SQL Server 2014 SP2 trở lên tạo kế hoạch thực thi thời gian chạy (“thực tế”) có thể bao gồm thời gian đã trôi qua và mức sử dụng CPU cho từng toán tử kế hoạch thực thi (xem KB3170113 và bài đăng trên blog này của Pedro Lopes).
Việc diễn giải những con số này không phải lúc nào cũng đơn giản như người ta có thể mong đợi. Có sự khác biệt quan trọng giữa chế độ hàng và chế độ hàng loạt thực thi, cũng như các vấn đề phức tạp với chế độ hàng song song . SQL Server thực hiện một số điều chỉnh về thời gian trong các kế hoạch song song để thúc đẩy tính nhất quán, nhưng chúng không được thực hiện một cách hoàn hảo. Điều này có thể gây khó khăn trong việc đưa ra kết luận điều chỉnh hiệu suất âm thanh.
Bài viết này nhằm giúp bạn hiểu thời gian đến từ đâu trong mỗi trường hợp và cách chúng có thể được diễn giải tốt nhất theo ngữ cảnh.
Thiết lập
Các ví dụ sau sử dụng Stack Overflow 2013 công khai cơ sở dữ liệu (chi tiết tải xuống), với một chỉ mục duy nhất được thêm vào:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
Các truy vấn kiểm tra trả về số lượng câu hỏi có câu trả lời được chấp nhận, được nhóm theo tháng và năm. Chúng được chạy trên SQL Server 2019 CU9 , trên máy tính xách tay có 8 lõi và 16GB bộ nhớ được phân bổ cho phiên bản SQL Server 2019. Mức độ tương thích 150 được sử dụng riêng.
Thực thi nối tiếp chế độ hàng loạt
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Kế hoạch thực hiện là (bấm để phóng to):
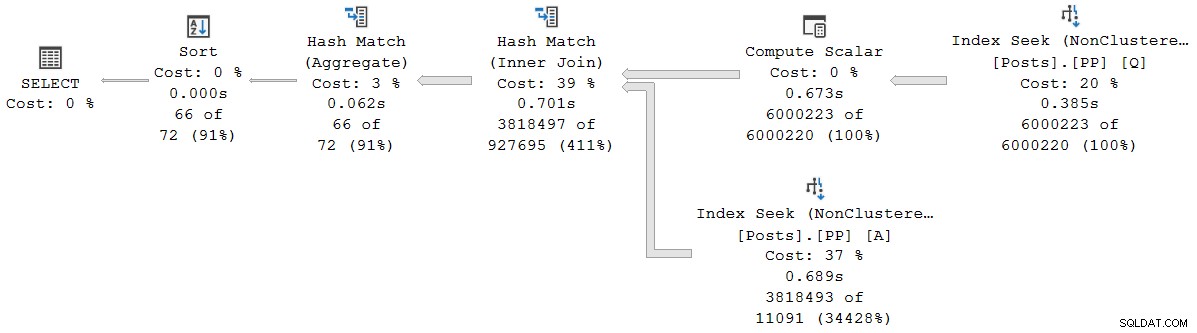
Mọi toán tử trong gói này đều chạy ở chế độ hàng loạt, nhờ vào chế độ hàng loạt trên cửa hàng hàng Tính năng xử lý truy vấn thông minh trong SQL Server 2019 (không cần chỉ mục kho hàng). Truy vấn chạy trong 2,523 mili giây với thời gian sử dụng CPU 2,522ms, khi tất cả dữ liệu cần thiết đã có trong vùng đệm.
Như ghi chú của Pedro Lopes trong bài đăng blog được liên kết trước đó, thời gian đã trôi qua và thời gian CPU được báo cáo cho chế độ hàng loạt riêng lẻ toán tử đại diện cho thời gian được sử dụng bởi chỉ riêng toán tử đó .
SSMS hiển thị thời gian đã trôi qua trong biểu diễn đồ họa. Để xem thời gian CPU , chọn toán tử gói, sau đó tìm trong Thuộc tính cửa sổ. Chế độ xem chi tiết này hiển thị cả thời gian đã trôi qua và thời gian CPU, mỗi toán tử và mỗi luồng.
Thời gian trình chiếu (bao gồm cả biểu diễn XML) bị cắt ngắn đến mili giây. Nếu bạn cần độ chính xác cao hơn, hãy sử dụng query_thread_profile sự kiện mở rộng, báo cáo trong micro giây . Kết quả từ sự kiện này cho kế hoạch thực thi được hiển thị ở trên là:
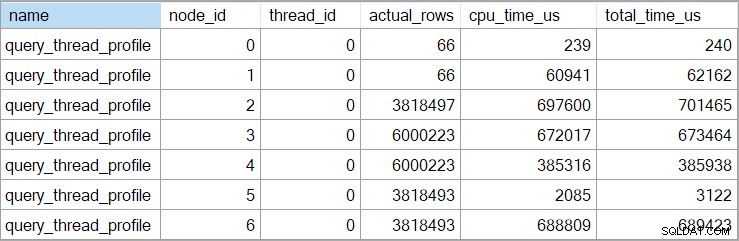
Điều này cho thấy thời gian đã trôi qua cho tham gia (nút 2) là 701.465µs (được cắt ngắn còn 701ms trong chương trình). Tập hợp có thời gian trôi qua là 62,162µs (62ms). Tìm kiếm chỉ mục 'câu hỏi' được hiển thị khi đang chạy trong 385 mili giây, trong khi sự kiện mở rộng cho thấy con số thực của nút 4 là 385,938µs (rất gần 386 mili giây).
SQL Server sử dụng độ chính xác cao QueryPerformanceCounter API để nắm bắt dữ liệu thời gian. Điều này sử dụng phần cứng, thường là một bộ dao động tinh thể, tạo ra các tích tắc ở tốc độ không đổi rất cao bất kể tốc độ bộ xử lý, cài đặt nguồn hoặc bất kỳ thứ gì có tính chất đó. Đồng hồ tiếp tục chạy với tốc độ như nhau ngay cả trong khi ngủ. Xem bài viết rất chi tiết được liên kết nếu bạn quan tâm đến tất cả các chi tiết tốt hơn. Tóm tắt ngắn gọn là bạn có thể tin tưởng những con số micro giây là chính xác.
