Presto là một công cụ SQL mã nguồn mở, phân tán song song để xử lý dữ liệu lớn. Nó được phát triển từ đầu bởi Facebook. Bản phát hành nội bộ đầu tiên diễn ra vào năm 2013 và là một giải pháp mang tính cách mạng cho các vấn đề dữ liệu lớn của họ.
Với hàng trăm máy chủ định vị địa lý và hàng petabyte dữ liệu, Facebook bắt đầu tìm kiếm một nền tảng thay thế cho các cụm Hadoop của họ. Nhóm cơ sở hạ tầng của họ muốn giảm thời gian cần thiết để chạy các công việc hàng loạt phân tích và đơn giản hóa việc phát triển đường ống bằng cách sử dụng ngôn ngữ lập trình được biết đến rộng rãi trong tổ chức - SQL.
Theo Presto Foundation, “Facebook sử dụng Presto cho các truy vấn tương tác với một số kho dữ liệu nội bộ, bao gồm cả kho dữ liệu 300PB của họ. Hơn 1.000 nhân viên của Facebook sử dụng Presto hàng ngày để chạy hơn 30.000 truy vấn quét tổng cộng trên một petabyte mỗi ngày. ”
Mặc dù Facebook có một môi trường kho dữ liệu đặc biệt, nhưng những thách thức tương tự đang hiện hữu ở nhiều tổ chức xử lý dữ liệu lớn.
Trong blog này, chúng ta sẽ xem xét cách thiết lập môi trường presto cơ bản bằng cách sử dụng máy chủ Docker từ tệp tar. Với tư cách là nguồn dữ liệu, chúng tôi sẽ tập trung vào nguồn dữ liệu MySQL, nhưng nó có thể là bất kỳ RDBMS phổ biến nào khác.
Chạy Presto trong Môi trường Dữ liệu Lớn
Trước khi bắt đầu, chúng ta hãy xem nhanh các nguyên tắc kiến trúc chính của nó. Presto là một giải pháp thay thế cho các công cụ truy vấn HDFS bằng cách sử dụng các đường ống của công việc MapReduce - chẳng hạn như Hive. Không giống như Hive Presto không sử dụng MapReduce. Presto chạy với một công cụ thực thi truy vấn có mục đích đặc biệt với các toán tử cấp cao và xử lý trong bộ nhớ.
Ngược lại với Hive Presto có thể truyền dữ liệu qua tất cả các giai đoạn cùng một lúc, chạy đồng thời các khối dữ liệu. Nó được thiết kế để chạy các truy vấn phân tích đặc biệt dựa trên các nguồn dữ liệu không đồng nhất đơn lẻ hoặc phân tán. Nó có thể tiếp cận từ nền tảng Hadoop để truy vấn cơ sở dữ liệu quan hệ hoặc các kho dữ liệu khác như tệp phẳng.
Presto sử dụng ANSI SQL tiêu chuẩn bao gồm các chức năng tổng hợp, nối hoặc cửa sổ phân tích. SQL nổi tiếng và dễ sử dụng hơn nhiều so với MapReduce được viết bằng Java.
Triển khai Presto cho Docker
Cấu hình Presto cơ bản có thể được triển khai với hình ảnh Docker được định cấu hình trước hoặc tarball máy chủ presto.
Máy chủ docker và vùng chứa Presto CLI có thể được triển khai dễ dàng với:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliBạn có thể chọn giữa hai phiên bản máy chủ Presto. Phiên bản cộng đồng và phiên bản Doanh nghiệp từ Starburst. Vì chúng tôi sẽ chạy nó trong môi trường hộp cát phi sản xuất, chúng tôi sẽ sử dụng phiên bản Apache trong bài viết này.
Yêu cầu trước
Presto được triển khai hoàn toàn bằng Java và yêu cầu JVM phải được cài đặt trên hệ thống của bạn. Nó chạy trên cả OpenJDK và Oracle Java. Phiên bản tối thiểu là Java 8u151 hoặc Java 11.
