kết hợp tổng hợp và quét được nhóm được nhóm đơn lẻ có thể gửi một số lô theo đường dẫn nhanh và một số theo đường dẫn chậm, vì vậy hoàn toàn có thể thấy một số, nhưng không phải tất cả, hàng được tổng hợp cục bộ. Khi đẩy xuống tổng hợp được nhóm thành công, mỗi lô đầu ra từ quá trình quét chứa các khóa nhóm và tổng hợp một phần đại diện cho các hàng đóng góp.
Kiểm tra chi tiết
Có một số kiểm tra thời gian chạy để xác định xem có thể sử dụng xử lý đẩy xuống hay không. Trong số các kiểm tra được lập thành văn bản là:
- Không được có khả năng xảy ra tràn tổng hợp .
- Bất kỳ không tinh khiết nào (đóng gói bit) khóa nhóm phải không rộng hơn 10 bit . Các khóa nhóm thuần túy (được mã hóa RLE) được coi là có độ rộng không tinh khiết bằng 0, vì vậy, những khóa này thường gây ra một số trở ngại.
- Quá trình xử lý kéo xuống phải tiếp tục được coi là đáng giá , sử dụng "thước đo lợi ích" được cập nhật vào cuối mỗi lô sản phẩm.
Khả năng xảy ra tràn tổng hợp được đánh giá thận trọng cho từng lô dựa trên kiểu tổng hợp, kiểu dữ liệu kết quả, các giá trị tổng hợp từng phần hiện tại và thông tin về dữ liệu đầu vào. Ví dụ:SQL Server biết các giá trị tối thiểu và tối đa từ siêu dữ liệu phân đoạn như được hiển thị trong DMV sys.column_store_segments . Ở những nơi có nguy cơ bị tràn, lô sẽ sử dụng xử lý đường dẫn chậm. Đây chủ yếu là rủi ro đối với SUM tổng hợp.
Hạn chế về chiều rộng khóa nhóm không tinh khiết rất đáng được nhấn mạnh. Nó chỉ áp dụng cho các cột trong GROUP BY mệnh đề thực sự được sử dụng trong kế hoạch thực hiện làm cơ sở để phân nhóm. Các tập hợp này không phải lúc nào cũng hoàn toàn giống nhau vì trình tối ưu hóa có quyền tự do loại bỏ các cột nhóm thừa hoặc viết lại các tập hợp, miễn là kết quả truy vấn cuối cùng được đảm bảo khớp với đặc tả truy vấn ban đầu. Nếu có sự khác biệt, thì việc nhóm các cột được hiển thị trong kế hoạch thực thi mới là vấn đề quan trọng.
Khó khăn lớn hơn là biết liệu bất kỳ cột nhóm nào được lưu trữ bằng cách sử dụng tính năng đóng gói bit hay không, và nếu có, chiều rộng nào đã được sử dụng. Nó cũng sẽ hữu ích nếu biết có bao nhiêu giá trị được mã hóa bằng RLE. Thông tin này có thể nằm trong column_store_segments DMV, nhưng đó không phải là trường hợp ngày nay. Theo như tôi biết, hiện tại không có cách nào được lập thành văn bản để lấy thông tin đóng gói bit và RLE từ siêu dữ liệu. Điều đó khiến chúng tôi phải tìm kiếm các lựa chọn thay thế không có giấy tờ.
Tìm thông tin RLE và đóng gói bit
DBCC CSINDEX không có giấy tờ có thể cung cấp cho chúng tôi thông tin chúng tôi cần. Cờ theo dõi 3604 cần được bật để lệnh này tạo ra đầu ra trong tab thông báo SSMS. Cung cấp thông tin về phân đoạn cột mà chúng tôi quan tâm, lệnh này trả về:
- Thuộc tính phân đoạn (tương tự như
column_store_segments) - Thông tin RLE
- Đánh dấu vào dữ liệu RLE
- Thông tin về gói bit
Không có tài liệu, có một vài điều kỳ quặc (chẳng hạn như phải thêm một vào id cột cho kho cột nhóm, nhưng không phải cửa hàng cột không hợp nhất), và thậm chí là một vài lỗi nhỏ. Bạn không nên sử dụng nó trên bất cứ thứ gì ngoại trừ hệ thống kiểm tra cá nhân. Hy vọng rằng một ngày nào đó, một phương pháp được hỗ trợ để truy cập vào dữ liệu này sẽ được cung cấp thay thế.
