Trong trường hợp bạn chưa xem, chúng tôi vừa phát hành ClusterControl 1.7.5 với những cải tiến lớn và các tính năng hữu ích mới. Một số tính năng bao gồm Bảo trì toàn cụm, hỗ trợ phiên bản CentOS 8 và Debian 10, Hỗ trợ PostgreSQL 12, hỗ trợ MongoDB 4.2 và Percona MongoDB v4.0, cũng như MySQL Freeze Frame mới.
Chờ đã, nhưng MySQL Freeze Frame là gì? Đây có phải là cái gì đó mới đối với MySQL?
Chà, bản thân nó không phải là một cái gì đó mới trong MySQL Kernel. Đó là một tính năng mới mà chúng tôi đã thêm vào ClusterControl 1.7.5 dành riêng cho cơ sở dữ liệu MySQL. MySQL Freeze Frame trong ClusterControl 1.7.5 sẽ bao gồm những điều sau:
- Chụp nhanh trạng thái MySQL trước khi lỗi cụm.
- Ảnh chụp nhanh danh sách quy trình MySQL trước khi lỗi cụm (sắp ra mắt).
- Kiểm tra các sự cố cụm trong báo cáo hoạt động hoặc từ công cụ dòng lệnh s9s.
Đây là những tập hợp thông tin có giá trị có thể giúp theo dõi lỗi và sửa các cụm MySQL / MariaDB của bạn khi mọi thứ đi xuống phía nam. Trong tương lai, chúng tôi cũng có kế hoạch đưa vào ảnh chụp nhanh của các giá trị trạng thái SHOW ENGINE InnoDB. Vì vậy, hãy theo dõi các bản phát hành trong tương lai của chúng tôi.
Lưu ý rằng tính năng này vẫn ở trạng thái thử nghiệm, chúng tôi hy vọng sẽ thu thập thêm bộ dữ liệu khi chúng tôi làm việc với người dùng của mình. Trong blog này, chúng tôi sẽ chỉ cho bạn cách tận dụng tính năng này, đặc biệt khi bạn cần thêm thông tin khi chẩn đoán cụm MySQL / MariaDB của mình.
ClusterControl khi Xử lý Lỗi cụm
Đối với lỗi cụm, ClusterControl không làm gì trừ khi Tự động khôi phục (Cụm / Nút) được bật giống như bên dưới:

Sau khi được bật, ClusterControl sẽ cố gắng khôi phục một nút hoặc khôi phục cụm bằng cách đưa lên cấu trúc liên kết toàn bộ cụm.
Đối với MySQL, chẳng hạn như trong bản sao master-slave, nó phải có ít nhất một master còn sống tại bất kỳ thời điểm nào, bất kể số lượng / s slave có sẵn. ClusterControl cố gắng sửa cấu trúc liên kết ít nhất một lần cho các cụm sao chép, nhưng cung cấp nhiều lần thử lại hơn cho sao chép nhiều tổng thể như NDB Cluster và Galera Cluster. Khôi phục nút cố gắng khôi phục một nút cơ sở dữ liệu bị lỗi, ví dụ:khi quá trình bị dừng (tắt bất thường) hoặc quá trình bị OOM (Hết bộ nhớ). ClusterControl sẽ kết nối với nút thông qua SSH và cố gắng kích hoạt MySQL. Trước đây chúng tôi đã viết blog về Cách ClusterControl thực hiện khôi phục cơ sở dữ liệu tự động và chuyển đổi dự phòng, vì vậy vui lòng truy cập bài viết đó để tìm hiểu thêm về sơ đồ phục hồi tự động ClusterControl.
Trong phiên bản trước của ClusterControl <1.7.5, những nỗ lực khôi phục đó đã kích hoạt cảnh báo. Nhưng một điều mà khách hàng của chúng tôi đã bỏ lỡ là một báo cáo sự cố đầy đủ hơn với thông tin trạng thái ngay trước khi sự cố cụm. Cho đến khi chúng tôi nhận ra sự thiếu hụt này và thêm tính năng này trong ClusterControl 1.7.5. Chúng tôi gọi nó là "MySQL Freeze Frame". MySQL Freeze Frame, kể từ khi viết bài này, cung cấp một bản tóm tắt ngắn gọn về các sự cố dẫn đến thay đổi trạng thái cụm ngay trước khi sự cố. Quan trọng nhất, nó bao gồm ở cuối báo cáo danh sách các máy chủ lưu trữ và các biến và giá trị Trạng thái Toàn cầu MySQL của chúng.
MySQL Freeze Frame Khác biệt như thế nào với Tự động Khôi phục?
MySQL Freeze Frame không phải là một phần của quá trình tự động khôi phục ClusterControl. Cho dù Tự động khôi phục bị tắt hay được bật, MySQL Freeze Frame sẽ luôn hoạt động miễn là phát hiện lỗi cụm hoặc nút.
MySQL Freeze Frame hoạt động như thế nào?
Trong ClusterControl, có một số trạng thái nhất định mà chúng tôi phân loại thành các loại Trạng thái cụm khác nhau. MySQL Freeze Frame sẽ tạo một báo cáo sự cố khi hai trạng thái này được kích hoạt:
- CLUSTER_DEGRADED
- CLUSTER_FAILURE
Trong ClusterControl, CLUSTER_DEGRADED là khi bạn có thể ghi vào một cụm, nhưng một hoặc nhiều nút không hoạt động. Khi điều này xảy ra, ClusterControl sẽ tạo báo cáo sự cố.
Đối với CLUSTER_FAILURE, mặc dù danh pháp của nó tự giải thích nhưng đó là trạng thái mà cụm của bạn bị lỗi và không thể xử lý đọc hoặc ghi nữa. Sau đó, đó là trạng thái CLUSTER_FAILURE. Bất kể quá trình tự động khôi phục đang cố gắng khắc phục sự cố hay quá trình bị vô hiệu hóa, ClusterControl sẽ tạo báo cáo sự cố.
Làm cách nào để bạn kích hoạt MySQL Freeze Frame?
MySQL Freeze Frame của ClusterControl được bật theo mặc định và chỉ tạo báo cáo sự cố khi trạng thái CLUSTER_DEGRADED hoặc CLUSTER_FAILURE được kích hoạt hoặc gặp phải. Vì vậy, phía người dùng không cần đặt bất kỳ cài đặt cấu hình ClusterControl nào, ClusterControl sẽ tự động làm điều đó cho bạn.
Định vị Báo cáo Sự cố Khung đóng băng MySQL
Khi viết bài này, có 4 cách bạn có thể xác định báo cáo sự cố. Bạn có thể tìm thấy những điều này bằng cách thực hiện các phần tiếp theo bên dưới.
Sử dụng Tab Báo cáo Hoạt động
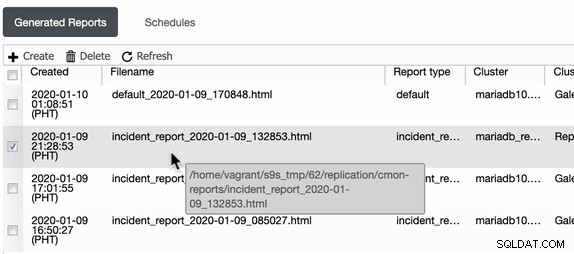
Báo cáo hoạt động từ các phiên bản trước chỉ được sử dụng để tạo, lập lịch hoặc liệt kê các báo cáo hoạt động đã được tạo bởi người dùng. Kể từ phiên bản 1.7.5, chúng tôi đã bao gồm báo cáo sự cố được tạo bởi tính năng MySQL Freeze Frame của chúng tôi. Xem ví dụ bên dưới:
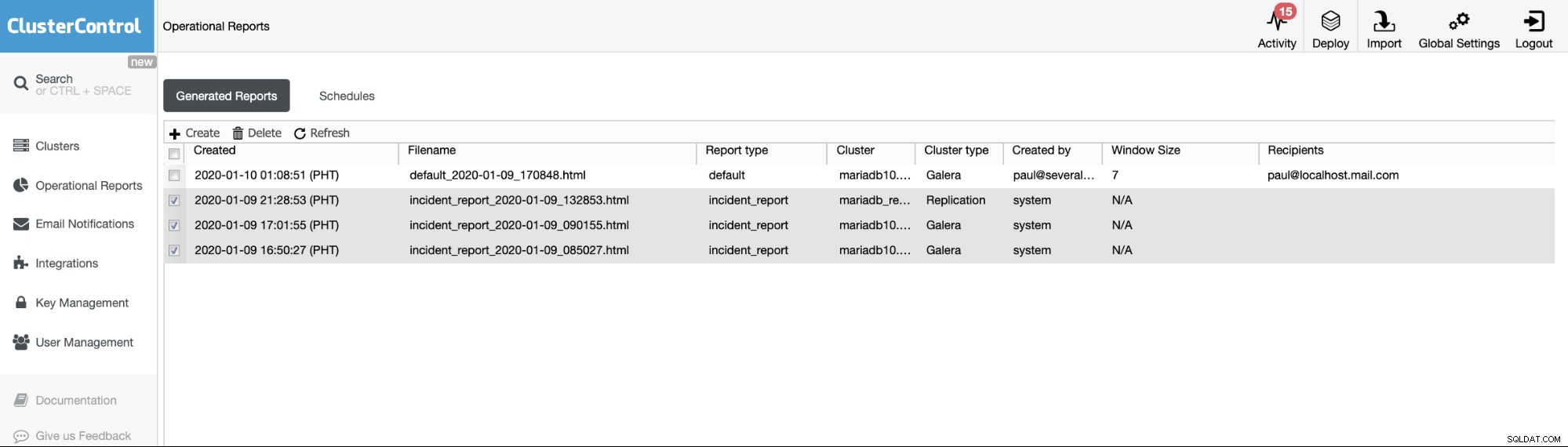
Các mục đã kiểm tra hoặc các mục có loại Báo cáo ==event_report, là sự cố các báo cáo được tạo bởi tính năng MySQL Freeze Frame trong ClusterControl.
Sử dụng Báo cáo Lỗi
Bằng cách chọn cụm và tạo báo cáo lỗi, tức là thực hiện quá trình này:
Sử dụng Dòng lệnh CLI s9s
Trên báo cáo sự cố đã tạo, nó bao gồm hướng dẫn hoặc gợi ý về cách bạn có thể sử dụng điều này với lệnh CLI s9s. Dưới đây là những gì được thể hiện trong báo cáo sự cố:
Gợi ý! Sử dụng công cụ CLI s9s cho phép bạn dễ dàng thu thập dữ liệu trong báo cáo này, ví dụ:
s9s report --list --long
s9s report --cat --report-id=NVì vậy, nếu bạn muốn xác định vị trí và tạo báo cáo lỗi, bạn có thể sử dụng phương pháp này:
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident ReportNếu tôi muốn grep các biến wsrep_ * trên một máy chủ cụ thể, tôi có thể làm như sau:
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |Định vị theo cách thủ công qua Đường dẫn Tệp Hệ thống
ClusterControl tạo các báo cáo sự cố này trong máy chủ lưu trữ ClusterControl chạy. ClusterControl tạo một thư mục trong / home /
Có Bất kỳ Nguy hiểm hoặc Cảnh báo nào khi Sử dụng MySQL Freeze Frame không?
ClusterControl không thay đổi hoặc sửa đổi bất kỳ điều gì trong các nút hoặc cụm MySQL của bạn. MySQL Freeze Frame sẽ chỉ đọc HIỂN THỊ TRẠNG THÁI TOÀN CẦU (tính đến thời điểm này) trong các khoảng thời gian cụ thể để lưu bản ghi vì chúng tôi không thể dự đoán trạng thái của một nút hoặc cụm MySQL khi nó có thể gặp sự cố hoặc khi nó có thể có vấn đề về phần cứng hoặc đĩa. Không thể dự đoán điều này, vì vậy chúng tôi lưu các giá trị và do đó chúng tôi có thể tạo báo cáo sự cố trong trường hợp một nút cụ thể gặp sự cố. Trong trường hợp đó, nguy cơ mắc phải điều này là gần như không xảy ra. Về mặt lý thuyết, nó có thể thêm một loạt các yêu cầu của khách hàng vào (các) máy chủ trong trường hợp một số khóa được giữ trong MySQL, nhưng chúng tôi chưa nhận thấy điều đó. chúng tôi biết hoặc gửi yêu cầu hỗ trợ trong trường hợp có vấn đề phát sinh.
Có một số tình huống trong đó báo cáo sự cố có thể không thu thập được các biến trạng thái toàn cục nếu sự cố mạng là sự cố trước khi ClusterControl đóng băng một khung cụ thể để thu thập dữ liệu. Điều đó hoàn toàn hợp lý vì không có cách nào ClusterControl có thể thu thập dữ liệu để chẩn đoán thêm vì không có kết nối với nút ngay từ đầu.
Cuối cùng, bạn có thể thắc mắc tại sao không phải tất cả các biến đều được hiển thị trong phần TRẠNG THÁI TOÀN CẦU? Trong thời gian chờ đợi, chúng tôi đặt một bộ lọc trong đó các giá trị trống hoặc 0 bị loại trừ trong báo cáo sự cố. Lý do là chúng tôi muốn tiết kiệm một số không gian đĩa. Khi các báo cáo sự cố này không còn cần thiết nữa, bạn có thể xóa nó qua Tab Báo cáo Hoạt động.
Kiểm tra tính năng MySQL Freeze Frame
Chúng tôi tin rằng bạn rất muốn thử cái này và xem nó hoạt động như thế nào. Nhưng hãy đảm bảo rằng bạn không chạy hoặc thử nghiệm điều này trong môi trường sản xuất hoặc trực tiếp. Chúng tôi sẽ đề cập đến 2 giai đoạn của kịch bản trong MySQL / MariaDB, một cho thiết lập master-slave và một cho thiết lập kiểu Galera.
Kịch bản kiểm tra thiết lập Master-Slave
Trong thiết lập (các) chủ-tớ, thật dễ dàng và đơn giản để thử.
Bước Một
Đảm bảo rằng bạn đã tắt chế độ Tự động khôi phục (Cụm và Nút), như bên dưới:

nên nó sẽ không thử hoặc cố gắng khắc phục tình huống thử nghiệm.
Bước Hai
Đi tới nút Chính của bạn và thử đặt thành chỉ đọc:
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)Bước Ba
Lần này, một báo động đã được nâng lên và do đó, một báo cáo sự cố đã được tạo ra. Xem bên dưới cụm của tôi trông như thế nào:

và báo thức đã được kích hoạt:

và báo cáo sự cố đã được tạo:

Kịch bản kiểm tra thiết lập cụm Galera
Đối với thiết lập dựa trên Galera, chúng tôi cần đảm bảo rằng cụm sẽ không còn khả dụng, tức là lỗi trên toàn cụm. Không giống như thử nghiệm Master-Slave, bạn có thể bật Tự động khôi phục vì chúng tôi sẽ thử nghiệm với các giao diện mạng.
Lưu ý:Đối với thiết lập này, hãy đảm bảo rằng bạn có nhiều giao diện nếu bạn đang kiểm tra các nút trong một phiên bản từ xa vì bạn không thể đưa giao diện lên khi bạn hạ giao diện đó nơi bạn được kết nối.
Bước Một
Tạo cụm Galera 3 nút (ví dụ:sử dụng vagrant)
Bước Hai
Ban hành lệnh (giống như bên dưới) để mô phỏng sự cố mạng và thực hiện việc này với tất cả các nút
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.Bước Ba
Bây giờ, nó đã gỡ bỏ cụm của tôi và có trạng thái sau:

báo động,

và nó tạo báo cáo sự cố:

Đối với một báo cáo sự cố mẫu, bạn có thể sử dụng tệp thô này và lưu nó dưới dạng html.
Việc thử lại khá đơn giản, nhưng vui lòng chỉ thực hiện việc này trong môi trường không trực tiếp và không phải sản phẩm.
Kết luận
MySQL Freeze Frame trong ClusterControl có thể hữu ích khi chẩn đoán sự cố. Khi khắc phục sự cố, bạn cần nhiều thông tin để xác định nguyên nhân và đó chính xác là những gì MySQL Freeze Frame cung cấp.