Bạn đã bao giờ liên hệ với Microsoft hoặc đối tác của Microsoft và thảo luận với họ về chi phí chuyển sang đám mây chưa? Nếu vậy, bạn có thể đã nghe nói về máy tính DTU của Cơ sở dữ liệu Azure SQL và bạn cũng có thể đã đọc về cách nó được thiết kế ngược bởi Andy Mallon. Máy tính DTU là một công cụ miễn phí mà bạn có thể sử dụng để tải lên các chỉ số hiệu suất từ máy chủ của mình và sử dụng dữ liệu để xác định cấp dịch vụ thích hợp nếu bạn di chuyển máy chủ đó sang Cơ sở dữ liệu Azure SQL (hoặc nhóm cơ sở dữ liệu SQL đàn hồi).
Để thực hiện việc này, bạn phải lên lịch hoặc chạy thủ công một tập lệnh (dòng lệnh hoặc Powershell, có sẵn để tải xuống trên trang web của máy tính DTU) trong một khoảng thời gian của khối lượng công việc sản xuất điển hình.
Nếu bạn đang cố gắng phân tích một môi trường rộng lớn hoặc muốn phân tích dữ liệu từ các thời điểm cụ thể, điều này có thể trở thành một việc vặt. Trong rất nhiều trường hợp, nhiều DBA có một số công cụ giám sát đã thu thập dữ liệu hiệu suất cho chúng. Trong nhiều trường hợp, nó có thể đã nắm bắt được các chỉ số cần thiết hoặc có thể dễ dàng được định cấu hình để nắm bắt dữ liệu bạn cần. Hôm nay, chúng ta sẽ xem xét cách tận dụng SentryOne để có thể cung cấp dữ liệu thích hợp cho máy tính DTU.
Để bắt đầu, hãy xem thông tin được kéo bởi tiện ích dòng lệnh và tập lệnh PowerShell có sẵn trên trang web máy tính DTU; có 4 bộ đếm màn hình hiệu suất mà nó bắt được:
- Bộ xử lý -% Thời gian của Bộ xử lý
- Đĩa logic - Số lần đọc đĩa / giây
- Đĩa logic - Ghi đĩa / giây
- Cơ sở dữ liệu - Số byte nhật ký được tuôn ra / giây
Bước đầu tiên là xác định xem các số liệu này đã được ghi lại như một phần của thu thập dữ liệu trong SQL Sentry hay chưa. Để khám phá, tôi khuyên bạn nên đọc bài đăng trên blog này của Jason Hall, nơi anh ấy nói về cách dữ liệu được bố trí và cách bạn có thể truy vấn nó. Tôi sẽ không trình bày chi tiết từng bước ở đây, nhưng khuyến khích bạn đọc và đánh dấu trang toàn bộ loạt blog đó.
Khi tôi xem qua cơ sở dữ liệu SentryOne, tôi thấy rằng 3 trong số 4 bộ đếm đã được bắt theo mặc định. Cái duy nhất bị thiếu là [Database – Log Bytes Flushed/sec] , vì vậy tôi cần có thể bật tính năng đó. Có một bài đăng trên blog khác của Justin Randall giải thích cách làm điều đó.
Tóm lại, bạn có thể truy vấn [PerformanceAnalysisCounter] bảng.
SELECT ID, PerformanceAnalysisCounterCategoryID, PerformanceAnalysisSampleIntervalID, CounterResourceName, CounterName FROM dbo.PerformanceAnalysisCounter WHERE CounterResourceName = N'LOG_BYTES_FLUSHED_PER_SEC';
Bạn sẽ nhận thấy rằng theo mặc định, [PerformanceAnalysisSampleIntervalID] được đặt thành 0 - điều này có nghĩa là nó đã bị vô hiệu hóa. Bạn sẽ cần chạy lệnh sau để kích hoạt tính năng này. Chỉ cần kéo ID từ truy vấn CHỌN mà bạn vừa chạy và sử dụng nó trong CẬP NHẬT này:
UPDATE dbo.PerformanceAnalysisCounter SET PerformanceAnalysisSampleIntervalID = 1 WHERE ID = 166;
Sau khi chạy bản cập nhật, bạn sẽ cần khởi động lại (các) dịch vụ giám sát SentryOne có liên quan đến mục tiêu này để có thể thu thập dữ liệu bộ đếm mới.
Lưu ý rằng tôi đã đặt [PerformanceAnalysisSampleIntervalID] thành 1 để dữ liệu được ghi lại sau mỗi 10 giây, tuy nhiên, bạn có thể thu thập dữ liệu này ít thường xuyên hơn để giảm thiểu kích thước của dữ liệu được thu thập với chi phí là độ chính xác kém hơn. Xem [PerformanceAnalysisSampleInterval] bảng cho danh sách các giá trị mà bạn có thể sử dụng.
Đừng mong đợi dữ liệu bắt đầu chảy vào các bảng ngay lập tức; điều này sẽ mất thời gian để thực hiện theo cách của nó thông qua hệ thống. Bạn có thể kiểm tra dân số bằng truy vấn sau:
SELECT TOP (100) * FROM dbo.PerformanceAnalysisDataDatabaseCounter WHERE PerformanceAnalysisCounterID = 166;
Khi bạn xác nhận rằng dữ liệu đang hiển thị, bạn sẽ có dữ liệu cho từng chỉ số mà máy tính DTU yêu cầu, mặc dù bạn có thể muốn đợi trích xuất từ đầu cho đến khi bạn có một mẫu đại diện từ toàn bộ khối lượng công việc hoặc chu kỳ kinh doanh.