Ví dụ
Cách tốt nhất để hiển thị DBCC CSINDEX và chứng minh những điểm được thực hiện cho đến nay trong văn bản này là làm việc thông qua một số ví dụ. Các tập lệnh theo sau giả sử có một bảng được gọi là dbo.Numbers trong cơ sở dữ liệu hiện tại có chứa các số nguyên từ 1 đến ít nhất là 16,384. Đây là tập lệnh để tạo phiên bản tiêu chuẩn của bảng này với mười triệu số nguyên:
IF OBJECT_ID(N'dbo.Numbers', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Numbers;
END;
GO
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1
)
SELECT
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten AS T10
CROSS JOIN Ten AS T100
CROSS JOIN Ten AS T1000
CROSS JOIN Ten AS T10000
CROSS JOIN Ten AS T100000
CROSS JOIN Ten AS T1000000
CROSS JOIN Ten AS T10000000
ORDER BY n
OFFSET 0 ROWS
FETCH FIRST 10 * 1000 * 1000 ROWS ONLY
OPTION
(MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT [PK dbo.Numbers n]
PRIMARY KEY CLUSTERED (n)
WITH
(
SORT_IN_TEMPDB = ON,
MAXDOP = 1,
FILLFACTOR = 100
);
Tất cả các ví dụ đều sử dụng cùng một bảng kiểm tra cơ bản:Cột đầu tiên c1 chứa một số duy nhất cho mỗi hàng. Cột thứ hai c2 được điền với một số bản sao cho mỗi một số lượng nhỏ các giá trị riêng biệt.
Chỉ mục lưu trữ cột theo cụm được tạo sau tập hợp dữ liệu để tất cả dữ liệu thử nghiệm kết thúc trong một nhóm hàng nén duy nhất (không có lưu trữ delta). Nó được xây dựng để thay thế chỉ mục nhóm b-tree trên cột c2 để khuyến khích thuật toán VertiPaq xem xét tính hữu ích của việc sắp xếp trên cột đó ngay từ đầu. Đây là thiết lập thử nghiệm cơ bản:
USE Sandpit;
GO
DROP TABLE IF EXISTS dbo.Test;
GO
CREATE TABLE dbo.Test
(
c1 integer NOT NULL,
c2 integer NOT NULL
);
GO
DECLARE
@values integer = 512,
@dupes integer = 63;
INSERT dbo.Test
(c1, c2)
SELECT
N.n,
N.n % @values
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND @values * @dupes;
GO
-- Encourage VertiPaq
CREATE CLUSTERED INDEX CCSI ON dbo.Test (c2);
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCSI
ON dbo.Test
WITH (MAXDOP = 1, DROP_EXISTING = ON);
Hai biến dành cho số lượng giá trị khác biệt để chèn vào cột c2 và số lượng bản sao cho mỗi giá trị đó.
Truy vấn kiểm tra là một COUNT_BIG được nhóm rất đơn giản tổng hợp bằng cách sử dụng cột c2 là chìa khóa:
-- The test query
SELECT
T.c2,
numrows = COUNT_BIG(*)
FROM dbo.Test AS T
GROUP BY
T.c2;
Thông tin chỉ mục Columnstore sẽ được hiển thị bằng DBCC CSINDEX sau mỗi lần thực thi truy vấn thử nghiệm:
DECLARE
@dbname sysname = DB_NAME(),
@objectid integer = OBJECT_ID(N'dbo.Test', N'U');
DECLARE
@rowsetid bigint =
(
SELECT
P.hobt_id
FROM sys.partitions AS P
WHERE
P.[object_id] = @objectid
AND P.index_id = 1
AND P.partition_number = 1
),
@rowgroupid integer = 0,
@columnid integer =
COLUMNPROPERTY(@objectid, N'c2', 'ColumnId') + 1;
DBCC CSINDEX
(
@dbname,
@rowsetid,
@columnid,
@rowgroupid,
1, -- show segment data
2, -- print option
0, -- start bitpack unit (inclusive)
2 -- end bitpack unit (exclusive)
); Các thử nghiệm đã được chạy trên phiên bản SQL Server được phát hành mới nhất có sẵn tại thời điểm viết bài:Microsoft SQL Server 2017 RTM-CU13-OD bản dựng 14.0.3049 Phiên bản dành cho nhà phát triển (64-bit) trên Windows 10 Pro. Mọi thứ cũng sẽ hoạt động tốt trên phiên bản mới nhất của SQL Server 2016.
