Tóm tắt ngắn
- Hiệu suất của phương pháp truy vấn con phụ thuộc vào phân phối dữ liệu.
- Hiệu suất của tổng hợp có điều kiện không phụ thuộc vào phân phối dữ liệu.
Phương thức truy vấn con có thể nhanh hơn hoặc chậm hơn phương thức tổng hợp có điều kiện, nó phụ thuộc vào việc phân phối dữ liệu.
Đương nhiên, nếu bảng có một chỉ mục phù hợp, thì các truy vấn con có thể được hưởng lợi từ nó, vì chỉ mục sẽ cho phép chỉ quét phần có liên quan của bảng thay vì quét toàn bộ. Việc có một chỉ mục phù hợp không chắc sẽ mang lại lợi ích đáng kể cho Phương pháp tổng hợp có điều kiện, vì dù sao nó cũng sẽ quét toàn bộ chỉ mục. Lợi ích duy nhất sẽ là nếu chỉ mục hẹp hơn bảng và công cụ sẽ phải đọc ít trang hơn vào bộ nhớ.
Biết được điều này, bạn có thể quyết định chọn phương pháp nào.
Thử nghiệm đầu tiên
Tôi đã tạo một bảng thử nghiệm lớn hơn, với 5 triệu hàng. Không có chỉ mục nào trên bảng. Tôi đã đo số liệu thống kê IO và CPU bằng SQL Sentry Plan Explorer. Tôi đã sử dụng SQL Server 2014 SP1-CU7 (12.0.4459.0) Express 64-bit cho các bài kiểm tra này.
Thật vậy, các truy vấn ban đầu của bạn hoạt động như bạn mô tả, tức là các truy vấn phụ nhanh hơn mặc dù số lần đọc cao hơn 3 lần.
Sau một vài lần thử trên bảng không có chỉ mục, tôi đã viết lại tổng hợp có điều kiện của bạn và thêm các biến để giữ giá trị của DATEADD biểu thức.
Nhìn chung, thời gian trở nên nhanh hơn đáng kể.
Sau đó, tôi thay thế SUM với COUNT và nó lại nhanh hơn một chút.
Rốt cuộc, tổng hợp có điều kiện trở nên khá nhanh như truy vấn con.
Làm ấm bộ nhớ cache (CPU =375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Truy vấn phụ (CPU =1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
Tổng hợp có điều kiện ban đầu (CPU =1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Tổng hợp có điều kiện với các biến (CPU =1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Tổng hợp có điều kiện với các biến và COUNT thay vì SUM (CPU =1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Dựa trên những kết quả này, tôi đoán rằng CASE được gọi ra DATEADD cho mỗi hàng, trong khi WHERE đủ thông minh để tính toán nó một lần. Cộng với COUNT hiệu quả hơn một chút so với SUM .
Cuối cùng, tổng hợp có điều kiện chỉ chậm hơn một chút so với các truy vấn con (1062 so với 1031), có thể do WHERE hiệu quả hơn một chút so với CASE trong chính nó, và bên cạnh đó, WHERE lọc ra khá nhiều hàng, vì vậy COUNT phải xử lý ít hàng hơn.
Trong thực tế, tôi sẽ sử dụng kết hợp có điều kiện, vì tôi nghĩ rằng số lần đọc quan trọng hơn. Nếu bảng của bạn nhỏ để phù hợp và nằm trong vùng đệm, thì mọi truy vấn sẽ nhanh chóng đến tay người dùng cuối. Tuy nhiên, nếu bảng lớn hơn bộ nhớ khả dụng, thì tôi cho rằng việc đọc từ đĩa sẽ làm chậm các truy vấn con đáng kể.
Thử nghiệm thứ hai
Mặt khác, việc lọc các hàng càng sớm càng tốt cũng rất quan trọng.
Đây là một biến thể nhỏ của bài kiểm tra, minh chứng cho điều đó. Ở đây, tôi đặt ngưỡng là GETDATE () + 100 năm, để đảm bảo rằng không có hàng nào đáp ứng tiêu chí bộ lọc.
