ANY tổng hợp không phải là thứ mà chúng ta có thể viết trực tiếp trong Transact SQL. Đây là một tính năng nội bộ duy nhất được sử dụng bởi công cụ thực thi và tối ưu hóa truy vấn.
Cá nhân tôi khá thích ANY tổng hợp, vì vậy hơi thất vọng khi biết rằng nó bị hỏng một cách khá cơ bản. Hương vị đặc biệt của ‘hỏng’ mà tôi đang đề cập đến ở đây là sự đa dạng cho kết quả sai.
Trong bài đăng này, tôi xem xét hai địa điểm cụ thể mà ANY tổng hợp thường xuất hiện, chứng minh vấn đề kết quả sai và đề xuất các giải pháp thay thế khi cần thiết.
Đối với nền trên ANY tổng hợp, vui lòng xem bài đăng trước của tôi Kế hoạch truy vấn không có tài liệu:Tổng hợp BẤT KỲ.
1. Một hàng cho mỗi truy vấn nhóm
Đây phải là một trong những yêu cầu truy vấn phổ biến nhất ngày nay, với một giải pháp rất nổi tiếng. Bạn có thể viết loại truy vấn này hàng ngày, tự động theo mẫu mà không thực sự nghĩ về nó.
Ý tưởng là đánh số tập hợp đầu vào của các hàng bằng ROW_NUMBER chức năng cửa sổ, được phân vùng theo nhóm hoặc các cột. Điều đó được gói gọn trong Biểu thức bảng chung hoặc bảng dẫn xuất và được lọc xuống các hàng có số hàng được tính bằng một. Kể từ ROW_NUMBER khởi động lại tại một hàng cho mỗi nhóm, điều này cung cấp cho chúng tôi một hàng bắt buộc cho mỗi nhóm.
Không có vấn đề gì với mẫu chung đó. Loại một hàng cho mỗi truy vấn nhóm tuân theo ANY vấn đề tổng hợp là vấn đề mà chúng tôi không quan tâm hàng cụ thể nào được chọn từ mỗi nhóm.
Trong trường hợp đó, không rõ cột nào nên được sử dụng trong ORDER BY bắt buộc mệnh đề của ROW_NUMBER chức năng cửa sổ. Rốt cuộc, chúng tôi rõ ràng không quan tâm hàng nào được chọn. Một cách tiếp cận phổ biến là sử dụng lại PARTITION BY (các) cột trong ORDER BY mệnh đề. Đây là nơi sự cố có thể xảy ra.
Ví dụ
Chúng ta hãy xem một ví dụ sử dụng tập dữ liệu đồ chơi:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
Yêu cầu là trả về bất kỳ một hàng dữ liệu hoàn chỉnh nào từ mỗi nhóm, trong đó tư cách thành viên nhóm được xác định bằng giá trị trong cột c1 .

Theo dõi ROW_NUMBER , chúng ta có thể viết một truy vấn như sau (lưu ý ORDER BY mệnh đề của ROW_NUMBER hàm cửa sổ khớp với PARTITION BY mệnh đề):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Như đã trình bày, truy vấn này thực thi thành công, với kết quả chính xác. Các kết quả về mặt kỹ thuật là không xác định vì SQL Server có thể trả về bất kỳ một hàng nào trong mỗi nhóm một cách hợp lệ. Tuy nhiên, nếu bạn tự chạy truy vấn này, bạn rất có thể sẽ thấy kết quả giống như tôi làm:
Kế hoạch thực thi phụ thuộc vào phiên bản SQL Server được sử dụng và không phụ thuộc vào mức độ tương thích của cơ sở dữ liệu.
Trên SQL Server 2014 trở về trước, kế hoạch là:

Đối với SQL Server 2016 trở lên, bạn sẽ thấy:

Cả hai kế hoạch đều an toàn, nhưng vì những lý do khác nhau. Phân loại riêng biệt kế hoạch chứa ANY tổng hợp, nhưng Phân loại riêng biệt triển khai toán tử không hiển thị lỗi.
Gói SQL Server 2016+ phức tạp hơn không sử dụng ANY tổng hợp lại. Sắp xếp đặt các hàng vào thứ tự cần thiết cho thao tác đánh số hàng. Phân đoạn toán tử đặt một cờ khi bắt đầu mỗi nhóm mới. Dự án trình tự tính số hàng. Cuối cùng, Bộ lọc toán tử chỉ chuyển những hàng có số hàng được tính là một.
Lỗi
Để nhận được kết quả không chính xác với tập dữ liệu này, chúng tôi cần sử dụng SQL Server 2014 trở về trước và ANY tổng hợp cần được triển khai trong Tổng hợp luồng hoặc Eager Hash Aggregate toán tử ( Tổng hợp đối sánh băm phân biệt luồng không tạo ra lỗi).
Một cách để khuyến khích trình tối ưu hóa chọn Tổng số luồng thay vì Phân loại riêng biệt là thêm một chỉ mục được phân nhóm để cung cấp thứ tự theo cột c1 :
CREATE CLUSTERED INDEX c ON #Data (c1);
Sau thay đổi đó, kế hoạch thực thi sẽ trở thành:

ANY tổng hợp được hiển thị trong Thuộc tính cửa sổ khi Tổng hợp luồng toán tử được chọn:

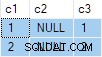
Kết quả của truy vấn là:
Điều này sai . SQL Server đã trả về các hàng không tồn tại trong dữ liệu nguồn. Không có hàng nguồn nào trong đó c2 = 1 và c3 = 1 Ví dụ. Xin nhắc lại, dữ liệu nguồn là:
Kế hoạch thực thi tính toán sai tách biệt ANY tổng hợp cho c2 và c3 cột, bỏ qua null. Mỗi tổng hợp độc lập trả về non-null đầu tiên giá trị mà nó gặp phải, đưa ra kết quả trong đó các giá trị cho c2 và c3 đến từ các hàng nguồn khác nhau . Đây không phải là những gì đặc tả truy vấn SQL ban đầu yêu cầu.
Kết quả sai giống nhau có thể được tạo ra có hoặc không có chỉ mục được phân nhóm bằng cách thêm OPTION (HASH GROUP) gợi ý để tạo một kế hoạch với Eager Hash Aggregate thay vì Tổng hợp luồng .
Điều kiện
Sự cố này chỉ có thể xảy ra khi có nhiều ANY tổng hợp có sẵn và dữ liệu tổng hợp chứa rỗng. Như đã lưu ý, sự cố chỉ ảnh hưởng đến Tổng hợp luồng và Eager Hash Aggregate các nhà khai thác; Phân loại riêng biệt và Dòng chảy riêng biệt không bị ảnh hưởng.
SQL Server 2016 trở đi cố gắng tránh giới thiệu nhiều ANY tổng hợp cho bất kỳ mẫu truy vấn đánh số hàng một hàng trên mỗi nhóm khi các cột nguồn có giá trị rỗng. Khi điều này xảy ra, kế hoạch thực thi sẽ chứa Phân đoạn , Dự án trình tự và Bộ lọc toán tử thay vì tổng hợp. Hình dạng kế hoạch này luôn an toàn, vì không có ANY nào tổng hợp được sử dụng.
Sao chép lỗi trong SQL Server 2016+
Trình tối ưu hóa SQL Server không hoàn hảo trong việc phát hiện khi cột ban đầu được giới hạn là NOT NULL vẫn có thể tạo ra giá trị trung gian rỗng thông qua các thao tác dữ liệu.
Để tái tạo điều này, chúng ta sẽ bắt đầu với một bảng trong đó tất cả các cột được khai báo là NOT NULL :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
Chúng tôi có thể tạo null từ tập dữ liệu này theo nhiều cách, hầu hết trong số đó trình tối ưu hóa có thể phát hiện thành công và do đó, tránh đưa vào ANY tổng hợp trong quá trình tối ưu hóa.
Dưới đây là một cách để thêm các giá trị nulls trượt dưới radar:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; Truy vấn đó tạo ra kết quả sau:
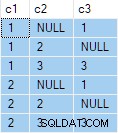
Bước tiếp theo là sử dụng đặc tả truy vấn đó làm dữ liệu nguồn cho truy vấn tiêu chuẩn “bất kỳ một hàng nào trên mỗi nhóm”:
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Trên bất kỳ phiên bản nào của SQL Server, tạo ra kế hoạch sau:
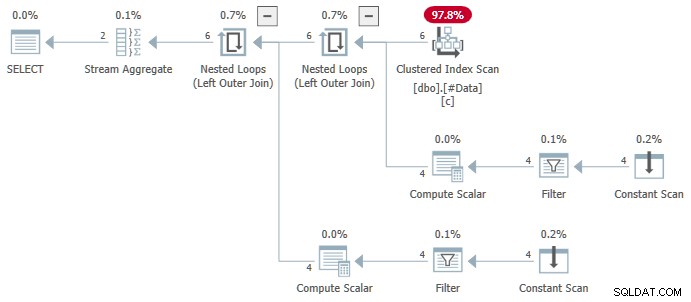
Tổng hợp luồng chứa nhiều ANY tổng hợp và kết quả là sai . Không có hàng nào trong số các hàng được trả về xuất hiện trong tập dữ liệu nguồn:
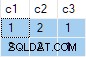
db <> bản trình diễn trực tuyến fiddle
Giải pháp thay thế
Cách giải quyết hoàn toàn đáng tin cậy duy nhất cho đến khi lỗi này được khắc phục là tránh dạng trong đó ROW_NUMBER có cùng cột trong ORDER BY mệnh đề như trong PARTITION BY mệnh đề.
Khi chúng ta không quan tâm cái nào một hàng được chọn từ mỗi nhóm, thật không may là ORDER BY mệnh đề là cần thiết ở tất cả. Một cách để giải quyết vấn đề là sử dụng hằng số thời gian chạy như ORDER BY @@SPID trong chức năng cửa sổ.
2. Cập nhật không xác định
Vấn đề với nhiều ANY tổng hợp trên các đầu vào có thể không bị hạn chế đối với bất kỳ mẫu truy vấn một hàng cho mỗi nhóm. Trình tối ưu hóa truy vấn có thể giới thiệu một ANY nội bộ nào tổng hợp trong một số trường hợp. Một trong những trường hợp đó là cập nhật không xác định.
Đ không xác định cập nhật là nơi câu lệnh không đảm bảo rằng mỗi hàng mục tiêu sẽ được cập nhật nhiều nhất một lần. Nói cách khác, có nhiều hàng nguồn cho ít nhất một hàng đích. Tài liệu cảnh báo rõ ràng về điều này:
Hãy thận trọng khi chỉ định mệnh đề FROM để cung cấp tiêu chí cho thao tác cập nhật.Kết quả của câu lệnh CẬP NHẬT không được xác định nếu câu lệnh bao gồm mệnh đề FROM không được chỉ định theo cách mà chỉ một giá trị có sẵn cho mỗi lần xuất hiện cột được cập nhật, điều đó là nếu câu lệnh UPDATE không mang tính xác định.
Để xử lý cập nhật không xác định, trình tối ưu hóa nhóm các hàng bằng một khóa (chỉ mục hoặc RID) và áp dụng ANY tổng hợp vào các cột còn lại. Ý tưởng cơ bản là chọn một hàng từ nhiều ứng cử viên và sử dụng các giá trị từ hàng đó để thực hiện cập nhật. Có những điểm tương đồng rõ ràng với ROW_NUMBER trước đó vấn đề, vì vậy không có gì ngạc nhiên khi bạn có thể dễ dàng chứng minh một bản cập nhật không chính xác.
Không giống như sự cố trước, SQL Server hiện không có bước đặc biệt nào để tránh nhiều ANY tổng hợp trên các cột vô hiệu khi thực hiện cập nhật không xác định. Do đó, điều sau liên quan đến tất cả các phiên bản SQL Server , bao gồm SQL Server 2019 CTP 3.0.
Ví dụ
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db <> bản trình diễn trực tuyến fiddle
Về mặt logic, bản cập nhật này sẽ luôn tạo ra lỗi:Bảng đích không cho phép giá trị rỗng trong bất kỳ cột nào. Cho dù hàng phù hợp nào được chọn từ bảng nguồn, hãy cố gắng cập nhật cột c2 hoặc c3 thành null phải xảy ra.
Rất tiếc, cập nhật thành công và trạng thái cuối cùng của bảng đích không nhất quán với dữ liệu được cung cấp:
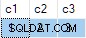
Tôi đã báo cáo đây là một lỗi. Công việc xung quanh là tránh viết UPDATE không xác định câu lệnh, vì vậy ANY không cần tổng hợp để giải quyết sự không rõ ràng.
Như đã đề cập, SQL Server có thể giới thiệu ANY tổng hợp trong nhiều trường hợp hơn hai ví dụ được đưa ra ở đây. Nếu điều này xảy ra khi cột tổng hợp chứa các giá trị rỗng, thì sẽ có khả năng dẫn đến kết quả sai.