Trong kế hoạch chế độ lô thuần túy này, tổng thời gian thực hiện rất gần với tổng thời gian đã trôi qua của nhà điều hành riêng lẻ. Sự khác biệt chủ yếu là do công việc hậu báo cáo không được liên kết với toán tử kế hoạch (tất cả đã đóng cửa vào thời điểm đó), mặc dù việc cắt bớt phần nghìn giây cũng đóng một phần.
Trong các gói chế độ hàng loạt thuần túy, bạn cần tính tổng thời gian của nhà điều hành con và hiện tại theo cách thủ công để nhận được tích lũy thời gian đã trôi qua tại bất kỳ nút nhất định nào.
Thực thi song song ở chế độ hàng loạt
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Kế hoạch thực hiện là:
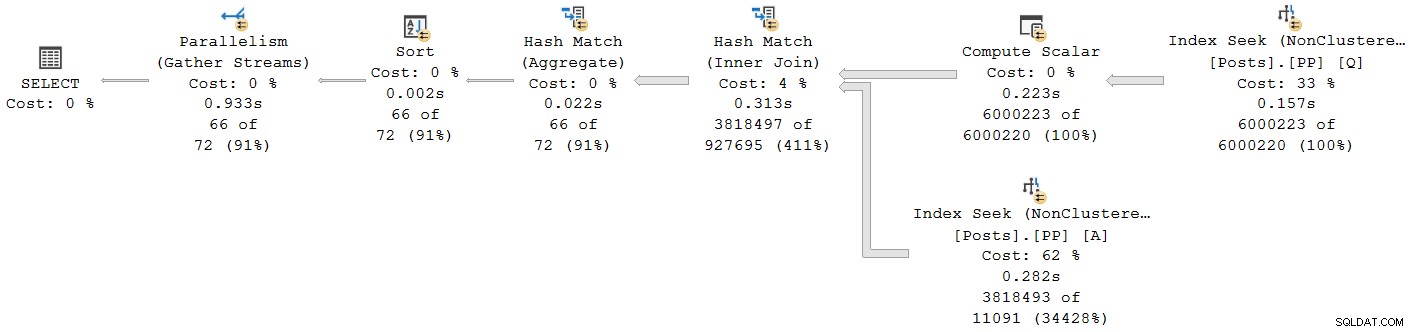
Mọi nhà điều hành ngoại trừ trao đổi luồng thu thập cuối cùng chạy ở chế độ hàng loạt. Tổng thời gian đã trôi qua là 933 mili giây với thời gian CPU là 6.673 mili giây với bộ nhớ đệm ấm.
Chọn tham gia băm và tìm trong SSMS Thuộc tính cửa sổ, chúng tôi thấy thời gian đã trôi qua và thời gian CPU trên mỗi luồng cho toán tử đó:
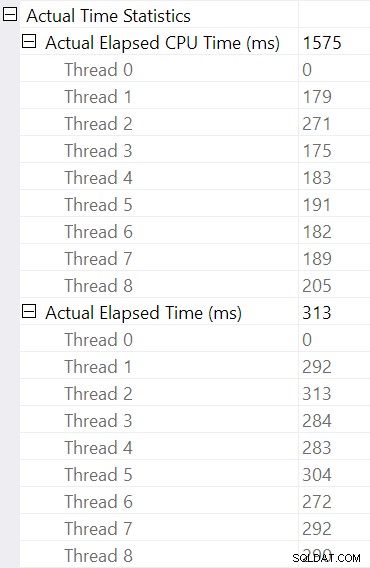
Thời gian CPU được báo cáo cho nhà điều hành là tổng số lần CPU luồng riêng lẻ. Nhà điều hành đã báo cáo thời gian đã trôi qua là tối đa trong số thời gian đã trôi qua của mỗi chủ đề. Cả hai phép tính đều được thực hiện trên các giá trị mili giây bị cắt ngắn trên mỗi luồng. Như trước đây, tổng thời gian thực hiện rất gần với tổng thời gian đã trôi qua của toán tử riêng lẻ.
Chế độ hàng loạt kế hoạch song song không sử dụng trao đổi để phân phối công việc giữa các luồng. Toán tử hàng loạt được triển khai để nhiều luồng có thể hoạt động hiệu quả trên một cấu trúc dùng chung (ví dụ:bảng băm). Một số đồng bộ hóa giữa các luồng vẫn được yêu cầu trong các kế hoạch song song ở chế độ hàng loạt, nhưng các điểm đồng bộ và các chi tiết khác không hiển thị trong đầu ra chương trình.
Thực thi nối tiếp chế độ hàng
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Kế hoạch thực thi trông giống như kế hoạch nối tiếp chế độ hàng loạt, nhưng mọi toán tử hiện đang chạy ở chế độ hàng:
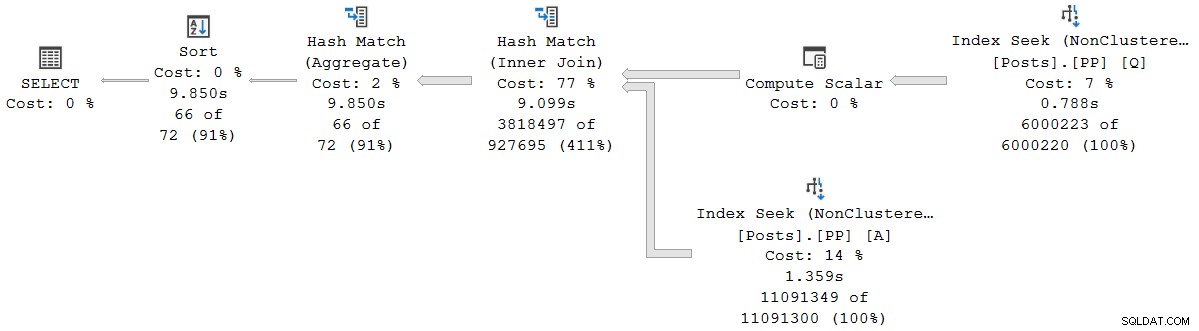
Truy vấn chạy trong 9,850ms với thời gian CPU 9,845ms. Điều này chậm hơn rất nhiều so với truy vấn chế độ hàng loạt nối tiếp (2523ms / 2522ms), như mong đợi. Quan trọng hơn đối với cuộc thảo luận hiện tại, chế độ hàng toán tử đã trôi qua và thời gian CPU đại diện cho thời gian được sử dụng bởi toán tử hiện tại và tất cả các toán tử con .
