Đã qua lâu rồi cái thời mà cơ sở dữ liệu “cơ sở dữ liệu” là một Hệ thống quản lý cơ sở dữ liệu quan hệ duy nhất được cài đặt thường trên máy chủ mạnh nhất trong trung tâm dữ liệu. Cơ sở dữ liệu như vậy phục vụ tất cả các loại yêu cầu - OLTP, OLAP, bất kỳ thứ gì doanh nghiệp yêu cầu. Ngày nay, cơ sở dữ liệu chạy trên phần cứng hàng hóa, chúng cũng phức tạp hơn về tính khả dụng cao và chuyên biệt để xử lý loại lưu lượng truy cập cụ thể. Chuyên môn hóa cho phép họ đạt được hiệu suất tốt hơn nhiều - mọi thứ đều được tối ưu hóa để xử lý một loại dữ liệu cụ thể:trình tối ưu hóa, công cụ lưu trữ, thậm chí ngôn ngữ không cần phải là SQL như trước đây. Nó có thể dựa trên SQL với một số tiện ích mở rộng cho phép thao tác dữ liệu hiệu quả hơn hoặc nó cũng có thể là một thứ gì đó hoàn toàn mới, được tạo từ đầu.
Ngày nay chúng ta có cơ sở dữ liệu dạng cột, phân tích như ClickHouse hoặc MariaDB AX, chúng ta có các nền tảng dữ liệu lớn như Hadoop, các giải pháp NoSQL như MongoDB hoặc Cassandra, các kho dữ liệu khóa-giá trị như Redis. Chúng tôi cũng có cơ sở dữ liệu Dòng thời gian như Prometheus hoặc TimeScaleDB. Đây là những gì chúng tôi sẽ tập trung vào trong bài đăng trên blog này. Cơ sở dữ liệu Dòng thời gian - chúng là gì và tại sao bạn muốn sử dụng thêm một cơ sở dữ liệu khác trong môi trường của mình.
Cơ sở dữ liệu chuỗi thời gian dành cho mục đích gì?
Như tên cho thấy, cơ sở dữ liệu chuỗi thời gian được thiết kế để lưu trữ dữ liệu thay đổi theo thời gian. Đây có thể là bất kỳ loại dữ liệu nào được thu thập theo thời gian. Nó có thể là số liệu được thu thập từ một số hệ thống - tất cả các hệ thống thịnh hành đều là ví dụ về dữ liệu chuỗi thời gian.

Bất cứ khi nào bạn nhìn vào bảng điều khiển trong ClusterControl, bạn thực sự đang xem bản trình bày trực quan của dữ liệu chuỗi thời gian được lưu trữ trong Prometheus, một cơ sở dữ liệu chuỗi thời gian.
Dữ liệu chuỗi thời gian không giới hạn ở các chỉ số cơ sở dữ liệu. Mọi thứ đều có thể là một thước đo. Dòng người vào trung tâm mua sắm thay đổi như thế nào theo thời gian? Giao thông trong thành phố thay đổi như thế nào? Việc sử dụng các phương tiện giao thông công cộng thay đổi như thế nào trong ngày? Dòng nước chảy trong suối hoặc sông. Lượng năng lượng do nhà máy nước tạo ra. Tất cả điều này và mọi thứ khác có thể được đo bằng thời gian là một ví dụ về dữ liệu chuỗi thời gian. Dữ liệu như vậy bạn có thể truy vấn, vẽ biểu đồ, phân tích để tìm mối tương quan giữa các số liệu khác nhau.
Dữ liệu được cấu trúc như thế nào trong Cơ sở dữ liệu chuỗi thời gian?
Như bạn có thể tưởng tượng, phần dữ liệu quan trọng nhất trong cơ sở dữ liệu chuỗi thời gian là thời gian. Có hai cách chính để lưu trữ dữ liệu. Một, thứ tương tự như bộ nhớ khóa-giá trị có thể trông như thế này:
| Dấu thời gian | Số liệu 1 |
|---|---|
| 2019-03-28 00:00:01 | 2356 |
| 2019-03-28 00:00:02 | 6874 |
| 2019-03-28 00:00:03 | 3245 |
| 2019-03-28 00:00:04 | 2340 |
Nói tóm lại, đối với mỗi dấu thời gian, chúng tôi có một số giá trị cho chỉ số của mình.