Nếu bạn đọc qua bài đăng trên blog của Jason, bạn sẽ thấy rằng dữ liệu được lưu trữ trong các bảng tổng hợp khác nhau và mỗi bảng tổng hợp này có tỷ lệ lưu giữ khác nhau. Nhiều trong số này thấp hơn những gì tôi muốn nếu tôi đang phân tích khối lượng công việc trong một khoảng thời gian. Mặc dù có thể thay đổi những điều này, nhưng nó có thể không phải là cách khôn ngoan nhất. Bởi vì những gì tôi đang hiển thị cho bạn không được hỗ trợ, bạn có thể muốn tránh mày mò quá nhiều với cài đặt SentryOne vì nó có thể có tác động tiêu cực đến hiệu suất, tốc độ tăng trưởng hoặc cả hai.
Để bù đắp cho điều này, tôi đã tạo một tập lệnh cho phép tôi trích xuất dữ liệu tôi cần cho các bảng tổng hợp khác nhau và lưu trữ dữ liệu đó ở vị trí riêng của nó, vì vậy tôi có thể kiểm soát việc lưu giữ của mình và không ảnh hưởng đến chức năng của SentryOne.
BẢNG:dbo.AzureDatabaseDTUData
Tôi đã tạo một bảng có tên [AzureDatabaseDTUData] và lưu trữ nó trong cơ sở dữ liệu SentryOne. Thủ tục mà tôi đã tạo sẽ tự động tạo bảng này nếu nó không tồn tại, vì vậy không cần phải thực hiện việc này theo cách thủ công trừ khi bạn muốn tùy chỉnh nơi nó được lưu trữ. Bạn có thể lưu trữ điều này trong một cơ sở dữ liệu riêng nếu muốn, bạn chỉ cần chỉnh sửa tập lệnh để làm như vậy. Bảng trông như sau:
CREATE TABLE dbo.AzureDatabaseDTUdata ( ID bigint identity(1,1) not null, DeviceID smallint not null, [TimeStamp] datetime not null, CounterName nvarchar(256) not null, [Value] float not null, InstanceName nvarchar(256) not null, CONSTRAINT PK_AzureDatabaseDTUdata PRIMARY KEY (ID) );
Thủ tục:dbo.Custom_CollectDTUDataForDevice
Đây là quy trình được lưu trữ mà bạn có thể sử dụng để kéo tất cả dữ liệu dành riêng cho DTU cùng một lúc (miễn là bạn đã thu thập bộ đếm byte nhật ký trong một khoảng thời gian đủ) hoặc lên lịch để thêm định kỳ vào dữ liệu đã thu thập cho đến khi bạn đã sẵn sàng để gửi kết quả đến máy tính DTU. Giống như bảng trên, thủ tục được tạo trong cơ sở dữ liệu SentryOne, nhưng bạn có thể dễ dàng tạo nó ở nơi khác, chỉ cần thêm tên ba hoặc bốn phần vào tham chiếu đối tượng. Giao diện của thủ tục như sau:
CREATE PROCEDURE [dbo].[Custom_CollectDTUDataForDevice] @DeviceID smallint = -1, @DaysToPurge smallint = 14, -- These define the CounterIDs in case they ever change. @ProcessorCounterID smallint = 1858, -- Processor (Default) @DiskReadCounterID smallint = 64, -- Disk Read/Sec (DiskCounter) @DiskWritesCounterID smallint = 67, -- Disk Writes/Sec (Diskcounter) @LogBytesFlushCounterID smallint = 166, -- Log Bytes Flushed/Sec (DatabaseCounter) AS ...
Lưu ý :Toàn bộ quy trình hơi dài, vì vậy nó được đính kèm với bài đăng này (dbo.Custom_CollectDTUDataForDevice.sql_.zip).
Có một số tham số bạn có thể sử dụng. Mỗi giá trị có một giá trị mặc định, vì vậy bạn không cần phải chỉ định chúng nếu bạn ổn với các giá trị mặc định.
- @DeviceID - Điều này cho phép bạn chỉ định xem bạn muốn thu thập dữ liệu cho một SQL Server cụ thể hay mọi thứ. Giá trị mặc định là -1, có nghĩa là sao chép tất cả các Máy chủ SQL đã xem. Nếu bạn chỉ muốn xuất thông tin cho một phiên bản cụ thể, hãy tìm
DeviceIDtương ứng với máy chủ trong[dbo].[Device]bảng và chuyển giá trị đó. Bạn chỉ có thể chuyển một@DeviceIDtại một thời điểm, vì vậy nếu bạn muốn chuyển qua một nhóm máy chủ, bạn có thể gọi quy trình nhiều lần hoặc bạn có thể sửa đổi quy trình để hỗ trợ một tập hợp thiết bị. - @DaysToPurge - Điều này thể hiện độ tuổi mà bạn muốn xóa dữ liệu. Giá trị mặc định là 14 ngày, nghĩa là bạn sẽ chỉ lấy dữ liệu tối đa 14 ngày và mọi dữ liệu cũ hơn 14 ngày trong bảng tùy chỉnh của bạn sẽ bị xóa.
Bốn tham số khác ở đó để kiểm tra trong tương lai, trong trường hợp SentryOne bao gồm các ID bộ đếm luôn thay đổi.
Một số lưu ý về tập lệnh:
- Khi dữ liệu được kéo, dữ liệu sẽ nhận giá trị lớn nhất từ phút bị cắt ngắn và xuất giá trị đó. Điều này có nghĩa là có một giá trị trên mỗi chỉ số mỗi phút, nhưng đó là giá trị tối đa được ghi lại. Điều này rất quan trọng vì cách dữ liệu cần được hiển thị cho máy tính DTU.