Sự kiện mở rộng cũng hiển thị CPU tích lũy và thời gian đã trôi qua tại mỗi nút (tính bằng micro giây):
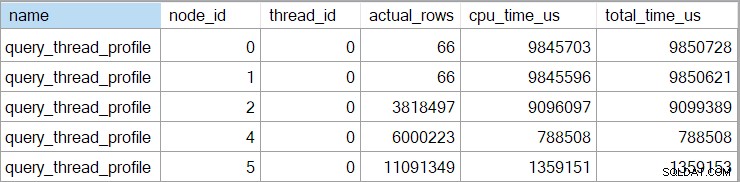
Không có dữ liệu cho toán tử vô hướng máy tính (nút 3) vì việc thực thi chế độ hàng có thể trì hoãn hầu hết các phép tính biểu thức cho toán tử sử dụng kết quả. Điều này hiện không được triển khai để thực thi chế độ hàng loạt.
Báo cáo tích lũy thời gian đã trôi qua cho toán tử chế độ hàng có nghĩa là thời gian hiển thị cho toán tử sắp xếp cuối cùng khớp chặt chẽ với tổng thời gian thực thi cho truy vấn (dù sao cũng là độ phân giải mili giây). Thời gian đã trôi qua cho phép tham gia băm cũng bao gồm các đóng góp từ hai chỉ mục tìm kiếm bên dưới nó, cũng như thời gian của chính nó. Để tính toán thời gian đã trôi qua đối với riêng phép tham gia băm ở chế độ hàng, chúng tôi sẽ cần phải trừ đi cả hai lần tìm kiếm từ nó.
Có những ưu điểm và nhược điểm đối với cả hai bản trình bày (tích lũy cho chế độ hàng, nhà điều hành riêng lẻ chỉ cho chế độ hàng loạt). Cho dù bạn thích cái nào, điều quan trọng là phải nhận thức được sự khác biệt.
Các kế hoạch chế độ thực thi hỗn hợp
Nói chung, các kế hoạch thực thi hiện đại có thể chứa bất kỳ hỗn hợp nào của các toán tử chế độ hàng và chế độ hàng loạt. Các nhà khai thác chế độ hàng loạt sẽ báo cáo thời gian chỉ cho chính họ. Các toán tử chế độ hàng sẽ bao gồm tổng tích lũy cho đến thời điểm đó trong kế hoạch, bao gồm tất cả toán tử con. Để làm rõ hơn về điều này:thời gian tích lũy của nhà điều hành chế độ hàng bao gồm bất kỳ toán tử con nào của chế độ hàng loạt.
Chúng tôi đã thấy điều này trước đây trong kế hoạch chế độ hàng loạt song song:Toán tử tập hợp luồng cuối cùng (chế độ hàng) có thời gian trôi qua được hiển thị (tích lũy) là 0,933 giây - bao gồm tất cả các toán tử chế độ hàng loạt con của nó. Các nhà khai thác khác đều ở chế độ hàng loạt và do đó, thời gian được báo cáo chỉ dành cho nhà điều hành riêng lẻ.
Tình huống này, trong đó một số nhà khai thác kế hoạch trong cùng một kế hoạch có thời gian tích lũy và những thời gian khác thì không, chắc chắn sẽ bị coi là khó hiểu bởi nhiều người.
Thực thi song song ở chế độ hàng
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Kế hoạch thực hiện là:

Mỗi nhà điều hành là chế độ hàng. Truy vấn chạy trong 4,677ms với thời gian CPU là 23.311ms (tổng tất cả các luồng).
Là một kế hoạch chế độ hàng độc quyền, chúng tôi mong đợi mọi lúc đều được tích lũy . Chuyển từ con sang cha (phải sang trái), thời gian phải tăng lên theo hướng đó.
Hãy xem phần ngoài cùng bên phải của kế hoạch:
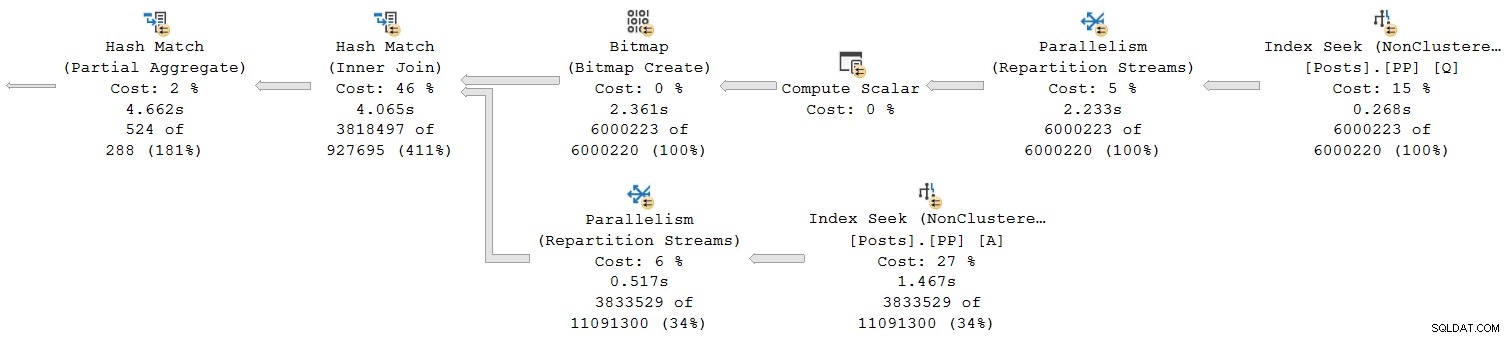
Làm việc từ phải sang trái ở hàng trên cùng, thời gian tích lũy dường như đúng như vậy. Nhưng có một ngoại lệ ở đầu vào thấp hơn cho phép nối băm:Tìm kiếm chỉ mục có thời gian trôi qua là 1,467 giây , trong khi cha mẹ của nó luồng phân vùng lại có thời gian trôi qua chỉ 0,517 giây .