Một ví dụ khác sẽ liên quan đến nhiều số liệu hơn. Thay vì lưu trữ từng số liệu trong một bảng hoặc bộ sưu tập riêng biệt, bạn có thể lưu trữ nhiều số liệu cùng với nhau.
| Dấu thời gian | Số liệu 1 | Số liệu 2 | Số liệu 3 | Số liệu 4 | Số liệu 5 |
|---|---|---|---|---|---|
| 2019-03-28 00:00:01 | 765 | 873 | 124 | 98 | 0 |
| 2019-03-28 00:00:02 | 5876 | 765 | 872 | 7864 | 634 |
| 2019-03-28 00:00:03 | 234 | 7679 | 98 | 65 | 34 |
| 2019-03-28 00:00:04 | 345 | 3 | 598 | 0 | 7345 |
Cấu trúc dữ liệu này giúp truy vấn dữ liệu hiệu quả hơn khi các chỉ số có liên quan với nhau. Thay vì đọc nhiều bảng và kết hợp chúng để có tất cả các chỉ số lại với nhau, chỉ cần đọc một bảng duy nhất là đủ và tất cả dữ liệu đã sẵn sàng để được xử lý và trình bày.
Bạn có thể tự hỏi - điều gì thực sự mới ở đây? Điều này khác với bảng thông thường trong MySQL hoặc cơ sở dữ liệu quan hệ khác như thế nào? Chà, thiết kế bảng khá giống nhau nhưng có sự khác biệt đáng kể về khối lượng công việc, khi một kho dữ liệu được thiết kế để khai thác chúng, có thể cải thiện đáng kể hiệu suất.
Dữ liệu chuỗi thời gian thường chỉ được thêm vào - rất ít khả năng bạn sẽ cập nhật dữ liệu cũ. Bạn thường không xóa các hàng cụ thể, mặt khác, bạn có thể muốn một số loại tổng hợp dữ liệu theo thời gian. Điều này, khi được tính đến khi thiết kế nội bộ cơ sở dữ liệu, sẽ tạo ra sự khác biệt đáng kể so với cơ sở dữ liệu quan hệ "tiêu chuẩn" (và không phải cũng là quan hệ) nhằm phục vụ loại lưu lượng Xử lý Giao dịch Trực tuyến:điều quan trọng nhất là khả năng lưu trữ nhất quán (vui nhất) lượng lớn dữ liệu sẽ đến với thời gian.
Có thể sử dụng RDBMS để lưu trữ dữ liệu chuỗi thời gian, nhưng RDBMS không được tối ưu hóa cho nó. Dữ liệu và chỉ mục được tạo ở mặt sau của nó có thể rất lớn và truy vấn chậm. Công cụ lưu trữ được sử dụng trong RDBMS được thiết kế để lưu trữ nhiều loại dữ liệu khác nhau. Chúng thường được tối ưu hóa cho khối lượng công việc Xử lý giao dịch trực tuyến bao gồm việc sửa đổi và xóa dữ liệu thường xuyên. Cơ sở dữ liệu quan hệ cũng có xu hướng thiếu các chức năng và tính năng chuyên biệt liên quan đến việc xử lý dữ liệu chuỗi thời gian. Chúng tôi đã đề cập rằng bạn có thể muốn tổng hợp dữ liệu cũ hơn một khoảng thời gian nhất định. Bạn cũng có thể muốn dễ dàng chạy một số chức năng thống kê trên dữ liệu chuỗi thời gian của mình để làm mượt nó, xác định và so sánh xu hướng, nội suy dữ liệu và nhiều hơn nữa. Ví dụ:tại đây, bạn có thể tìm thấy một số chức năng mà Prometheus cung cấp cho người dùng.
Ví dụ về Cơ sở dữ liệu chuỗi thời gian
Có nhiều cơ sở dữ liệu chuỗi thời gian hiện có trên thị trường vì vậy không thể bao quát tất cả chúng. Chúng tôi vẫn muốn đưa ra một số ví dụ về cơ sở dữ liệu chuỗi thời gian mà bạn có thể biết hoặc thậm chí có thể sử dụng (cố ý hoặc không).
InfluxDB
InfluxDB đã được tạo bởi InfluxData. Nó là một cơ sở dữ liệu chuỗi thời gian mã nguồn mở được viết bằng Go. Kho dữ liệu cung cấp ngôn ngữ giống SQL để truy vấn dữ liệu, giúp các nhà phát triển dễ dàng tích hợp vào các ứng dụng của họ. InfluxDB cũng hoạt động như một phần của cung cấp thương mại, bao gồm toàn bộ ngăn xếp được thiết kế để cung cấp một môi trường đầy đủ tính năng, có tính khả dụng cao để xử lý dữ liệu chuỗi thời gian.