Để tải xuống JAVA JDK, hãy truy cập https://openjdk.java.net/ hoặc https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Bạn có thể kiểm tra phiên bản Java của mình bằng
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Cài đặt trước
Để cài đặt Presto, chúng tôi sẽ tải xuống máy chủ tar và thực thi jar Presto CLI.
Tarball sẽ chứa một thư mục cấp cao nhất, presto-server-0.223, mà chúng tôi sẽ gọi là thư mục cài đặt.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoNgoài ra, Presto cần một thư mục dữ liệu để lưu trữ nhật ký, v.v.
Bạn nên tạo một thư mục dữ liệu bên ngoài thư mục cài đặt.
$ mkdir -p ~/data/presto/Vị trí này là nơi khi chúng tôi bắt đầu khắc phục sự cố.
Định cấu hình Presto
Trước khi bắt đầu phiên bản đầu tiên, chúng ta cần tạo một loạt các tệp cấu hình. Bắt đầu với việc tạo thư mục etc / bên trong thư mục cài đặt. Vị trí này sẽ chứa các tệp cấu hình sau:
vv /
- Thuộc tính nút - cấu hình môi trường nút
- Cấu hình JVM (jvm.config) - Cấu hình Máy ảo Java
- Thuộc tính cấu hình (config.properties) -cấu hình cho máy chủ Presto
- Thuộc tính danh mục - cấu hình cho Trình kết nối (nguồn dữ liệu)
- Thuộc tính nhật ký - Cấu hình bộ ghi nhật ký
Dưới đây, bạn có thể tìm thấy một số cấu hình cơ bản để chạy hộp cát Presto. Để biết thêm chi tiết, hãy truy cập tài liệu.
vi etc / config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc / node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoCấu trúc etc / cơ bản có thể trông như sau:

Bước tiếp theo là thiết lập trình kết nối MySQL.
Chúng tôi sẽ kết nối với một trong 3 nút MariaDB Cluster.
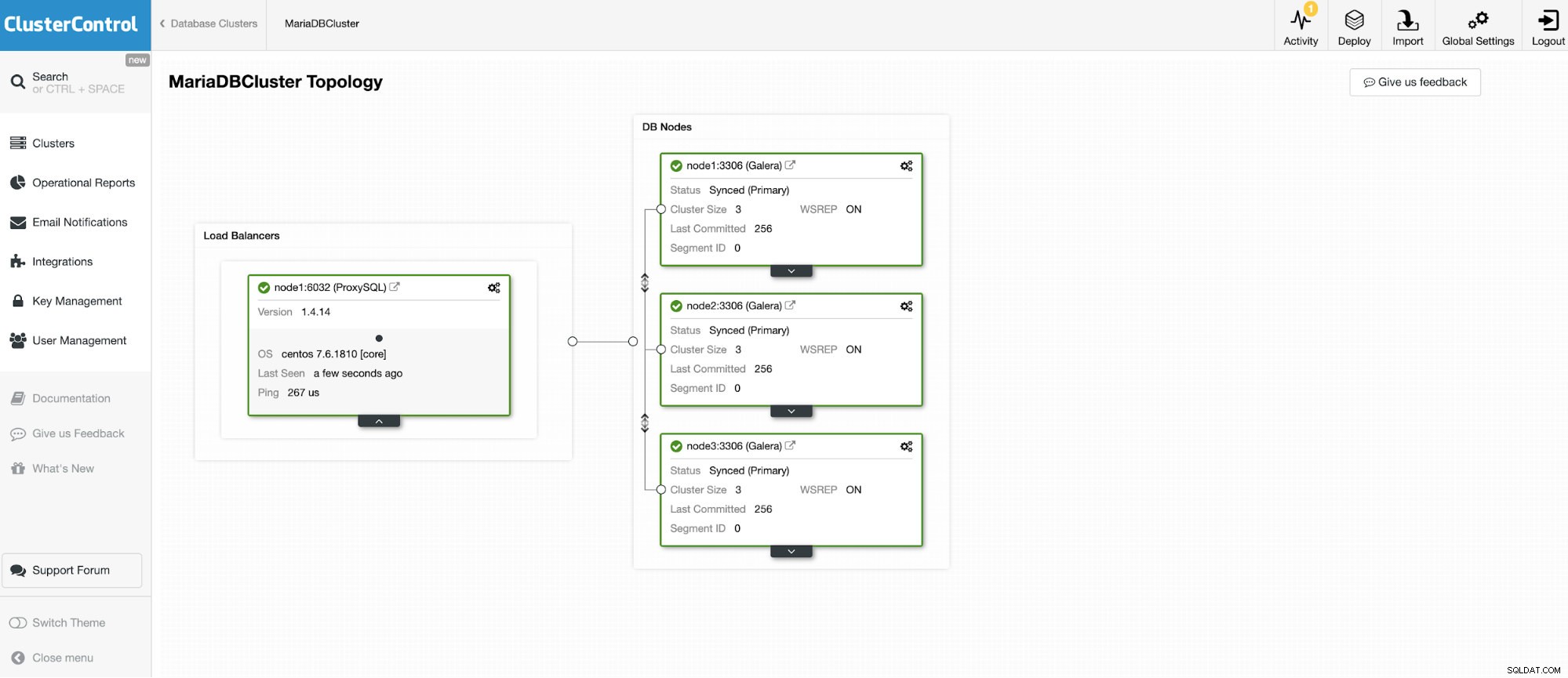
Và một phiên bản độc lập khác chạy Oracle MySQL 5.7.
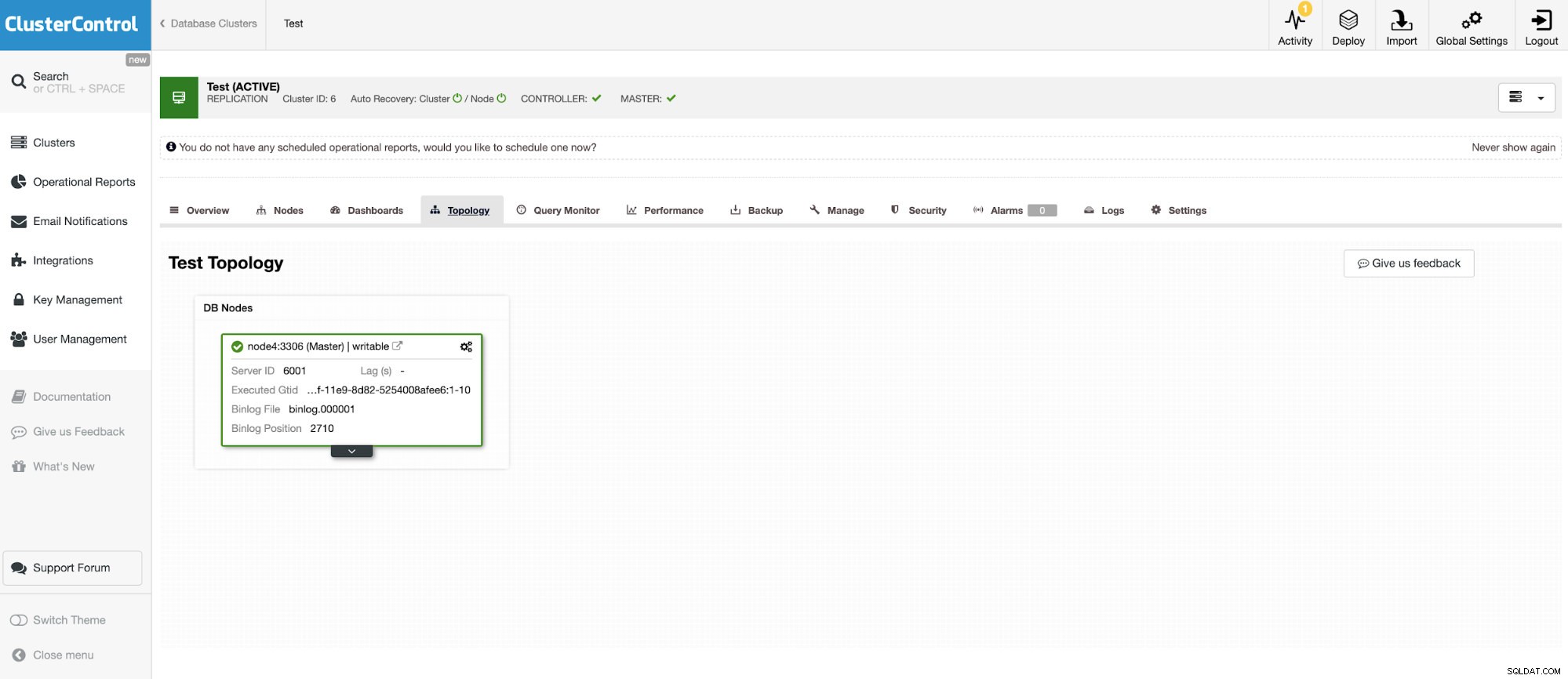
Trình kết nối MySQL cho phép truy vấn và tạo bảng trong cơ sở dữ liệu MySQL bên ngoài. Điều này có thể được sử dụng để kết hợp dữ liệu giữa các hệ thống khác nhau như MariaDB và MySQL từ Oracle.