Làm thế nào để cha mẹ toán tử chạy trong ít thời gian hơn hơn đứa con của nó nếu thời gian đã trôi qua có được tích lũy trong các kế hoạch chế độ hàng không?
Thời gian không nhất quán
Có một số phần cho câu trả lời cho câu đố này. Chúng ta hãy giải quyết từng phần một, vì nó khá phức tạp:
Đầu tiên, hãy nhớ lại rằng một trao đổi (toán tử song song) có hai phần. Bên trái ( người tiêu dùng ) bên được kết nối với một tập hợp các toán tử đang chạy trong nhánh song song bên trái. Cánh tay phải ( nhà sản xuất ) phía của sàn giao dịch được kết nối với một tập hợp các chuỗi khác chạy các toán tử trong nhánh song song ở bên phải.
Các hàng từ phía nhà sản xuất được tập hợp thành gói và sau đó được chuyển giao cho phía người tiêu dùng. Điều này cung cấp một mức độ đệm và kiểm soát luồng giữa hai tập hợp các chủ đề được kết nối. (Nếu bạn cần cập nhật về các sàn giao dịch và các nhánh kế hoạch song song, vui lòng xem bài viết của tôi Kế hoạch Thực hiện Song song - Nhánh và Chủ đề.)
Phạm vi thời gian tích lũy
Nhìn vào nhánh song song trên nhà sản xuất bên giao dịch:
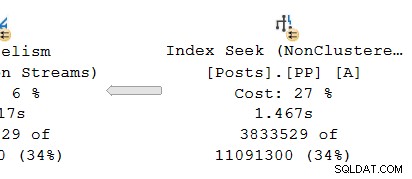
Như thường lệ, các luồng nhân viên bổ sung DOP (mức độ song song) chạy một nối tiếp độc lập bản sao của các nhà khai thác kế hoạch trong nhánh này. Vì vậy, tại DOP 8, có 8 tìm kiếm chỉ mục nối tiếp độc lập cùng hoạt động để thực hiện phần quét phạm vi của hoạt động tìm kiếm chỉ mục tổng thể (song song). Mỗi tìm kiếm đơn luồng được kết nối với một đầu vào (cổng) khác nhau ở phía nhà sản xuất của chia sẻ đơn lẻ nhà điều hành trao đổi.
Tình huống tương tự cũng tồn tại trên người tiêu dùng bên của sàn giao dịch. Tại DOP 8, có 8 bản sao đơn luồng riêng biệt của nhánh này, tất cả đều chạy độc lập:
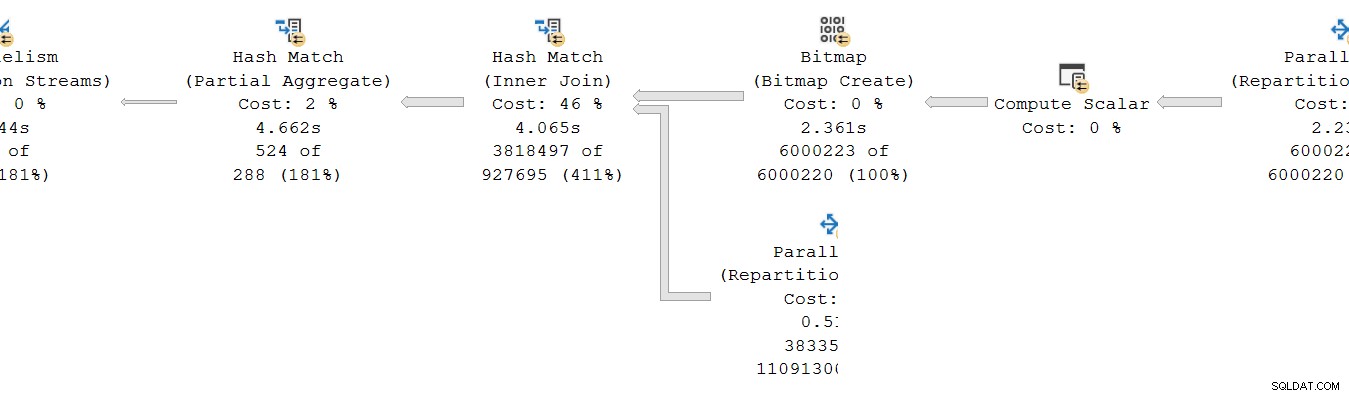
Mỗi kế hoạch con đơn luồng này chạy theo cách thông thường, với mỗi toán tử tích lũy tổng thời gian đã trôi qua và thời gian CPU tại mỗi nút. Là các toán tử chế độ hàng, mỗi tổng thể hiện thời gian dành cho tổng số tích lũy cho nút hiện tại và mỗi nút con của nó.
Điểm quan trọng là tổng số tích lũy chỉ bao gồm các toán tử trên cùng một chuỗi và chỉ trong chi nhánh hiện tại . Hy vọng rằng điều này có ý nghĩa trực quan, bởi vì mỗi chuỗi không có ý tưởng về những gì có thể xảy ra ở nơi khác.