Kiểm tra 1:Kéo xuống, Khóa 9 bit không tinh khiết
Thử nghiệm này sử dụng tập lệnh tổng hợp dữ liệu thử nghiệm chính xác như đã viết ở trên, tạo ra một bảng có 32,256 hàng. Cột c1 chứa các số từ 1 đến 32,256.
Cột c2 chứa 512 giá trị riêng biệt từ 0 đến 511. Mỗi giá trị trong c2 được sao chép 63 lần , nhưng chúng không xuất hiện dưới dạng các khối liền kề khi được xem trong c1 gọi món; chúng quay vòng 63 lần qua các giá trị từ 0 đến 511.
Với cuộc thảo luận ở trên, chúng tôi mong đợi SQL Server lưu trữ c2 dữ liệu cột sử dụng:
- Mã hóa từ điển vì có một số lượng đáng kể các giá trị trùng lặp.
- Không RLE . Số lượng bản sao (63) trên mỗi giá trị không đạt đến ngưỡng 64 bắt buộc đối với RLE.
- Kích thước đóng gói bit 9 . 512 mục từ điển riêng biệt sẽ khớp chính xác trong 9 bit (2 ^ 9 =512). Mỗi đơn vị 64 bit sẽ chứa tối đa bảy đơn vị con 9 bit.
Tất cả điều này được xác nhận là chính xác bằng cách sử dụng DBCC CSINDEX truy vấn:
Thuộc tính phân đoạn phần đầu ra hiển thị mã hóa từ điển (loại 2; các giá trị cho encodingType như được ghi lại tại sys.column_store_segments ).
Phiên bản =1 encodingType =2 hasNulls =0
BaseId =-1 Độ lớn =-1.000000e + 000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =511
NullValue =-1 OnDiskSize =37944 RowCount =32256
Phần RLE hiển thị không có dữ liệu RLE , chỉ một con trỏ đến vùng đóng gói bit và một mục nhập trống cho giá trị 0:
Tiêu đề RLE:
Lob type =3 RLE Array Count (Theo đơn vị gốc) =2
RLE Array Entry Size =8
RLE Data:
Index =0 Bitpack Array Index =0 Count =32256
Index =1 Value =0 Count =0
Tiêu đề dữ liệu Bitpack phần hiển thị kích thước gói bit 9 và 4.608 đơn vị gói bit được sử dụng:
Tiêu đề dữ liệu Bitpack:
Kích thước mục nhập Bitpack =9 Bitpack Unit Count =4608 Bitpack MinId =3
Bitpack DataSize =36864
Dữ liệu Bitpack phần hiển thị các giá trị được lưu trữ trong hai đơn vị bitpack đầu tiên theo yêu cầu của hai tham số cuối cùng với DBCC CSINDEX yêu cầu. Nhớ lại rằng mỗi đơn vị 64 bit có thể chứa 7 đơn vị con (được đánh số từ 0 đến 6), mỗi đơn vị 9 bit (7 x 9 =63 bit). Tổng thể 4.608 đơn vị chứa 4.608 * 7 =32.256 hàng:
Đơn vị 0 Đơn vị con 0 =383
Đơn vị 0 Đơn vị con 1 =255
Đơn vị 0 Đơn vị con 2 =127
Đơn vị 0 Đơn vị con 3 =510
Đơn vị 0 Đơn vị con 4 =381
Đơn vị 0 Đơn vị con 5 =253
Đơn vị 0 Đơn vị con 6 =125
Đơn vị 1 Đơn vị con 0 =508
Đơn vị 1 Đơn vị con 1 =379
Đơn vị 1 Đơn vị con 2 =251
Đơn vị 1 Đơn vị con 3 =123
Đơn vị 1 Đơn vị con 4 =506
Đơn vị 1 Đơn vị con 5 =377
Đơn vị 1 Đơn vị con 6 =249
Vì các khóa nhóm sử dụng đóng gói bit có kích thước nhỏ hơn hoặc bằng 10 , chúng tôi mong đợi quảng cáo kéo xuống tổng hợp được nhóm theo nhóm để làm việc ở đây. Thật vậy, kế hoạch thực thi cho thấy tất cả các hàng đã được tổng hợp cục bộ tại Columnstore Index Scan nhà điều hành:

Kế hoạch xml chứa ActualLocallyAggregatedRows="32256" trong thông tin thời gian chạy để quét chỉ mục.