Presto sử dụng các đầu nối có thể cắm được và cấu hình rất dễ dàng. Để định cấu hình trình kết nối MySQL, hãy tạo tệp thuộc tính danh mục trong etc / catalô có tên, ví dụ:mysql.properties, để gắn kết nối MySQL dưới dạng danh mục mysql. Mỗi tệp đại diện cho một kết nối đến máy chủ khác. Trong trường hợp này, chúng tôi có hai tệp:
vi etc / catalog / mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc / catalog / mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretChạy Presto
Khi tất cả đã được thiết lập, đã đến lúc bắt đầu phiên bản Presto. Để bắt đầu trước, hãy chuyển đến thư mục bin trong cài đặt preso và chạy như sau:
$ bin/launcher start
Started as 18363Để dừng Presto run
$ bin/launcher stopBây giờ khi máy chủ khởi động và chạy, chúng tôi có thể kết nối với Presto bằng CLI và truy vấn cơ sở dữ liệu MySQL.
Để bắt đầu chạy bảng điều khiển Presto:
./presto --server localhost:8080 --catalog mysql --schema employeesGiờ đây, chúng tôi có thể truy vấn cơ sở dữ liệu của mình qua CLI.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
Cả hai cơ sở dữ liệu MariaDB cluster và MySQL đã được cấp dữ liệu với cơ sở dữ liệu nhân viên.