Cách thu thập số liệu của chế độ hàng
Phần thứ hai của câu đố liên quan đến cách số lượng hàng và số liệu thời gian được thu thập trong các kế hoạch chế độ hàng. Khi thông tin kế hoạch thời gian chạy (“thực tế”) là cần thiết, công cụ thực thi sẽ thêm chức năng ẩn toán tử lập hồ sơ ở ngay bên trái (cha) của mọi toán tử trong kế hoạch sẽ được thực thi trong thời gian chạy.
Toán tử này có thể ghi lại (trong số những thứ khác) sự khác biệt giữa thời điểm nó chuyển quyền điều khiển cho toán tử con và thời điểm quyền điều khiển được trả lại. Chênh lệch thời gian này thể hiện thời gian đã trôi qua cho nhà điều hành được giám sát và tất cả các con của họ , vì đứa trẻ gọi vào con của chính nó trên mỗi hàng và cứ tiếp tục như vậy. Một toán tử có thể được gọi nhiều lần (để khởi tạo, sau đó một lần cho mỗi hàng, cuối cùng để đóng) vì vậy thời gian được thu thập bởi toán tử cấu hình là một tích lũy qua nhiều lần lặp lại trên mỗi hàng.
Để biết thêm chi tiết về dữ liệu cấu hình được thu thập bằng các phương pháp thu thập khác nhau, hãy xem tài liệu sản phẩm bao gồm Cơ sở hạ tầng lập hồ sơ truy vấn. Đối với những người quan tâm đến những thứ như vậy, tên của toán tử cấu hình ẩn được sử dụng bởi cơ sở hạ tầng tiêu chuẩn là sqlmin!CQScanProfileNew . Giống như tất cả các trình lặp chế độ hàng, nó có Open , GetRow và Close phương pháp, trong số những phương pháp khác. Mỗi phương thức chứa các lệnh gọi đến Windows QueryPerformanceCounter API để thu thập giá trị bộ hẹn giờ có độ phân giải cao hiện tại.
Vì toán tử cấu hình nằm ở bên trái của nhà điều hành mục tiêu, nó chỉ đo lường người tiêu dùng bên của sàn giao dịch. Không có toán tử lập hồ sơ cho nhà sản xuất mặt của sàn giao dịch (thật đáng buồn). Nếu có, nó sẽ khớp hoặc vượt quá thời gian đã trôi qua được hiển thị trên tìm kiếm chỉ mục, bởi vì tìm kiếm chỉ mục và phía nhà sản xuất đang chạy cùng một tập hợp các luồng và phía nhà sản xuất của trao đổi là nhà điều hành chính của tìm kiếm chỉ mục.
Đã xem lại thời gian

Với tất cả những gì đã nói, bạn vẫn có thể gặp khó khăn với thời gian hiển thị ở trên. Làm cách nào để tìm kiếm chỉ mục có thể mất 1,467 giây để chuyển các hàng vào phía nhà sản xuất của trao đổi, nhưng phía người tiêu dùng chỉ mất 0,517 giây để nhận chúng? Bất kể chuỗi riêng biệt, bộ đệm và nội dung nào khác, chắc chắn trao đổi sẽ chạy (end-to-end) lâu hơn so với tìm kiếm?
Vâng, đúng vậy, nhưng đó là một phép đo khác từ thời gian đã trôi qua hoặc CPU. Hãy nói chính xác về những gì chúng tôi đang đo lường ở đây.
Đối với chế độ hàng thời gian đã trôi qua , hãy tưởng tượng một đồng hồ bấm giờ trên mỗi chuỗi tại mỗi nhà điều hành. Đồng hồ bấm giờ bắt đầu khi SQL Server nhập mã cho toán tử từ cha của nó và dừng lại (nhưng không đặt lại) khi mã đó rời khỏi nhà điều hành để trả lại quyền điều khiển cho cha mẹ (không phải cho con). Thời gian đã trôi qua bao gồm bất kỳ sự chờ đợi hoặc sự chậm trễ nào trong lịch trình - cả hai đều không ngăn được đồng hồ.
Đối với chế độ hàng thời gian CPU , hãy tưởng tượng cùng một chiếc đồng hồ bấm giờ với các đặc điểm giống nhau, ngoại trừ nó dừng trong thời gian chờ đợi và sự chậm trễ trong lịch trình. Nó chỉ tích lũy thời gian khi người vận hành hoặc một trong những người con của nó đang tích cực thực thi trên bộ lập lịch (CPU). Tổng thời gian trên đồng hồ bấm giờ trên mỗi sợi cho mỗi người vận hành được xây dựng dựa trên chu kỳ bắt đầu dừng cho mỗi hàng.
Hãy áp dụng điều đó vào tình huống hiện tại với phía người tiêu dùng của sàn giao dịch và chỉ số tìm kiếm:
Hãy nhớ rằng phía người tiêu dùng của trao đổi và tìm kiếm chỉ mục nằm trong các nhánh riêng biệt, vì vậy họ đang chạy trên các chuỗi riêng biệt . Bên người tiêu dùng không có con nào trong cùng một chủ đề. Tìm kiếm chỉ mục có phía nhà sản xuất của trao đổi là cha mẹ của cùng một chuỗi của nó, nhưng chúng tôi không có đồng hồ bấm giờ ở đó.
Mỗi luồng người tiêu dùng bắt đầu đồng hồ của nó khi toán tử cha của nó (phía thăm dò của phép nối băm) chuyển quyền kiểm soát (ví dụ:để tìm nạp một hàng). Đồng hồ tiếp tục chạy trong khi người tiêu dùng lấy một hàng từ gói trao đổi hiện tại. Đồng hồ dừng khi quyền kiểm soát rời khỏi người tiêu dùng và quay trở lại phía thăm dò tham gia băm. Các bậc cha mẹ khác (tổng hợp một phần và trao đổi chính của nó) cũng sẽ hoạt động trên hàng đó (và có thể đợi) trước khi quyền kiểm soát quay trở lại phía người tiêu dùng của sàn giao dịch của chúng tôi để tìm nạp hàng tiếp theo. Tại thời điểm đó, phía người tiêu dùng của sàn giao dịch của chúng tôi bắt đầu tích lũy thời gian đã trôi qua và thời gian CPU trở lại.