Kiểm tra 2:Không có phím kéo xuống, 12-bit không tinh khiết Keys
Kiểm tra này thay đổi @values tham số thành 1025, giữ @dupes ở 63. Điều này cung cấp một bảng gồm 64,575 hàng, với 1,025 giá trị khác biệt trong cột c2 chạy từ 0 đến 1024. Mỗi giá trị trong c2 được sao chép 63 lần .
SQL Server lưu trữ c2 dữ liệu cột sử dụng:
- Mã hóa từ điển vì có một số lượng đáng kể các giá trị trùng lặp.
- Không RLE . Số lượng bản sao (63) trên mỗi giá trị không đạt đến ngưỡng 64 bắt buộc đối với RLE.
- Được đóng gói bit với kích thước 12 . 1.025 mục từ điển riêng biệt sẽ không hoàn toàn phù hợp với 10 bit (2 ^ 10 =1.024). Chúng sẽ vừa với 11 bit nhưng SQL Server không hỗ trợ kích thước đóng gói bit đó như đã đề cập trước đây. Kích thước nhỏ nhất tiếp theo là 12 bit. Sử dụng các đơn vị 64 bit có đường viền cứng để đóng gói bit, không có đơn vị con 11 bit nào có thể vừa với 64 bit hơn đơn vị con 12 bit. Dù bằng cách nào, 5 đơn vị con sẽ phù hợp với một đơn vị 64 bit.
DBCC CSINDEX đầu ra xác nhận phân tích trên:
Phiên bản =1 encodingType =2 hasNulls =0
BaseId =-1 Độ lớn =-1.000000e + 000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024
NullValue =-1 OnDiskSize =104400 RowCount =64575
Tiêu đề RLE:
Lob type =3 RLE Array Count (Theo đơn vị gốc) =2
RLE Array Entry Size =8
Dữ liệu RLE:
Index =0 Bitpack Array Index =0 Count =64575
Index =1 Value =0 Count =0
Tiêu đề dữ liệu Bitpack:
Kích thước mục nhập Bitpack =12 Bitpack Unit Count =12915 Bitpack MinId =3
Bitpack DataSize =103320
Bitpack Data:
Đơn vị 0 Đơn vị con 0 =767
Đơn vị 0 Đơn vị con 1 =510
Đơn vị 0 Đơn vị con 2 =254
Đơn vị 0 Đơn vị con 3 =1021
Đơn vị 0 Đơn vị con 4 =765
Đơn vị 1 Đơn vị con 0 =507
Đơn vị 1 Đơn vị con 1 =250
Đơn vị 1 Đơn vị con 2 =1019
Đơn vị 1 Đơn vị con 3 =761
Đơn vị 1 Đơn vị con 4 =505
Vì không tinh khiết các khóa nhóm có kích thước trên 10 , chúng tôi mong đợi quảng cáo kéo xuống tổng hợp được nhóm theo nhóm không làm việc đây. Điều này được xác nhận bởi kế hoạch thực thi hiển thị không có hàng nào được tổng hợp cục bộ tại Quét chỉ mục Columnstore nhà điều hành:
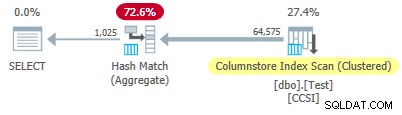
Tất cả 64.575 hàng được phát ra (theo lô) bởi Columnstore Index Scan và được tổng hợp ở chế độ hàng loạt bởi Hash Match Aggregate nhà điều hành. ActualLocallyAggregatedRows thuộc tính bị thiếu trong thông tin thời gian chạy kế hoạch xml để quét chỉ mục.
