Trở lại năm 2014, tôi đã viết một bài báo có tên Điều chỉnh Hiệu suất Toàn bộ Kế hoạch Truy vấn. Nó đã xem xét các cách để tìm một số lượng tương đối nhỏ các giá trị khác biệt từ một tập dữ liệu lớn vừa phải và kết luận rằng một giải pháp đệ quy có thể là tối ưu. Bài đăng tiếp theo này sẽ xem lại câu hỏi cho SQL Server 2019, sử dụng số lượng hàng lớn hơn.
Môi trường thử nghiệm
Tôi sẽ sử dụng cơ sở dữ liệu 50GB Stack Overflow 2013, nhưng bất kỳ bảng lớn nào có số lượng giá trị khác biệt thấp sẽ làm được.
Tôi sẽ tìm kiếm các giá trị khác biệt trong BountyAmount cột của dbo.Votes bảng, được trình bày theo thứ tự số tiền thưởng tăng dần. Bảng Bầu chọn chỉ có dưới 53 triệu hàng (chính xác là 52,928,720). Chỉ có 19 số tiền thưởng khác nhau, bao gồm NULL .
Cơ sở dữ liệu Stack Overflow 2013 không có chỉ mục riêng để giảm thiểu thời gian tải xuống. Có một chỉ mục khóa chính được phân nhóm trên Id cột của dbo.Votes bàn. Nó được đặt thành khả năng tương thích của SQL Server 2008 (cấp 100), nhưng chúng tôi sẽ bắt đầu với cài đặt hiện đại hơn của SQL Server 2017 (cấp 140):
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
Các bài kiểm tra được thực hiện trên máy tính xách tay của tôi sử dụng SQL Server 2019 CU 2. Máy này có bốn CPU i7 (siêu phân luồng lên 8) với tốc độ cơ bản là 2,4 GHz. Nó có RAM 32 GB, với 24 GB có sẵn cho phiên bản SQL Server 2019. Ngưỡng chi phí cho tính song song được đặt thành 50.
Mỗi kết quả thử nghiệm thể hiện kết quả tốt nhất trong số mười lần chạy, với tất cả dữ liệu bắt buộc và các trang chỉ mục trong bộ nhớ.
1. Chỉ mục theo cụm cửa hàng theo hàng
Để đặt đường cơ sở, lần chạy đầu tiên là một truy vấn nối tiếp mà không có bất kỳ lập chỉ mục mới nào (và hãy nhớ điều này là với cơ sở dữ liệu được đặt thành mức tương thích 140):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1);
Thao tác này quét chỉ mục được phân nhóm và sử dụng tổng hợp hàm băm ở chế độ hàng để tìm các giá trị riêng biệt của BountyAmount :
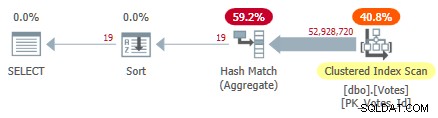 Kế hoạch chỉ mục theo nhóm nối tiếp
Kế hoạch chỉ mục theo nhóm nối tiếp
Quá trình này mất 10.500 mili giây để hoàn thành, sử dụng cùng một lượng thời gian CPU. Hãy nhớ rằng đây là thời gian tốt nhất trong hơn mười lần chạy với tất cả dữ liệu trong bộ nhớ. Thống kê lấy mẫu được tạo tự động trên BountyAmount đã được tạo trong lần chạy đầu tiên.
Khoảng một nửa thời gian đã trôi qua dành cho Quét chỉ mục theo cụm và khoảng một nửa cho Tổng hợp đối sánh băm. Sắp xếp chỉ có 19 hàng để xử lý, vì vậy nó chỉ tiêu tốn 1ms hoặc lâu hơn. Tất cả các toán tử trong kế hoạch này sử dụng thực thi chế độ hàng.
Xóa MAXDOP 1 gợi ý đưa ra một kế hoạch song song:
 Kế hoạch chỉ mục nhóm song song
Kế hoạch chỉ mục nhóm song song
Đây là kế hoạch mà trình tối ưu hóa chọn mà không có bất kỳ gợi ý nào trong cấu hình của tôi. Nó trả về kết quả sau 4.200 mili giây sử dụng tổng cộng 32.800ms CPU (ở DOP 8).