- Lần đầu tiên bạn chạy quá trình xuất, có thể lâu hơn một chút. Điều này là do nó kéo tất cả dữ liệu có thể dựa trên các giá trị tham số của bạn. Mỗi lần chạy bổ sung, dữ liệu duy nhất được trích xuất là bất kỳ dữ liệu mới nào kể từ lần chạy cuối cùng, vì vậy sẽ nhanh hơn nhiều.
- Bạn sẽ cần lập lịch để thủ tục này chạy theo lịch thời gian trước quá trình thanh lọc SentryOne. Những gì tôi đã làm chỉ là tạo Công việc tác nhân SQL để chạy hàng đêm, thu thập tất cả dữ liệu mới kể từ đêm hôm trước.
- Bởi vì quá trình thanh lọc trong SentryOne có thể khác nhau dựa trên số liệu, bạn có thể kết thúc với các hàng trong bản sao của mình không chứa tất cả 4 bộ đếm trong một khoảng thời gian. Bạn có thể chỉ muốn bắt đầu phân tích dữ liệu của mình từ khi bắt đầu quá trình trích xuất.
- Tôi đã sử dụng một khối mã từ các quy trình SentryOne hiện có để xác định bảng tổng hợp cho mỗi bộ đếm. Tôi có thể đã mã hóa tên hiện tại của các bảng, tuy nhiên, bằng cách sử dụng phương thức SentryOne, nó sẽ tương thích với bất kỳ thay đổi nào đối với quy trình tổng hợp tích hợp sẵn.
Khi dữ liệu của bạn đang được chuyển vào một bảng độc lập, bạn có thể sử dụng truy vấn PIVOT để chuyển đổi nó thành dạng mà máy tính DTU mong đợi.
Quy trình:dbo.Custom_ExportDataForDTUCalculator
Tôi đã tạo một quy trình khác để trích xuất dữ liệu sang định dạng CSV. Mã cho quy trình này cũng được đính kèm (dbo.Custom_ExportDataForDTUCalculator.sql_.zip).
Có ba tham số:
- @DeviceID - Smallint tương ứng với một trong những thiết bị bạn đang thu thập và bạn muốn gửi cho máy tính.
- @BeginTime - Ngày giờ thể hiện thời gian bắt đầu, theo giờ địa phương; ví dụ:
'2018-12-04 05:47:00.000'. Quy trình sẽ chuyển sang UTC. Nếu bị bỏ qua, nó sẽ thu thập từ giá trị sớm nhất trong bảng. - @EndTime - Ngày giờ đại diện cho thời gian kết thúc, một lần nữa theo giờ địa phương; ví dụ:
'2018-12-06 12:54:00.000'. Nếu bị bỏ qua, nó sẽ thu thập đến giá trị mới nhất trong bảng.
Một thực thi ví dụ, để lấy tất cả dữ liệu được thu thập cho SQLInstanceA từ ngày 4 tháng 12 lúc 5:47 sáng và ngày 6 tháng 12 lúc 12:54 chiều.
EXEC SentryOne.dbo.custom_ExportDataForDTUCalculator @DeviceID = 12, @BeginTime = '2018-12-04 05:47:00.000', @EndTime = '2018-12-06 12:54:00.000';
Dữ liệu sẽ cần được xuất sang tệp CSV. Đừng lo lắng về bản thân dữ liệu; Tôi đảm bảo xuất kết quả để không có thông tin nhận dạng về máy chủ của bạn trong tệp csv, chỉ là ngày tháng và số liệu.
Nếu bạn chạy truy vấn trong SSMS, bạn có thể nhấp chuột phải và xuất kết quả; tuy nhiên, bạn có các tùy chọn hạn chế ở đây và bạn sẽ phải thao tác đầu ra để có được định dạng mà máy tính DTU mong đợi. (Vui lòng thử và cho tôi biết nếu bạn tìm thấy cách thực hiện việc này.)
Tôi khuyên bạn chỉ nên sử dụng trình hướng dẫn xuất được đưa vào SSMS. Nhấp chuột phải vào cơ sở dữ liệu và chuyển đến Nhiệm vụ -> Xuất Dữ liệu. Đối với Nguồn dữ liệu của bạn, hãy sử dụng “SQL Server Native Client” và trỏ nó vào cơ sở dữ liệu SentryOne của bạn (hoặc bất cứ nơi nào bạn có bản sao dữ liệu được lưu trữ). Đối với điểm đến của bạn, bạn sẽ muốn chọn “Đích đến của tệp phẳng”. Duyệt đến một vị trí, đặt tên cho tệp và lưu tệp dưới dạng CSV.