Kiểm tra 3:Kéo xuống, Phím thuần
Kiểm tra này thay đổi @dupes tham số từ 63 đến 64 để cho phép RLE. @values tham số được thay đổi thành 16,384 (tối đa để tổng số hàng vẫn phù hợp trong một nhóm hàng). Số chính xác được chọn cho @values không quan trọng - vấn đề là tạo 64 bản sao của mỗi giá trị duy nhất để RLE có thể được sử dụng.
SQL Server lưu trữ c2 dữ liệu cột sử dụng:
- Mã hóa từ điển do các giá trị trùng lặp.
- RLE. Được sử dụng cho mọi giá trị khác nhau vì mỗi giá trị đáp ứng ngưỡng 64.
- Không có dữ liệu được đóng gói theo bit . Nếu có, nó sẽ sử dụng kích thước 16. Kích thước 12 không đủ lớn (2 ^ 12 =4.096 giá trị khác biệt) và kích thước 21 sẽ lãng phí. 16.384 giá trị khác biệt sẽ phù hợp với 14 bit nhưng như trước đây, không có giá trị nào trong số này có thể phù hợp với đơn vị 64 bit hơn đơn vị con 16 bit.
DBCC CSINDEX đầu ra xác nhận điều trên (chỉ một số mục nhập RLE và dấu trang được hiển thị vì lý do không gian):
Phiên bản =1 encodingType =2 hasNulls =0
BaseId =-1 Độ lớn =-1.000000e + 000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =16383
NullValue =-1 OnDiskSize =131648 RowCount =1048576
Tiêu đề RLE:
Lob type =3 RLE Array Count (Theo đơn vị gốc) =16385
RLE Array Entry Size =8
Dữ liệu RLE:
Chỉ số =0 Giá trị =3 Đếm =64
Chỉ số =1 Giá trị =1538 Đếm =64
Chỉ số =2 Giá trị =3072 Đếm =64
Chỉ số =3 Giá trị =4608 Đếm =64
/> Chỉ số =4 Giá trị =6142 Lượt =64
…
Chỉ số =16381 Giá trị =8954 Lượt =64
Chỉ số =16382 Giá trị =10489 Lượt =64
Chỉ số =16383 Giá trị =12025 Đếm =64
Chỉ số =16384 Giá trị =0 Đếm =0
Tiêu đề Dấu trang:
Số lượng Dấu trang =65 Khoảng cách Dấu trang =16384 Kích thước Dấu trang =520
Dữ liệu Dấu trang:
Vị trí =0 Chỉ số =64
Vị trí =512 Chỉ số =16448
Vị trí =1024 Chỉ số =32832
…
Vị trí =31744 Chỉ số =1015872
Vị trí =32256 Chỉ số =1032256
Vị trí =32768 Chỉ số =1048577
Tiêu đề dữ liệu Bitpack:
Kích thước mục nhập Bitpack =16 Bitpack Unit Count =0 Bitpack MinId =3
Bitpack DataSize =0
Vì các khóa nhóm là nguyên chất (RLE được sử dụng), quảng cáo kéo xuống tổng hợp được nhóm theo nhóm được mong đợi ở đây. Kế hoạch thực thi xác nhận điều này bằng cách hiển thị tất cả các hàng được tổng hợp cục bộ tại Quét chỉ mục Columnstore nhà điều hành:
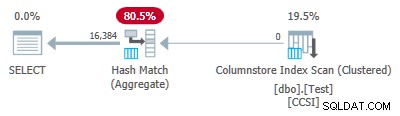
Kế hoạch xml chứa ActualLocallyAggregatedRows="1048576" trong thông tin thời gian chạy để quét chỉ mục.