Làm ấm bộ nhớ cache (CPU =344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Truy vấn phụ (CPU =500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
Tổng hợp có điều kiện ban đầu (CPU =937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Tổng hợp có điều kiện với các biến (CPU =750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Tổng hợp có điều kiện với các biến và COUNT thay vì SUM (CPU =750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
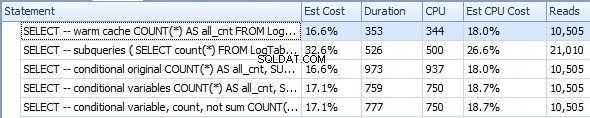
Dưới đây là một kế hoạch với các truy vấn phụ. Bạn có thể thấy rằng 0 hàng đã đi vào Tổng hợp luồng trong truy vấn con thứ hai, tất cả chúng đã được lọc ra ở bước Quét bảng.
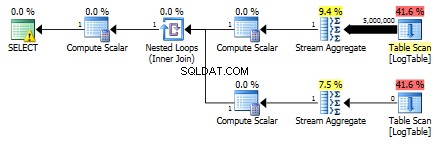
Kết quả là, các truy vấn con lại nhanh hơn.
Thử nghiệm thứ ba
Ở đây tôi đã thay đổi tiêu chí lọc của thử nghiệm trước:tất cả > đã được thay thế bằng < . Do đó, COUNT có điều kiện đã đếm tất cả các hàng thay vì không có hàng nào. Bất ngờ, bất ngờ! Truy vấn tổng hợp có điều kiện mất cùng 750 mili giây, trong khi truy vấn con trở thành 813 thay vì 500.

Đây là kế hoạch cho các truy vấn phụ:
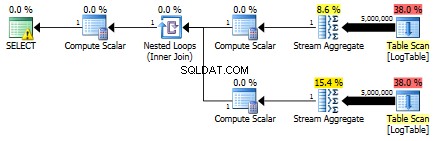
Bạn có thể cho tôi một ví dụ, trong đó tập hợp có điều kiện hoạt động tốt hơn giải pháp truy vấn con không?
Nó đây. Hiệu suất của phương pháp truy vấn con phụ thuộc vào phân phối dữ liệu. Hiệu suất của tổng hợp có điều kiện không phụ thuộc vào phân phối dữ liệu.
Phương pháp truy vấn con có thể nhanh hơn hoặc chậm hơn so với tổng hợp có điều kiện, nó phụ thuộc vào việc phân phối dữ liệu.
Biết được điều này, bạn có thể quyết định chọn phương pháp nào.
Chi tiết phần thưởng
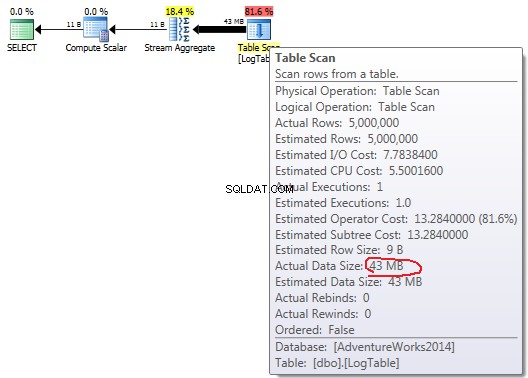
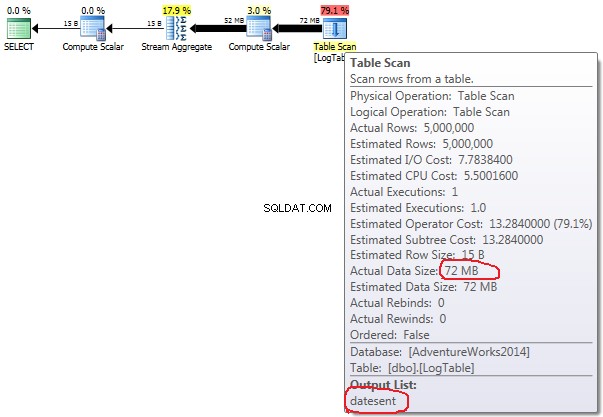
Nếu bạn di chuột qua Table Scan bạn có thể thấy Actual Data Size trong các biến thể khác nhau.