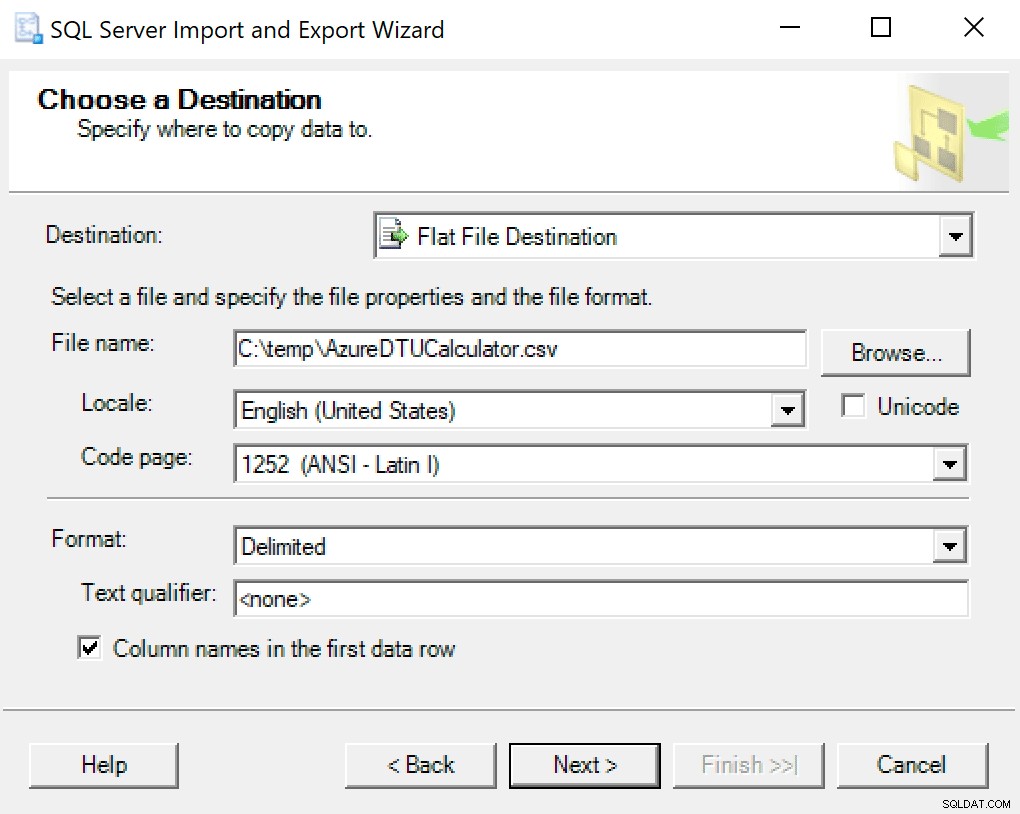
Chú ý để yên trang mã; một số có thể trả lại lỗi. Tôi biết rằng 1252 hoạt động tốt. Phần còn lại của các giá trị để làm mặc định.
Trên màn hình tiếp theo, chọn tùy chọn Viết truy vấn để chỉ định dữ liệu cần truyền .
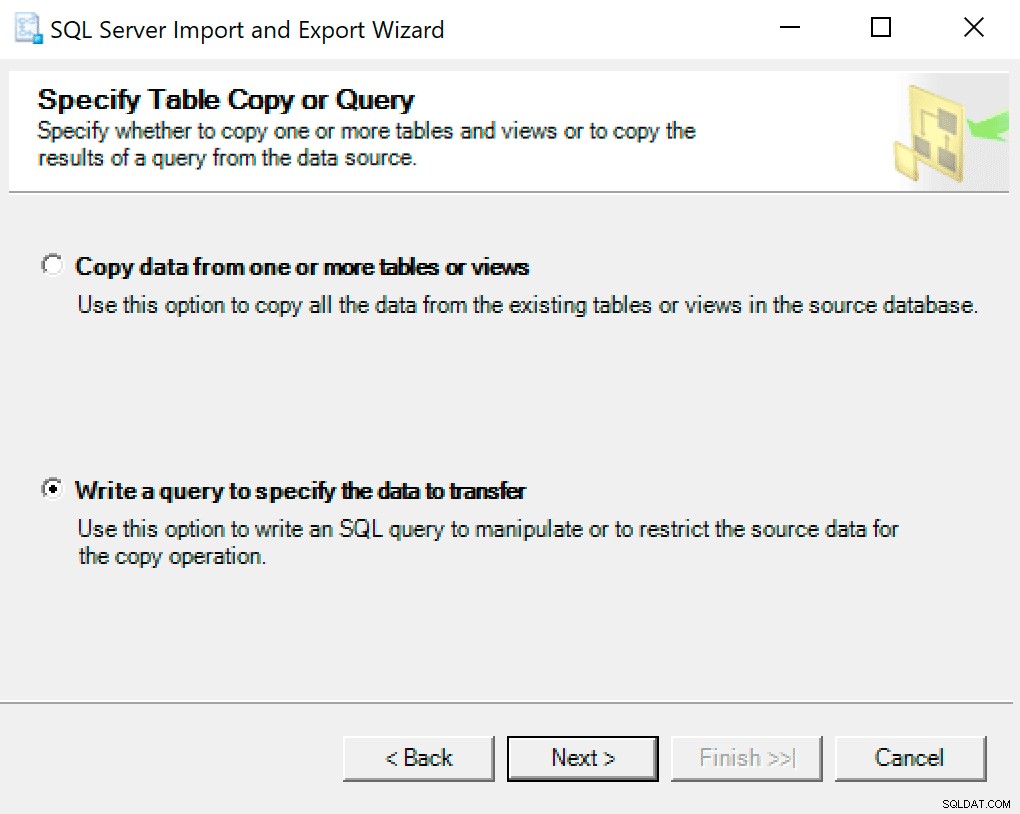
Trong cửa sổ tiếp theo, hãy sao chép lời gọi thủ tục với các tham số của bạn được đặt vào đó. Lượt tiếp theo.