2. Chỉ mục không phân biệt
Quét toàn bộ bảng để chỉ tìm BountyAmount có vẻ không hiệu quả, vì vậy việc thử thêm chỉ mục không phân biệt chỉ trên một cột mà truy vấn này cần:là điều đương nhiên.
CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
Chỉ số này cần một khoảng thời gian để tạo ra (1m 40s). MAXDOP 1 hiện tại truy vấn sử dụng Tổng hợp luồng vì trình tối ưu hóa có thể sử dụng chỉ mục không phân bổ để trình bày các hàng trong BountyAmount đặt hàng:
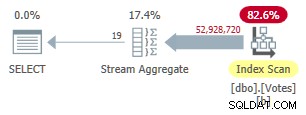 Kế hoạch chế độ hàng không phân biệt theo chuỗi
Kế hoạch chế độ hàng không phân biệt theo chuỗi
Điều này chạy trong 9.300 mili giây (tiêu tốn cùng một lượng thời gian của CPU). Một cải tiến hữu ích trên 10.500ms ban đầu nhưng hầu như không gây vỡ.
Xóa MAXDOP 1 gợi ý đưa ra một kế hoạch song song với tổng hợp cục bộ (mỗi luồng):
 Kế hoạch chế độ hàng không phân biệt song song
Kế hoạch chế độ hàng không phân biệt song song
Quá trình này thực thi sau 3.400 mili giây sử dụng 25.800ms thời gian CPU. Chúng tôi có thể làm tốt hơn với việc nén hàng hoặc trang trên chỉ mục mới, nhưng tôi muốn chuyển sang các tùy chọn thú vị hơn.
3. Chế độ hàng loạt trên Row Store (BMOR)
Bây giờ, hãy đặt cơ sở dữ liệu sang chế độ tương thích SQL Server 2019 bằng cách sử dụng:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
Điều này cho phép trình tối ưu hóa tự do chọn chế độ hàng loạt trên cửa hàng hàng nếu nó cho là đáng giá. Điều này có thể cung cấp một số lợi ích của việc thực thi chế độ hàng loạt mà không yêu cầu chỉ mục lưu trữ cột. Để biết chi tiết kỹ thuật sâu và các tùy chọn không có tài liệu, hãy xem bài viết xuất sắc của Dmitry Pilugin về chủ đề này.
Thật không may, trình tối ưu hóa vẫn chọn thực thi chế độ hàng đầy đủ bằng cách sử dụng tổng hợp luồng cho cả truy vấn kiểm tra nối tiếp và song song. Để có được chế độ hàng loạt trong kế hoạch thực thi cửa hàng hàng, chúng tôi có thể thêm một gợi ý để khuyến khích tổng hợp bằng cách sử dụng kết hợp băm (có thể chạy ở chế độ hàng loạt):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); Điều này cung cấp cho chúng tôi một kế hoạch với tất cả các toán tử đang chạy ở chế độ hàng loạt:
 Chế độ hàng loạt nối tiếp trên Kế hoạch cửa hàng hàng
Chế độ hàng loạt nối tiếp trên Kế hoạch cửa hàng hàng
Kết quả được trả về sau 2.600 mili giây (tất cả CPU như bình thường). Điều này đã nhanh hơn so với song song kế hoạch chế độ hàng (3.400 mili giây đã trôi qua) trong khi sử dụng CPU ít hơn nhiều (2.600 mili giây so với 25.800 mili giây).
Xóa MAXDOP 1 gợi ý (nhưng vẫn giữ HASH GROUP ) cung cấp chế độ hàng loạt song song trên gói hàng lưu trữ:
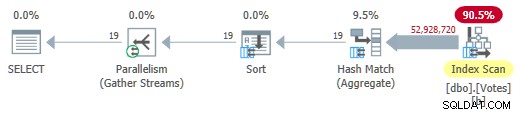 Chế độ hàng loạt song song trên Kế hoạch cửa hàng hàng
Chế độ hàng loạt song song trên Kế hoạch cửa hàng hàng
Điều này chạy chỉ trong 725 mili giây sử dụng 5.700ms CPU.