Trong khi đó, độc lập với bất cứ điều gì mà các chuỗi nhánh phía người tiêu dùng có thể đang làm, tìm kiếm chỉ mục các luồng đang tiếp tục xác định vị trí các hàng trong chỉ mục và đưa chúng vào trao đổi. Một chuỗi tìm kiếm chỉ mục bắt đầu đồng hồ bấm giờ của nó khi phía nhà sản xuất của sàn giao dịch yêu cầu nó cho một hàng. Đồng hồ bấm giờ bị tạm dừng khi hàng được chuyển đến sàn giao dịch. Khi sàn giao dịch yêu cầu hàng tiếp theo, đồng hồ bấm giờ tìm kiếm chỉ mục sẽ tiếp tục.
Lưu ý rằng phía nhà sản xuất của sàn giao dịch có thể gặp phải CXPACKET đợi khi bộ đệm trao đổi đầy, nhưng điều đó sẽ không thêm vào thời gian đã trôi qua được ghi lại khi tìm kiếm chỉ mục vì đồng hồ bấm giờ của nó không chạy khi điều đó xảy ra. Nếu chúng tôi có đồng hồ bấm giờ cho phía nhà sản xuất của cuộc trao đổi, thời gian trôi qua bị thiếu sẽ hiển thị ở đó.
Để gần đúng bản tóm tắt của tình huống một cách trực quan, sơ đồ sau cho thấy khi mỗi người vận hành tích lũy thời gian đã trôi qua trong hai nhánh song song:
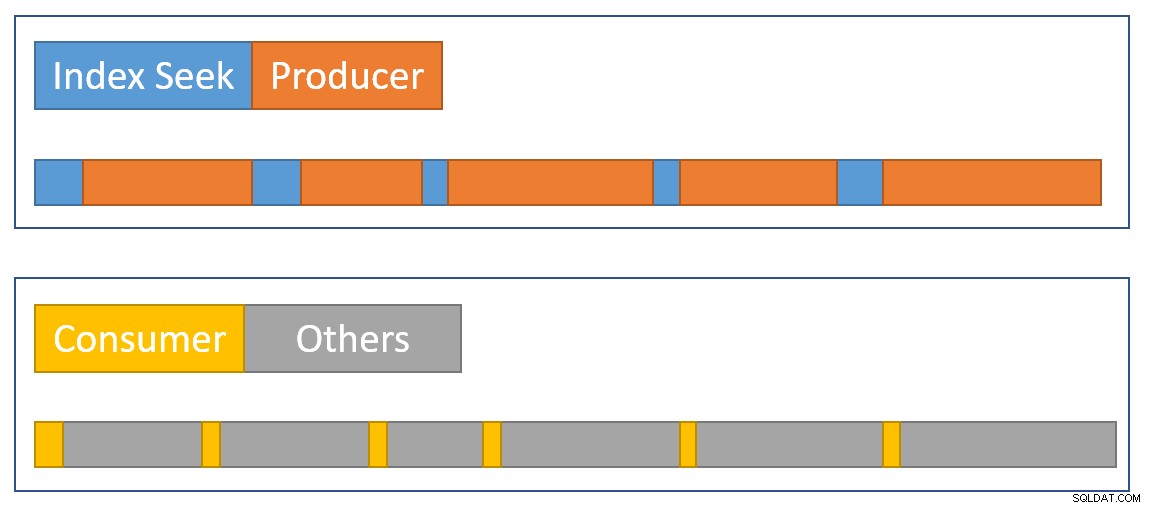
Màu xanh lam Các thanh thời gian tìm kiếm chỉ mục ngắn vì việc tìm nạp một hàng từ một chỉ mục rất nhanh. Màu cam thời gian của nhà sản xuất có thể lâu do CXPACKET chờ đợi. Màu vàng thời gian của người tiêu dùng ngắn vì nhanh chóng lấy một hàng từ sàn giao dịch khi có dữ liệu. Màu xám phân đoạn thời gian đại diện cho thời gian được sử dụng bởi các nhà khai thác khác (phía thăm dò tham gia băm, tổng hợp một phần và phía nhà sản xuất trao đổi mẹ của nó) phía trên phía người tiêu dùng của sàn giao dịch.
Chúng tôi hy vọng các gói trao đổi sẽ được lấp đầy nhanh chóng bởi tìm kiếm chỉ mục, nhưng làm trống chậm (nói một cách tương đối) bởi các nhà khai thác phía người tiêu dùng vì họ còn nhiều việc phải làm. Điều này có nghĩa là các gói trong trao đổi thường sẽ đầy hoặc gần đầy. Người tiêu dùng sẽ có thể nhanh chóng truy xuất một hàng chờ, nhưng nhà sản xuất có thể phải đợi không gian gói xuất hiện.
Thật tiếc là chúng tôi không thể nhìn thấy thời gian đã trôi qua ở phía nhà sản xuất của cuộc trao đổi. Từ lâu, tôi đã có quan điểm rằng một sàn giao dịch nên được đại diện bởi hai các nhà khai thác khác nhau trong các kế hoạch thực thi. Nó sẽ gây khó khăn cho CXPACKET / CXCONSUMER phân tích chờ đợi ít cần thiết hơn nhiều và kế hoạch thực hiện dễ hiểu hơn nhiều. Nhà điều hành nhà sản xuất trao đổi đương nhiên sẽ có nhà điều hành hồ sơ của riêng mình.
Thiết kế thay thế
Có nhiều cách SQL Server có thể đạt được tích lũy nhất quán thời gian đã trôi qua và thời gian CPU qua các nhánh song song về nguyên tắc . Thay vì lập hồ sơ các toán tử, mỗi hàng có thể mang thông tin về thời lượng CPU đã trôi qua và thời gian CPU đã tích lũy cho đến nay trong hành trình thông qua kế hoạch. Với lịch sử được liên kết với mỗi hàng, việc trao đổi phân phối lại các hàng giữa các chuỗi, v.v. sẽ không thành vấn đề.