Kiểm tra 4:Khóa 10 bit không tinh khiết
Thử nghiệm này đặt @values đến 1024 và @dupes đến 63, đưa ra một bảng gồm 64,512 hàng, với 1,024 giá trị khác biệt trong cột c2 với các giá trị từ 0 đến 1,023. Mỗi giá trị trong c2 được sao chép 63 lần .
Quan trọng nhất , chỉ mục nhóm b-tree hiện được tạo trên cột c1 thay vì cột c2 . Columnstore nhóm vẫn thay thế chỉ mục nhóm b-tree. Đây là phần đã thay đổi của tập lệnh:
-- Note column c1 now! CREATE CLUSTERED INDEX CCSI ON dbo.Test (c1); GO CREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.Test WITH (MAXDOP = 1, DROP_EXISTING = ON);
SQL Server lưu trữ c2 dữ liệu cột sử dụng:
- Mã hóa từ điển do các bản sao.
- Không RLE . Số lượng bản sao (63) trên mỗi giá trị không đạt đến ngưỡng 64 bắt buộc đối với RLE.
- Đóng gói bit với kích thước 10 . 1.024 mục từ điển riêng biệt khớp chính xác trong 10 bit (2 ^ 10 =1.024). Sáu đơn vị con 10 bit, mỗi đơn vị có thể được lưu trữ trong mỗi đơn vị 64 bit.
DBCC CSINDEX đầu ra là:
Phiên bản =1 encodingType =2 hasNulls =0
BaseId =-1 Độ lớn =-1.000000e + 000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023
NullValue =-1 OnDiskSize =87096 RowCount =64512
Tiêu đề RLE:
Lob type =3 RLE Array Count (Theo đơn vị gốc) =2
RLE Array Entry Size =8
Dữ liệu RLE:
Index =0 Bitpack Array Index =0 Count =64512
Index =1 Value =0 Count =0
Tiêu đề dữ liệu Bitpack:
Kích thước mục nhập Bitpack =10 Bitpack Unit Count =10752 Bitpack MinId =3
Bitpack DataSize =86016
Bitpack Data:
Đơn vị 0 Đơn vị con 0 =766
Đơn vị 0 Đơn vị con 1 =509
Đơn vị 0 Đơn vị con 2 =254
Đơn vị 0 Đơn vị con 3 =1020
Đơn vị 0 Đơn vị con 4 =764
Đơn vị 0 Đơn vị con 5 =506
Đơn vị 1 Đơn vị con 0 =250
Đơn vị 1 Đơn vị con 1 =1018
Đơn vị 1 Đơn vị con 2 =760
Đơn vị 1 Đơn vị con 3 =504
Đơn vị 1 Đơn vị con 4 =247
Đơn vị 1 Đơn vị con 5 =1014
Vì không tinh khiết các khóa nhóm sử dụng kích thước nhỏ hơn hoặc bằng 10, chúng tôi mong đợi đẩy xuống tổng hợp được nhóm lại để làm việc ở đây. Nhưng đó không phải là những gì sẽ xảy ra . Kế hoạch thực hiện cho thấy 54.612 trong số 64.512 hàng được tổng hợp tại Hash Match Aggregate nhà điều hành:
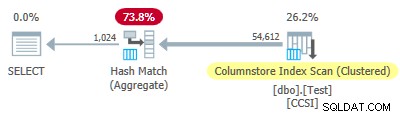
Kế hoạch xml chứa ActualLocallyAggregatedRows="9900" trong thông tin thời gian chạy để quét chỉ mục. Điều này có nghĩa là quảng cáo kéo xuống tổng hợp được nhóm theo nhóm đã được sử dụng cho 9,900 hàng, nhưng không được sử dụng cho 54,612 hàng khác!