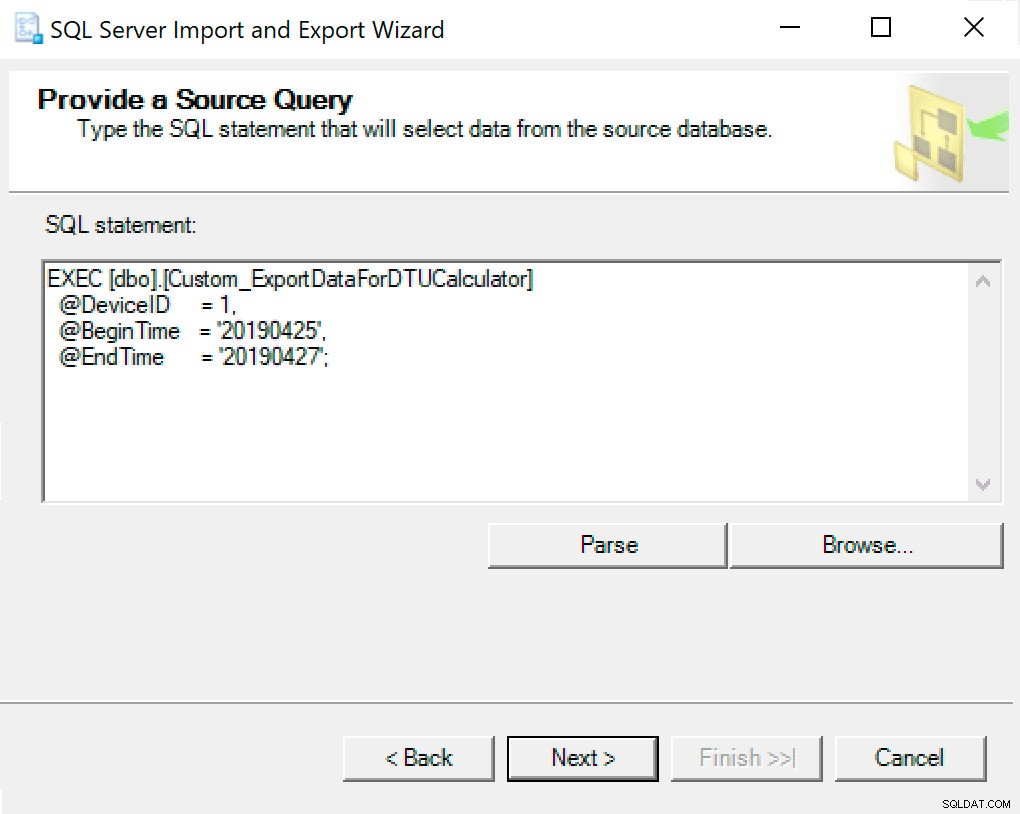
Khi bạn đến Định cấu hình Đích tệp phẳng, tôi để các tùy chọn làm mặc định. Đây là một ảnh chụp màn hình trong trường hợp của bạn khác nhau:
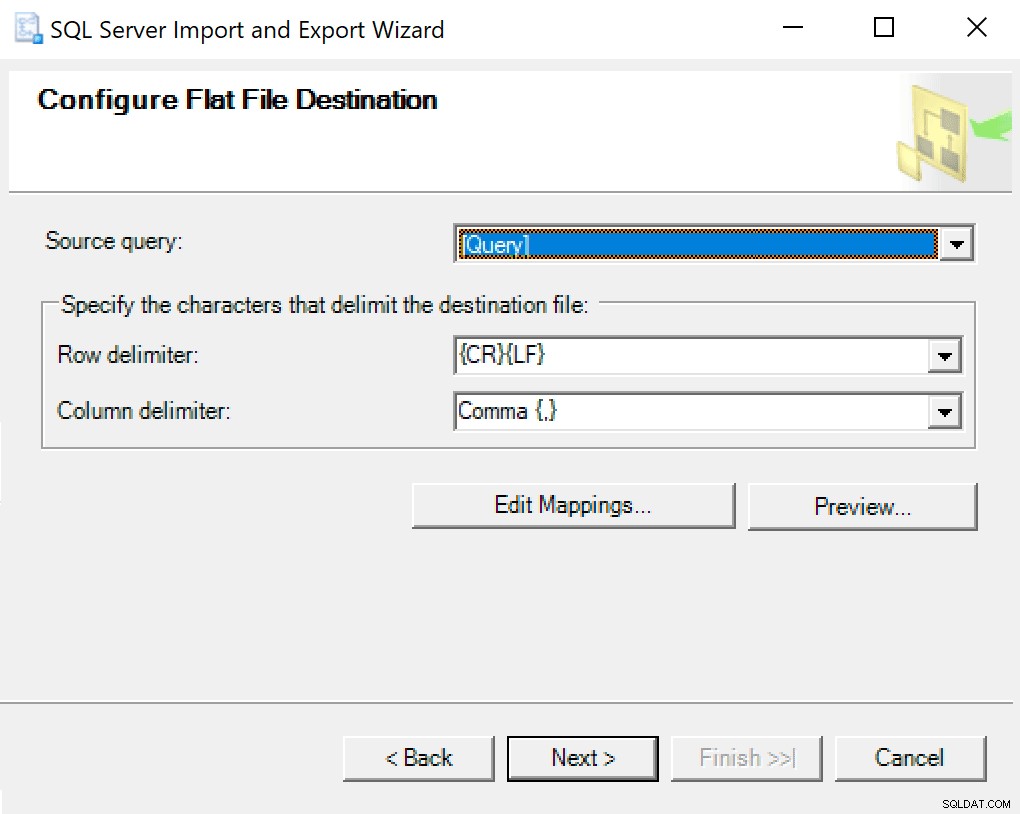
Nhấn tiếp theo và chạy ngay lập tức. Một tệp sẽ được tạo mà bạn sẽ sử dụng ở bước cuối cùng.
LƯU Ý :Bạn có thể tạo một gói SSIS để sử dụng cho việc này và sau đó chuyển các giá trị tham số của bạn vào gói SSIS nếu bạn định làm việc này nhiều. Điều này sẽ giúp bạn không phải xem qua trình hướng dẫn mỗi lần.