Đó không phải là cách sản phẩm được thiết kế, vì vậy đó không phải là những gì chúng tôi có (và dù sao thì nó cũng có thể không hiệu quả). Công bằng mà nói, thiết kế chế độ hàng ban đầu chỉ quan tâm đến những thứ như thu thập số lượng hàng thực tế và số lần lặp lại ở mỗi toán tử. Thêm thời gian trôi qua của mỗi nhà điều hành vào các gói là một tính năng được yêu cầu nhiều , nhưng không dễ dàng để kết hợp vào khuôn khổ hiện có.
Khi chế độ xử lý theo lô được thêm vào sản phẩm, một cách tiếp cận khác (chỉ định thời gian cho người vận hành hiện tại) có thể được thực hiện như một phần của quá trình phát triển ban đầu mà không làm hỏng bất kỳ điều gì. Một lần nữa, về nguyên tắc , các toán tử chế độ hàng có thể đã được sửa đổi để hoạt động theo cách giống như các toán tử chế độ hàng loạt, nhưng điều đó sẽ yêu cầu rất nhiều công việc tái cấu trúc mọi toán tử chế độ hàng hiện có. Việc thêm một điểm dữ liệu mới vào các toán tử lập hồ sơ chế độ hàng hiện có dễ dàng hơn nhiều. Với nguồn lực kỹ thuật hạn chế và danh sách dài các cải tiến sản phẩm mong muốn, các thỏa hiệp như thế này thường phải được thực hiện.
Vấn đề thứ hai
Một sự mâu thuẫn thời gian tích lũy khác xảy ra trong kế hoạch hiện tại ở phía bên trái:

Thoạt nhìn, điều này có vẻ giống một vấn đề:Tổng hợp một phần có thời gian trôi qua là 4,662 giây , nhưng trao đổi ở trên nó chỉ chạy trong 2,844 giây . Tất nhiên, cơ chế cơ bản giống như trước đây vẫn được sử dụng, nhưng có một yếu tố quan trọng khác. Một manh mối nằm ở thời gian bằng nhau đáng ngờ được báo cáo cho việc trao đổi tổng hợp, sắp xếp và phân vùng lại luồng.
Bạn có nhớ "điều chỉnh thời gian" mà tôi đã đề cập trong phần giới thiệu không? Đây là nơi những thứ đó xuất hiện. Hãy xem xét từng thời gian đã trôi qua cho các chuỗi ở phía người tiêu dùng của luồng trao đổi phân vùng lại:
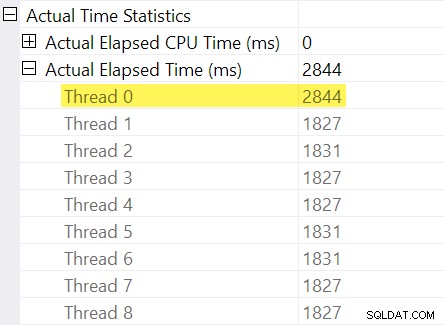
Nhớ lại rằng các kế hoạch hiển thị thời gian đã trôi qua cho toán tử song song là tối đa số lần cho mỗi luồng. Tất cả 8 chủ đề đều có thời gian trôi qua khoảng 1.830 mili giây nhưng có một mục bổ sung cho “Luồng 0” với 2.844 mili giây. Thật vậy mọi nhà điều hành trong nhánh song song này (người tiêu dùng trao đổi, sắp xếp và tổng hợp luồng) có giống nhau Đóng góp 2,844ms từ “Luồng 0”.
Luồng không (hay còn gọi là tác vụ mẹ hoặc điều phối viên) chỉ trực tiếp chạy các toán tử ở bên trái của toán tử luồng thu thập cuối cùng. Tại sao lại có công việc được giao ở đây, trong một nhánh song song?
Giải thích
Sự cố này có thể xảy ra khi có toán tử chặn trong nhánh song song bên dưới (ở bên phải) cái hiện tại. Nếu không có điều chỉnh này, các nhà khai thác trong nhánh hiện tại sẽ báo cáo dưới thời gian đã trôi qua theo khoảng thời gian cần thiết để mở nhánh con (có phức tạp lý do kiến trúc cho điều này).
SQL Server giải quyết vấn đề này bằng cách ghi lại độ trễ nhánh con tại sàn giao dịch trong toán tử lập hồ sơ vô hình. Giá trị thời gian được ghi lại đối với tác vụ chính (“Luồng 0”) về sự khác biệt giữa lần hoạt động đầu tiên và hoạt động gần đây nhất lần. (Ghi lại số theo cách này có vẻ hơi kỳ cục, nhưng tại thời điểm cần ghi lại số, các chuỗi nhân viên song song bổ sung vẫn chưa được tạo).
Trong trường hợp hiện tại, điều chỉnh 2,844 mili giây chủ yếu phát sinh do mất thời gian tham gia băm để xây dựng bảng băm của nó. (Lưu ý thời gian này khác với tổng số thời gian thực hiện của phép nối băm, bao gồm thời gian cần thiết để xử lý phía thăm dò của phép nối).
Nhu cầu điều chỉnh nảy sinh bởi vì một phép nối băm đang chặn trên đầu vào xây dựng của nó. (Điều thú vị là hàm băm tổng hợp một phần trong kế hoạch không được coi là chặn trong ngữ cảnh này vì nó chỉ được gán một lượng bộ nhớ tối thiểu, không bao giờ tràn sang tempdb và chỉ cần dừng tổng hợp nếu nó hết bộ nhớ (do đó quay trở lại chế độ phát trực tuyến). Craig Freedman giải thích điều này trong bài đăng của mình, Tổng hợp một phần).