4. Chế độ Batch trên Column Store
Chế độ hàng loạt song song trên kết quả cửa hàng theo hàng là một cải tiến ấn tượng. Chúng tôi thậm chí có thể làm tốt hơn nữa bằng cách cung cấp đại diện lưu trữ theo cột của dữ liệu. Để giữ nguyên mọi thứ khác, tôi sẽ thêm một không bao gồm chỉ mục lưu trữ cột chỉ trên cột chúng ta cần:
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
Điều này được điền từ chỉ mục không phân tán b-tree hiện có và chỉ mất 15 giây để tạo.
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); Trình tối ưu hóa chọn gói chế độ hàng loạt hoàn toàn bao gồm quét chỉ mục cửa hàng cột:
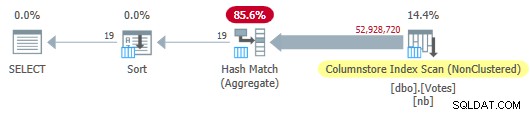 Sơ đồ cửa hàng theo cột
Sơ đồ cửa hàng theo cột
Quá trình này chạy trong 115 mili giây sử dụng cùng một lượng thời gian CPU. Trình tối ưu hóa chọn gói này mà không có bất kỳ gợi ý nào về cấu hình hệ thống của tôi vì chi phí ước tính của gói nằm dưới ngưỡng chi phí cho tính song song .
Để có được gói song song, chúng tôi có thể giảm ngưỡng chi phí hoặc sử dụng gợi ý không có tài liệu:
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); Trong mọi trường hợp, kế hoạch song song là:
 Sơ đồ cửa hàng dạng cột song song
Sơ đồ cửa hàng dạng cột song song
Thời gian đã trôi qua của truy vấn hiện giảm xuống còn 30 mili giây , trong khi tiêu thụ 210ms CPU.
5. Chế độ hàng loạt trên Cửa hàng cột với Đẩy xuống
Thời gian thực thi tốt nhất hiện tại là 30ms là rất ấn tượng, đặc biệt là khi so sánh với 10.500ms ban đầu. Tuy nhiên, có một chút xấu hổ khi chúng ta phải chuyển gần 53 triệu hàng (trong 58.868 lô) từ Quét đến Tổng hợp Đối sánh Hash.
Sẽ thật tuyệt nếu SQL Server có thể đẩy tổng hợp xuống quá trình quét và chỉ trả về các giá trị riêng biệt từ cột lưu trữ trực tiếp. Bạn có thể nghĩ rằng chúng tôi cần diễn đạt DISTINCT với tư cách là GROUP BY để có được Đẩy xuống tổng hợp theo nhóm, nhưng điều đó là dư thừa về mặt logic và không phải toàn bộ câu chuyện trong mọi trường hợp.
Với việc triển khai SQL Server hiện tại, chúng tôi thực sự cần tính toán tổng hợp để kích hoạt tổng hợp đẩy xuống. Hơn thế nữa, chúng ta cần sử dụng kết quả tổng hợp bằng cách nào đó hoặc trình tối ưu hóa sẽ loại bỏ nó khi không cần thiết.
Một cách để viết truy vấn để đạt được tổng hợp đẩy xuống là thêm yêu cầu sắp xếp thứ cấp dư thừa về mặt logic:
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); Kế hoạch nối tiếp bây giờ là:
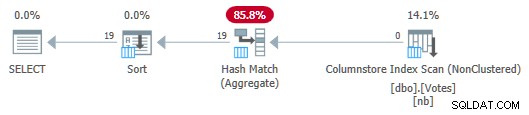 Kế hoạch cửa hàng theo cột với tổng hợp đẩy xuống
Kế hoạch cửa hàng theo cột với tổng hợp đẩy xuống
Lưu ý rằng không có hàng nào được chuyển từ Quét sang Tổng hợp! Dưới trang bìa, tổng hợp một phần của BountyAmount các giá trị và số lượng hàng liên quan của chúng được chuyển đến Tổng hợp đối sánh băm, tổng hợp các tổng hợp từng phần để tạo thành tổng hợp cuối cùng (toàn cầu) được yêu cầu. Điều này rất hiệu quả, đã được xác nhận bởi thời gian đã trôi qua là 13 mili giây (tất cả đều là thời gian của CPU). Xin nhắc lại, gói nối tiếp trước đó mất 115 mili giây.