Cơ chế phản hồi
SQL Server đã bắt đầu sử dụng đẩy xuống tổng hợp được nhóm theo nhóm cho việc thực thi này vì các khóa nhóm không tinh khiết đáp ứng tiêu chí 10 bit trở xuống. Điều này kéo dài tổng cộng 11 đợt (mỗi đợt 900 hàng =tổng số 9,900 hàng). Tại thời điểm đó, một cơ chế phản hồi đo lường mức độ hiệu quả của quảng cáo đẩy xuống tổng hợp được nhóm theo nhóm quyết định rằng nó không hoạt động và đã tắt nó đi . Tất cả các lô còn lại đã được xử lý với tính năng kéo xuống bị tắt.
Phản hồi về cơ bản so sánh số lượng hàng được tổng hợp với số lượng nhóm được tạo ra. Nó bắt đầu với giá trị 100 và được điều chỉnh vào cuối mỗi lô đầu ra đẩy xuống. Nếu giá trị giảm xuống 10 hoặc thấp hơn, thì chức năng kéo xuống sẽ bị tắt đối với thao tác nhóm hiện tại.
‘Biện pháp lợi ích đẩy xuống’ bị giảm đi nhiều hay ít tùy thuộc vào mức độ tồi tệ của nỗ lực tổng hợp đẩy xuống. Nếu trung bình có ít hơn 8 hàng cho mỗi khóa nhóm trong lô đầu ra, giá trị lợi ích hiện tại sẽ giảm 22%. Nếu có nhiều hơn 8 nhưng ít hơn 16, chỉ số sẽ giảm 11%.
Mặt khác, nếu mọi thứ được cải thiện và 16 hàng trở lên trên mỗi khóa nhóm sau đó gặp phải cho một lô đầu ra, chỉ số sẽ được đặt lại thành 100 và tiếp tục được điều chỉnh khi quá trình quét tạo ra các lô tổng hợp một phần.
Dữ liệu trong thử nghiệm này được trình bày theo một thứ tự đặc biệt không hữu ích cho việc kéo xuống do chỉ mục nhóm b-cây ban đầu trên cột c1 . Khi được trình bày theo cách này, các giá trị trong cột c2 bắt đầu từ 0 và tăng dần 1 cho đến khi đạt 1,023, sau đó bắt đầu lại chu kỳ. 1.023 giá trị khác biệt là quá đủ để đảm bảo mỗi lô đầu ra 900 hàng chỉ chứa một hàng tổng hợp một phần cho mỗi khóa. Đây không phải là một trạng thái vui vẻ.
Nếu có 64 bản sao cho mỗi giá trị thay vì 63, SQL Server sẽ xem xét sắp xếp theo c2 trong khi xây dựng chỉ mục columnstore, và do đó đã tạo ra tính năng nén RLE. Như vậy, 22% quả phạt đền được thực hiện sau mỗi đợt. Bắt đầu từ 100 và sử dụng cùng một số học số nguyên làm tròn, chuỗi các giá trị chỉ số sẽ:
-- @metric := FLOOR(@metric * 0.78 + 0.5); -- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
Lô thứ mười một giảm chỉ số xuống 10 hoặc thấp hơn và chức năng đẩy xuống bị tắt. 11 lô gồm 900 hàng chiếm 9,900 hàng tổng hợp cục bộ được hiển thị trong kế hoạch thực thi.
Biến thể có 900 giá trị khác biệt
Hành vi tương tự có thể được nhìn thấy trong thử nghiệm 4 với ít nhất 901 giá trị khác biệt, giả sử các hàng được trình bày theo cùng một thứ tự không hữu ích.
Thay đổi @values tham số đến 900 trong khi giữ nguyên mọi thứ khác có ảnh hưởng đáng kể đến kế hoạch thực thi:
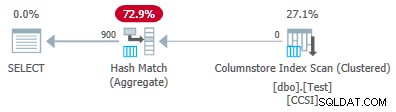
Bây giờ tất cả 900 nhóm được tổng hợp tại quá trình quét! Các thuộc tính kế hoạch xml hiển thị ActualLocallyAggregatedRows="56700" . Điều này bởi vì đẩy xuống tổng hợp được nhóm duy trì 900 khóa nhóm và tổng hợp một phần trong một lô duy nhất. Nó không bao giờ gặp phải một giá trị khóa mới không có trong lô, vì vậy không có lý do gì để bắt đầu một lô đầu ra mới.
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
Lưu ý: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.