Điều hướng đến vị trí bạn đã lưu tệp và xác minh nó ở đó. Khi bạn mở nó, nó sẽ trông giống như sau:
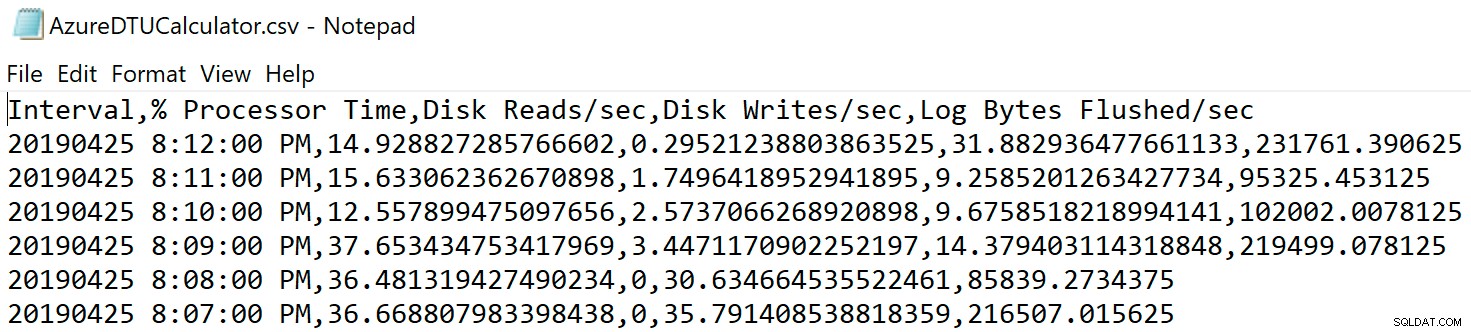
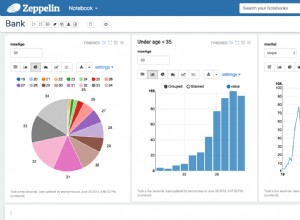
Mở trang web máy tính DTU và cuộn xuống phần có nội dung “Tải lên tệp CSV và Tính toán”. Nhập số lõi mà máy chủ có, tải lên tệp CSV và nhấp vào Tính toán. Bạn sẽ nhận được một tập hợp các kết quả như thế này (nhấp vào bất kỳ hình ảnh nào để thu phóng):
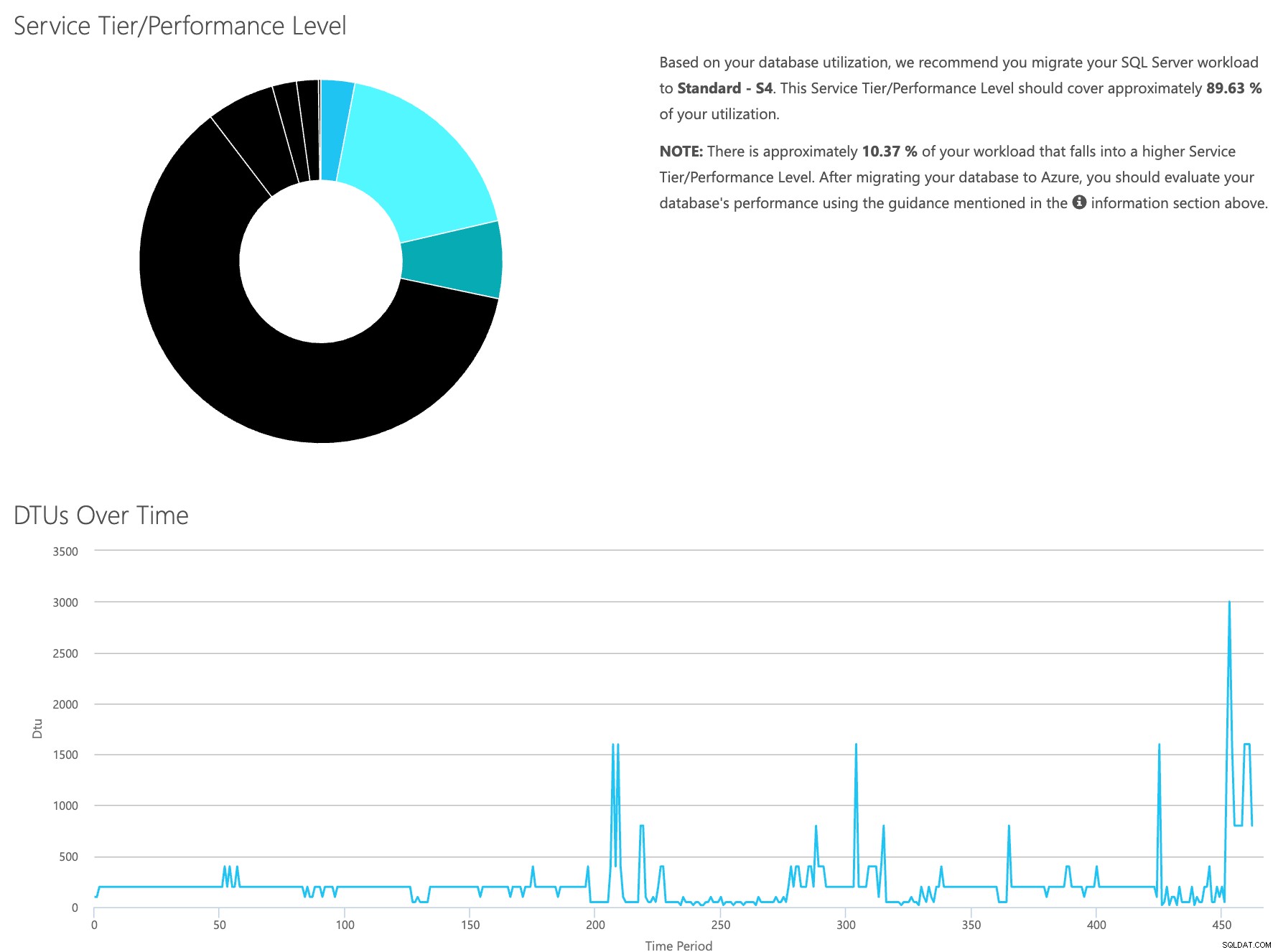
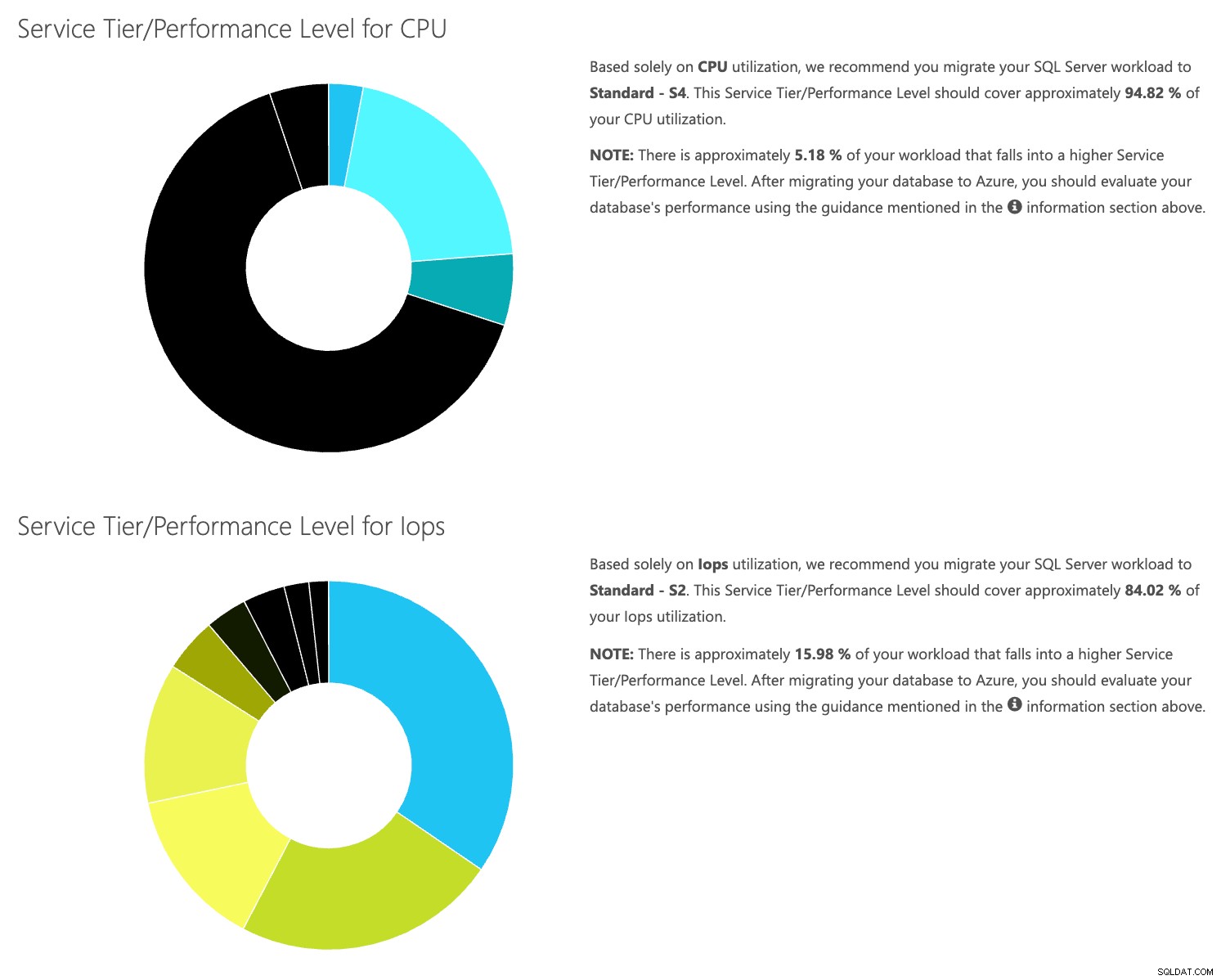
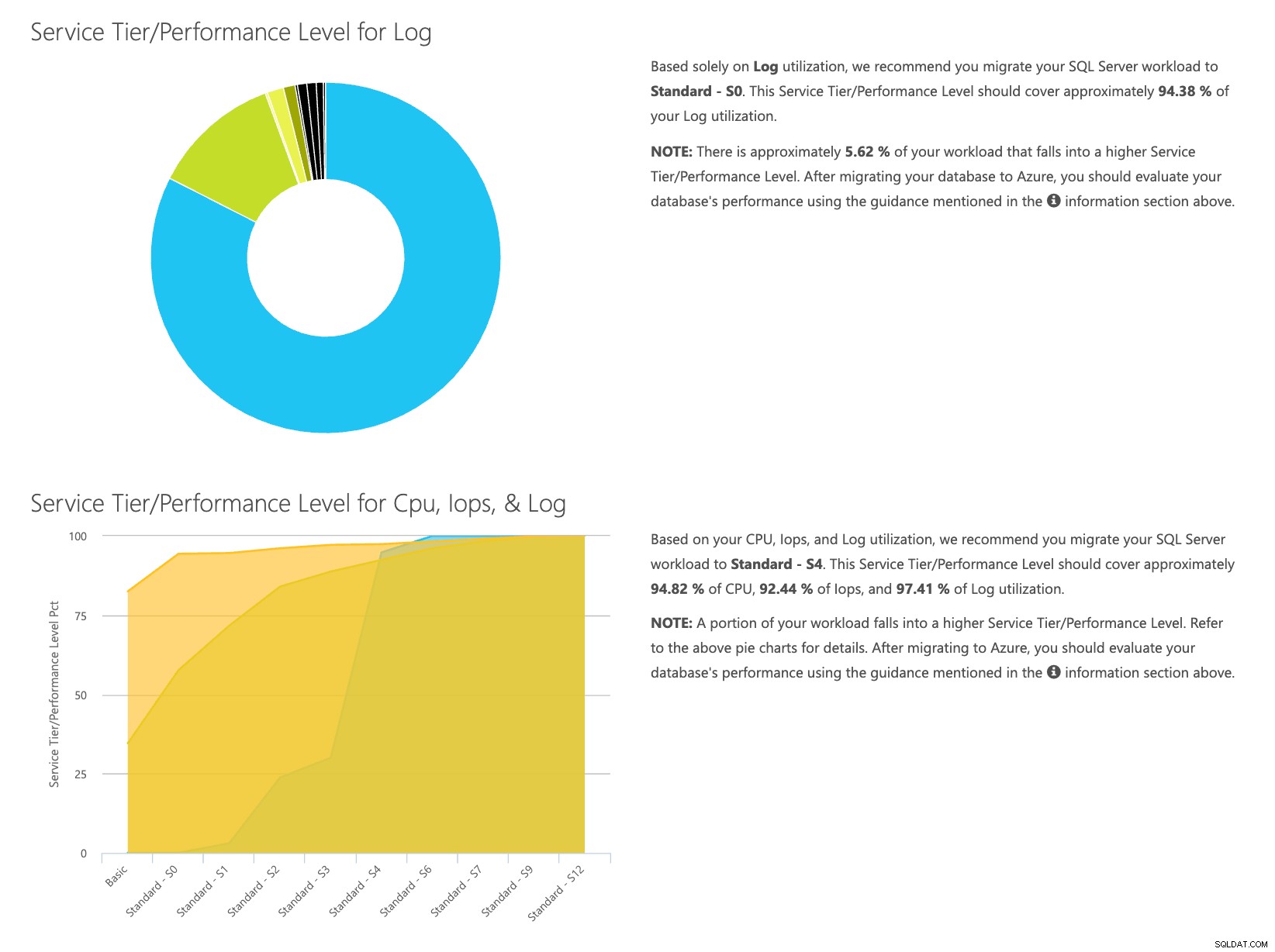
Vì bạn có dữ liệu được lưu trữ riêng biệt, bạn có thể phân tích khối lượng công việc từ những thời điểm khác nhau và bạn có thể thực hiện việc này mà không cần phải chạy thủ công \ lập lịch trình lệnh tiện ích \ powershell script cho bất kỳ máy chủ nào bạn đang sử dụng SentryOne để giám sát.
Để tóm tắt ngắn gọn các bước, đây là những gì cần phải thực hiện:
- Bật bộ đếm [Cơ sở dữ liệu - Số byte nhật ký được tuôn ra / giây] và xác minh dữ liệu đang được thu thập
- Sao chép dữ liệu từ các bảng SentryOne vào bảng của riêng bạn (và lên lịch khi thích hợp).
- Xuất dữ liệu từ bảng mới ở định dạng phù hợp cho máy tính DTU
- Tải CSV lên Máy tính DTU
Đối với bất kỳ máy chủ / phiên bản nào bạn đang cân nhắc chuyển sang đám mây và bạn hiện đang theo dõi với SQL Sentry, đây là một cách tương đối dễ dàng để ước tính cả loại cấp dịch vụ bạn sẽ cần và chi phí. Tuy nhiên, bạn vẫn cần phải theo dõi nó khi nó ở trên đó; cho điều đó, hãy xem SentryOne DB Sentry.
Giới thiệu về tác giả
 Dustin Dorsey hiện là Kỹ sư quản lý cơ sở dữ liệu cho LifePoint Health, trong đó anh ấy lãnh đạo một nhóm chịu trách nhiệm quản lý và các giải pháp kỹ thuật trong công nghệ cơ sở dữ liệu cho 90 bệnh viện. Anh ấy đã làm việc và hỗ trợ SQL Server chủ yếu trong lĩnh vực chăm sóc sức khỏe kể từ năm 2008 với năng lực quản trị, kiến trúc, phát triển và BI. Anh ấy đam mê tìm cách giải quyết các vấn đề xảy ra với DBA hàng ngày và thích chia sẻ điều này với những người khác. Anh ấy có thể được tìm thấy đang phát biểu tại các sự kiện cộng đồng SQL, cũng như viết blog tại DustinDorsey.com.
Dustin Dorsey hiện là Kỹ sư quản lý cơ sở dữ liệu cho LifePoint Health, trong đó anh ấy lãnh đạo một nhóm chịu trách nhiệm quản lý và các giải pháp kỹ thuật trong công nghệ cơ sở dữ liệu cho 90 bệnh viện. Anh ấy đã làm việc và hỗ trợ SQL Server chủ yếu trong lĩnh vực chăm sóc sức khỏe kể từ năm 2008 với năng lực quản trị, kiến trúc, phát triển và BI. Anh ấy đam mê tìm cách giải quyết các vấn đề xảy ra với DBA hàng ngày và thích chia sẻ điều này với những người khác. Anh ấy có thể được tìm thấy đang phát biểu tại các sự kiện cộng đồng SQL, cũng như viết blog tại DustinDorsey.com.