Để hoàn thành bộ này, chúng ta có thể lấy một phiên bản song song theo cách giống như trước đây:
 Kế hoạch cửa hàng theo cột song song với tổng hợp đẩy xuống
Kế hoạch cửa hàng theo cột song song với tổng hợp đẩy xuống
Điều này chạy trong 7ms sử dụng tổng cộng 40ms CPU.
Thật xấu hổ là chúng ta cần phải tính toán và sử dụng một tổng hợp mà chúng ta không cần chỉ để bị đẩy xuống. Có lẽ điều này sẽ được cải thiện trong tương lai để DISTINCT và GROUP BY không có tập hợp có thể được đẩy xuống quét.
6. Chế độ hàng Biểu thức bảng chung đệ quy
Lúc đầu, tôi đã hứa sẽ xem lại giải pháp CTE đệ quy được sử dụng để tìm một số lượng nhỏ các bản sao trong một tập dữ liệu lớn. Việc thực hiện yêu cầu hiện tại bằng cách sử dụng kỹ thuật đó khá đơn giản, mặc dù mã nhất thiết phải dài hơn bất kỳ thứ gì chúng ta đã thấy cho đến thời điểm này:
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0); Ý tưởng bắt nguồn từ cái gọi là quét bỏ qua chỉ mục:Chúng tôi tìm giá trị quan tâm thấp nhất ở đầu chỉ mục cây b có thứ tự tăng dần, sau đó tìm giá trị tiếp theo theo thứ tự chỉ mục, v.v. Cấu trúc của chỉ mục b-tree giúp cho việc tìm kiếm giá trị cao nhất tiếp theo trở nên rất hiệu quả - không cần phải quét qua các bản sao.
Bí quyết thực sự duy nhất ở đây là thuyết phục trình tối ưu hóa cho phép chúng tôi sử dụng TOP trong phần 'đệ quy' của CTE để trả về một bản sao của mỗi giá trị riêng biệt. Vui lòng xem bài viết trước của tôi nếu bạn cần cập nhật chi tiết.
Kế hoạch thực hiện (được Craig Freedman giải thích chung ở đây) là:
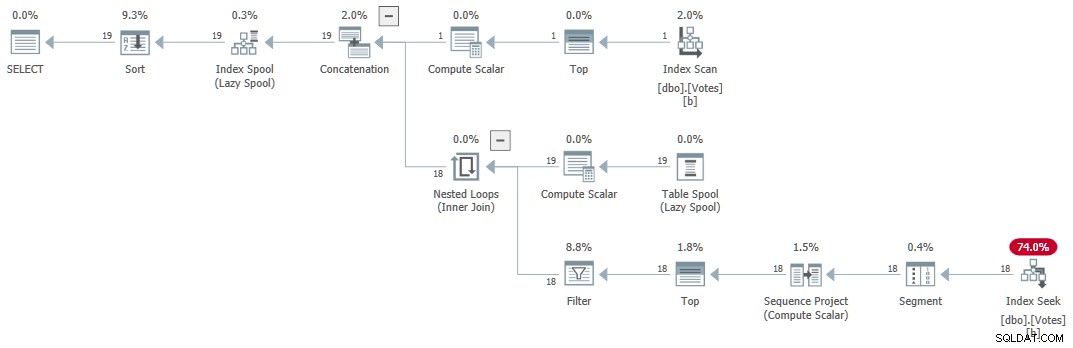 CTE đệ quy nối tiếp
CTE đệ quy nối tiếp
Truy vấn trả về kết quả chính xác trong 1ms sử dụng 1ms CPU, theo Sentry One Plan Explorer.
7. T-SQL lặp lại
Logic tương tự có thể được thể hiện bằng cách sử dụng WHILE vòng. Mã có thể dễ đọc và dễ hiểu hơn CTE đệ quy. Nó cũng tránh phải sử dụng các thủ thuật để giải quyết nhiều hạn chế đối với phần đệ quy của CTE. Hiệu suất cạnh tranh ở mức khoảng 15ms. Mã này được cung cấp để quan tâm và không có trong bảng tóm tắt hiệu suất.