Cho rằng điều chỉnh thời gian đã trôi qua biểu thị sự chậm trễ khởi tạo trong nhánh con, SQL Server phải để coi giá trị "Luồng 0" là một offset cho các số thời gian đã trôi qua được đo trên mỗi luồng trong nhánh hiện tại. Lấy tối đa của tất cả các luồng vì thời gian đã trôi qua nói chung là hợp lý, vì các luồng có xu hướng bắt đầu cùng một lúc. Nó không không thực hiện điều này hợp lý khi một trong các giá trị luồng là phần bù cho tất cả các giá trị khác!
Chúng tôi có thể thực hiện tính toán bù đắp chính xác thủ công bằng cách sử dụng dữ liệu có sẵn trong kế hoạch. Ở phía người tiêu dùng của sàn giao dịch, chúng tôi có:
Thời gian đã trôi qua tối đa giữa các chuỗi nhân viên bổ sung là 1,831 mili giây (không bao gồm giá trị bù đắp được lưu trữ trong “Chủ đề 0”). Thêm phần bù là 2,844 mili giây cho tổng số 4,675 mili giây .
Trong bất kỳ kế hoạch nào mà thời gian trên mỗi chuỗi ít hơn so với phần bù, toán tử sẽ không chính xác hiển thị phần bù là tổng thời gian đã trôi qua. Điều này có thể xảy ra khi toán tử chặn trước đó chậm (có thể là sắp xếp hoặc tổng hợp toàn cục trên một tập hợp dữ liệu lớn) và toán tử nhánh sau này ít tốn thời gian hơn.
Xem xét lại phần này của kế hoạch:
Thay thế chênh lệch 2,844ms được chỉ định sai cho các toán tử tổng hợp luồng phân vùng lại, sắp xếp và luồng bằng 4,675ms được tính toán của chúng tôi giá trị đặt thời gian đã trôi qua tích lũy của chúng nằm gọn trong khoảng 4,662 mili giây ở tổng một phần và 4,676 mili giây tại các luồng thu thập cuối cùng. (Sắp xếp và tổng hợp hoạt động trên một số lượng nhỏ hàng nên các phép tính thời gian đã trôi qua của chúng xuất hiện giống như sắp xếp, nhưng nói chung chúng thường khác nhau):

Tất cả các toán tử trong phân đoạn kế hoạch ở trên có 0ms thời gian CPU đã trôi qua trên tất cả các luồng (ngoại trừ tổng hợp một phần, có 14.891 mili giây). Do đó, kế hoạch với các con số được tính toán của chúng tôi có ý nghĩa hơn nhiều so với kế hoạch được hiển thị:
- 4,675ms - 4,662ms = 13ms đã trôi qua là một con số hợp lý hơn nhiều cho thời gian tiêu tốn của các luồng phân vùng lại một mình . Toán tử này không tốn thời gian CPU và chỉ xử lý 524 hàng.
- 0ms thời gian trôi qua (đến độ phân giải mili giây) là hợp lý cho việc sắp xếp và tổng hợp luồng nhỏ (một lần nữa, không bao gồm phần con của chúng).
- 4,676ms - 4,675ms = 1ms có vẻ tốt cho các luồng thu thập cuối cùng để thu thập 66 hàng vào chuỗi nhiệm vụ chính để trả lại cho khách hàng.
Ngoài sự mâu thuẫn rõ ràng trong kế hoạch đã cho giữa luồng tổng hợp một phần (4,662ms) và luồng phân chia lại (2,844ms), thật không hợp lý khi nghĩ rằng luồng tập hợp cuối cùng của 66 hàng có thể chịu trách nhiệm cho 4,676ms - 2,844ms = 1,832 mili giây thời gian đã trôi qua. Số đã hiệu chỉnh (1ms) chính xác hơn nhiều và sẽ không gây hiểu lầm cho bộ điều chỉnh truy vấn.
Bây giờ, ngay cả khi tính toán bù đắp này được thực hiện chính xác, các kế hoạch chế độ hàng song song có thể không hiển thị thời gian tích lũy nhất quán trong mọi trường hợp, vì những lý do đã được thảo luận trước đó. Việc đạt được sự nhất quán hoàn toàn có thể khó hoặc thậm chí là không thể nếu không có những thay đổi lớn về kiến trúc.
Để đoán trước một câu hỏi có thể phát sinh tại thời điểm này:Không, phân tích tìm kiếm chỉ mục và trao đổi trước đó không liên quan đến lỗi tính toán bù đắp “Luồng 0”. Không có toán tử chặn bên dưới sàn giao dịch đó, do đó, không có sự chậm trễ khởi tạo nào phát sinh.
Ví dụ cuối cùng
Truy vấn ví dụ tiếp theo này sử dụng cùng một cơ sở dữ liệu và chỉ mục như trước. Tôi sẽ không khám phá nó quá nhiều chi tiết vì nó chỉ phục vụ để mở rộng những điểm tôi đã đưa ra, cho người đọc quan tâm.
Các tính năng của bản trình diễn này là:
- Không có
ORDER GROUPgợi ý, nó cho thấy cách tổng hợp một phần không được coi là toán tử chặn, do đó, không có điều chỉnh “Luồng 0” nào phát sinh khi trao đổi luồng phân vùng lại. Thời gian đã trôi qua là nhất quán. - Với gợi ý, các loại chặn được giới thiệu thay vì tổng hợp một phần băm. Hai khác nhau Các điều chỉnh "Chủ đề 0" xuất hiện ở hai sàn giao dịch phân vùng lại. Thời gian đã trôi qua không nhất quán trên cả hai nhánh, theo những cách khác nhau.
Truy vấn:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
Kế hoạch thực thi không có ORDER GROUP (không điều chỉnh, thời gian nhất quán):

Kế hoạch thực thi với ORDER GROUP (hai lần điều chỉnh khác nhau, thời gian không nhất quán):

Tóm tắt và kết luận
Báo cáo toán tử kế hoạch chế độ hàng tích lũy times inclusive of all child operators in the same thread. Batch mode operators record the time used inside that operator alone .
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER ). This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.