-
COUNT(*)đơn giản :
- Tổng hợp có điều kiện:
- Truy vấn con trong thử nghiệm 2:
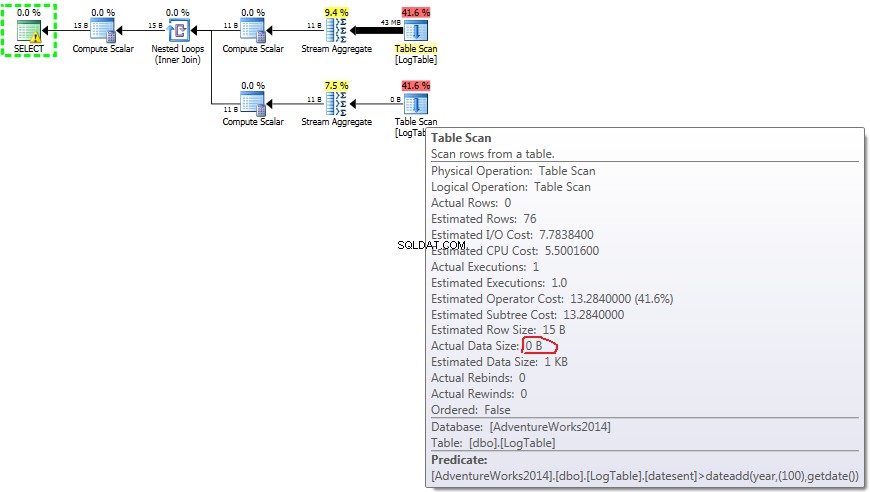
- Truy vấn con trong thử nghiệm 3:
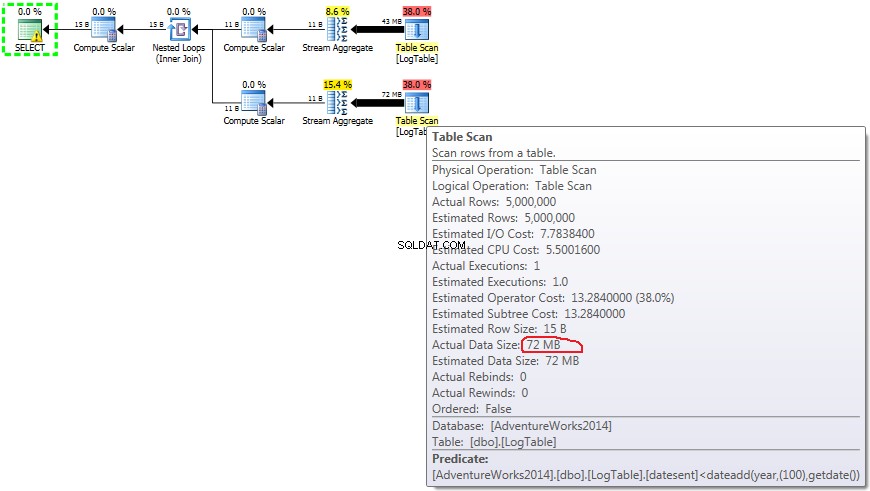
Giờ đây, rõ ràng là sự khác biệt về hiệu suất có thể do sự khác biệt về lượng dữ liệu truyền qua kế hoạch.
Trong trường hợp COUNT(*) đơn giản không có Output list (không cần giá trị cột) và kích thước dữ liệu nhỏ nhất (43MB).
Trong trường hợp tổng hợp có điều kiện, số tiền này không thay đổi giữa các thử nghiệm 2 và 3, nó luôn là 72MB. Output list có một cột datesent .
Trong trường hợp truy vấn phụ, số tiền này không thay đổi tùy thuộc vào phân phối dữ liệu.