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount; Bảng Tóm lược Hiệu suất
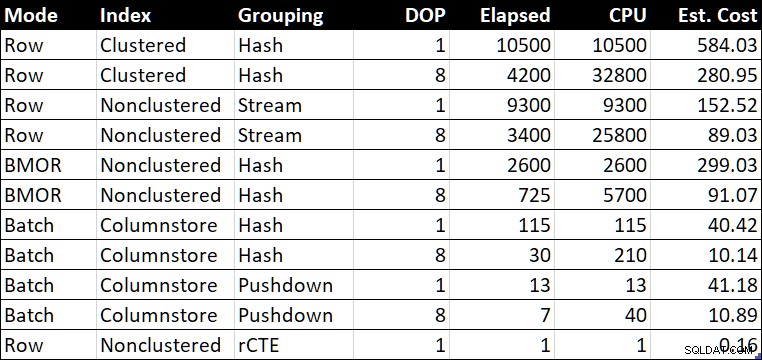 Bảng tóm tắt hiệu suất (thời lượng / CPU tính bằng mili giây)
Bảng tóm tắt hiệu suất (thời lượng / CPU tính bằng mili giây)
Ước. Cột Chi phí ”hiển thị ước tính chi phí của trình tối ưu hóa cho mỗi truy vấn như được báo cáo trên hệ thống thử nghiệm.
Kết luận
Tìm một số lượng nhỏ các giá trị riêng biệt có vẻ là một yêu cầu khá cụ thể, nhưng tôi đã gặp nó khá thường xuyên trong nhiều năm, thường là một phần của việc điều chỉnh một truy vấn lớn hơn.
Một số ví dụ cuối cùng khá gần về hiệu suất. Nhiều người sẽ hài lòng với bất kỳ kết quả phụ thứ hai nào, tùy thuộc vào mức độ ưu tiên. Ngay cả chế độ hàng loạt nối tiếp trên kết quả lưu trữ hàng 2.600ms cũng so sánh tốt với chế độ song song tốt nhất kế hoạch chế độ hàng, báo hiệu tốt cho việc tăng tốc đáng kể chỉ bằng cách nâng cấp lên SQL Server 2019 và bật khả năng tương thích cơ sở dữ liệu mức 150. Không phải ai cũng có thể nhanh chóng di chuyển sang bộ nhớ lưu trữ cột và nó không phải lúc nào cũng là giải pháp phù hợp . Chế độ hàng loạt trên cửa hàng hàng cung cấp một cách gọn gàng để đạt được một số lợi nhuận có thể có với cửa hàng cột, giả sử bạn có thể thuyết phục trình tối ưu hóa chọn sử dụng nó.
Tổng hợp lưu trữ cột song song kết quả đẩy xuống của 57 triệu hàng được xử lý trong 7ms (sử dụng 40ms CPU) là đáng chú ý, đặc biệt là xem xét phần cứng. Kết quả đẩy xuống tổng hợp nối tiếp là 13ms cũng ấn tượng không kém. Sẽ thật tuyệt nếu tôi không phải thêm một kết quả tổng hợp vô nghĩa để có được những kế hoạch này.
Đối với những người chưa thể chuyển sang SQL Server 2019 hoặc lưu trữ dạng cột, CTE đệ quy vẫn là giải pháp khả thi và hiệu quả khi tồn tại chỉ mục b-tree phù hợp và số lượng giá trị riêng biệt cần thiết được đảm bảo là khá nhỏ. Sẽ thật tuyệt nếu SQL Server có thể truy cập một b-tree như thế này mà không cần viết CTE đệ quy (hoặc mã T-SQL lặp đi lặp lại tương đương bằng cách sử dụng WHILE ).
Một giải pháp khả thi khác cho vấn đề là tạo một dạng xem được lập chỉ mục. Điều này sẽ cung cấp các giá trị khác biệt với hiệu quả tuyệt vời. Mặt bên dưới, như thường lệ, là mỗi thay đổi đối với bảng bên dưới sẽ cần cập nhật số hàng được lưu trữ trong chế độ xem cụ thể hóa.
Mỗi giải pháp được trình bày ở đây đều có vị trí của nó, tùy thuộc vào yêu cầu. Có sẵn một loạt các công cụ nói chung là một điều tốt khi điều chỉnh các truy vấn. Hầu hết thời gian, tôi sẽ chọn một trong các giải pháp chế độ hàng loạt vì hiệu suất của chúng sẽ khá dễ đoán cho dù có bao nhiêu bản sao.