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlTrạng thái của truy vấn cũng hiển thị trong bảng điều khiển web Presto: https:// localhost:8080 / ui / #
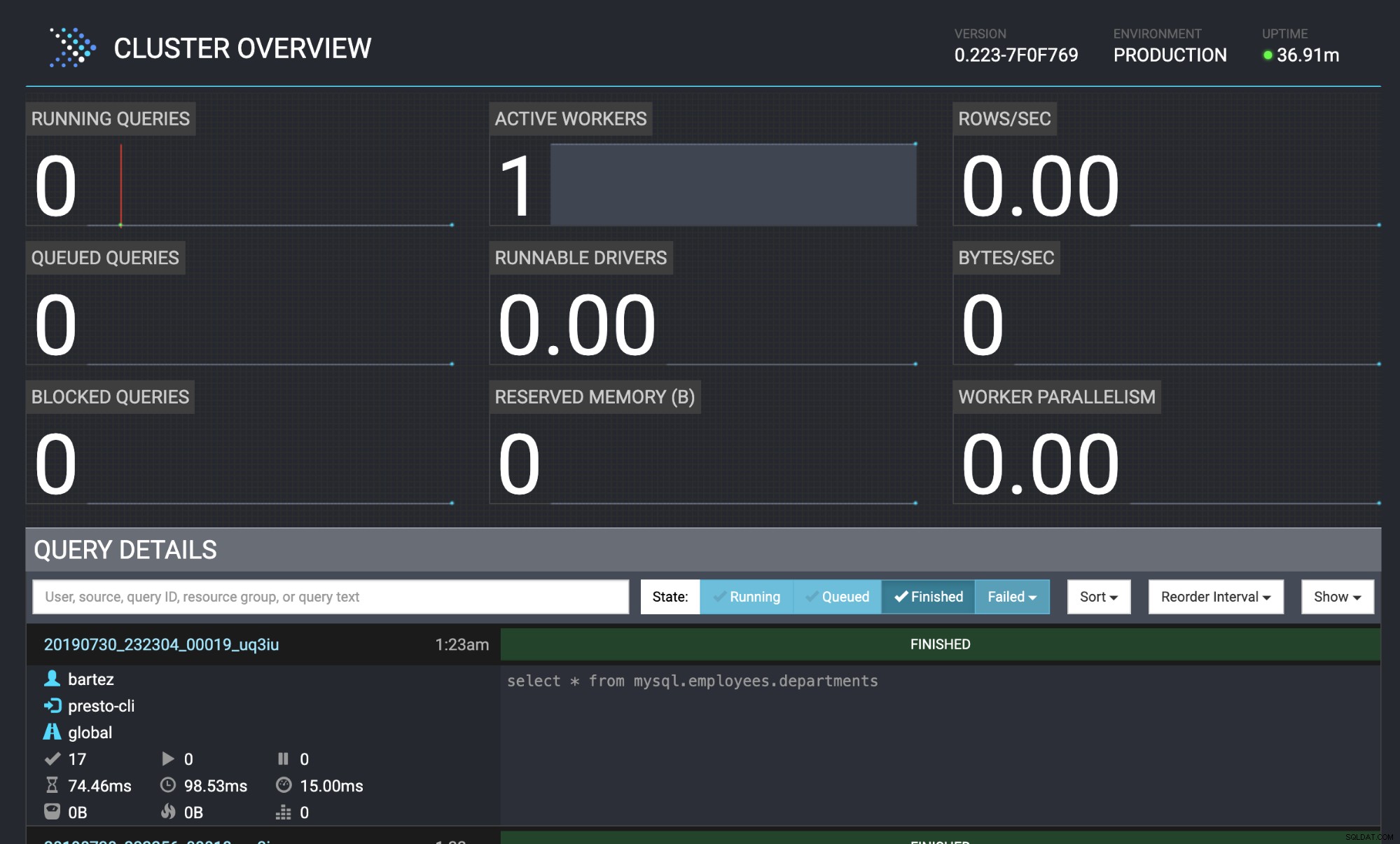 Tổng quan về cụm trước
Tổng quan về cụm trước Kết luận
Nhiều công ty nổi tiếng (như Airbnb, Netflix, Twitter) đang áp dụng Presto để có hiệu suất độ trễ thấp. Không nghi ngờ gì nữa, đó là phần mềm rất thú vị có thể loại bỏ nhu cầu chạy các quy trình kho dữ liệu ETL nặng nề. Trong blog này, chúng tôi chỉ giới thiệu sơ lược về trình kết nối MySQL nhưng bạn có thể sử dụng nó để phân tích dữ liệu từ HDFS, cửa hàng đối tượng, RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB và nhiều người khác.