Prometheus
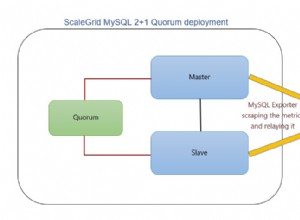
Prometheus là một dự án mã nguồn mở khác cũng được viết bằng Go. Nó thường được sử dụng như một phần mềm phụ trợ cho các công cụ và dự án nguồn mở khác nhau, ví dụ như Giám sát và Quản lý Percona. Prometheus cũng là một cơ sở dữ liệu chuỗi thời gian được lựa chọn cho ClusterControl.

Prometheus có thể được triển khai từ ClusterControl được sử dụng để lưu trữ dữ liệu chuỗi thời gian được thu thập trên các máy chủ cơ sở dữ liệu do ClusterControl giám sát và quản lý:

Được sử dụng rộng rãi trong thế giới nguồn mở, Prometheus khá dễ dàng để tích hợp vào môi trường hiện tại của bạn bằng cách sử dụng nhiều nhà xuất khẩu.
RRDtool
Đây có thể là một ví dụ về cơ sở dữ liệu chuỗi thời gian mà nhiều người sử dụng mà không biết họ làm điều đó. RRDtool là một dự án mã nguồn mở rất phổ biến để lưu trữ và hiển thị dữ liệu chuỗi thời gian. Nếu bạn đã từng sử dụng Cacti, nó dựa trên RRDtool. Nếu bạn thiết kế giải pháp của riêng mình, rất có thể bạn cũng đã sử dụng RRDtool làm chương trình phụ trợ để lưu trữ dữ liệu của mình. Ngày nay, nó không còn phổ biến như trước nhưng vào những năm 2000 - 2010, đây là cách phổ biến nhất để lưu trữ dữ liệu chuỗi thời gian. Sự thật thú vị - các phiên bản đầu tiên của ClusterControl đã sử dụng nó.
TimeScale
TimeScale là một cơ sở dữ liệu chuỗi thời gian được phát triển trên PostgreSQL. Nó là một tiện ích mở rộng trên PostgreSQL, dựa vào kho dữ liệu cơ bản để cung cấp quyền truy cập vào dữ liệu, có nghĩa là nó chấp nhận tất cả SQL mà bạn có thể muốn sử dụng. Là một phần mở rộng, nó sử dụng tất cả các tính năng và phần mở rộng khác của PostgreSQL. Bạn có thể kết hợp chuỗi thời gian và loại dữ liệu khác, chẳng hạn như để kết hợp chuỗi thời gian và siêu dữ liệu, làm phong phú thêm kết quả đầu ra. Bạn cũng có thể thực hiện lọc nâng cao hơn bằng cách sử dụng các THAM GIA và các bảng không theo chuỗi thời gian. Tận dụng hỗ trợ GIS trong PostgreSQL TimeScale có thể dễ dàng được sử dụng để theo dõi vị trí địa lý theo thời gian. Nó cũng có thể tận dụng tất cả các khả năng mở rộng mà PostgreSQL cung cấp, bao gồm cả nhân rộng.
Dòng thời gian
Amazon Web Services cũng cung cấp dịch vụ cho cơ sở dữ liệu chuỗi thời gian. Dòng thời gian đã được công bố khá gần đây, vào tháng 11 năm 2018. Nó thêm một kho dữ liệu khác vào danh mục AWS, lần này giúp người dùng xử lý dữ liệu chuỗi thời gian đến từ các nguồn như thiết bị Internet of Things hoặc các dịch vụ được giám sát. Nó cũng có thể được sử dụng để lưu trữ các số liệu thu được từ nhật ký được tạo bởi nhiều dịch vụ, cho phép người dùng chạy các truy vấn phân tích trên chúng, giúp hiểu các mẫu và điều kiện mà các dịch vụ hoạt động.
Dòng thời gian, như hầu hết các dịch vụ AWS, cung cấp một cách dễ dàng mở rộng quy mô nếu nhu cầu lưu trữ và phân tích dữ liệu tăng lên theo thời gian.
Như bạn có thể thấy, có rất nhiều lựa chọn trên thị trường và điều này không có gì đáng ngạc nhiên. Phân tích dữ liệu chuỗi thời gian đang ngày càng trở nên thu hút hơn trong thời gian gần đây, nó ngày càng trở nên quan trọng hơn đối với hoạt động kinh doanh. May mắn thay, với số lượng lớn các dịch vụ, cả mã nguồn mở và thương mại, rất có thể bạn có thể tìm thấy một công cụ phù hợp với nhu cầu của mình.