Trong bài đăng cuối cùng của tôi, tôi đã bắt đầu một loạt bài bao gồm kiểm tra sức khỏe chủ động quan trọng đối với SQL Server của bạn. Chúng tôi đã bắt đầu với dung lượng đĩa và trong bài đăng này, chúng tôi sẽ thảo luận về các nhiệm vụ bảo trì. Một trong những trách nhiệm cơ bản của DBA là đảm bảo rằng các nhiệm vụ bảo trì sau đây chạy thường xuyên:
- Bản sao lưu
- Kiểm tra tính toàn vẹn
- Duy trì chỉ mục
- Cập nhật số liệu thống kê
Cá cược của tôi là bạn đã có sẵn công việc để quản lý những công việc này. Và tôi cũng dám cá rằng bạn đã cấu hình thông báo để gửi email cho bạn và nhóm của bạn nếu công việc không thành công. Nếu cả hai đều đúng, thì bạn đã chủ động trong việc bảo trì. Và nếu bạn không làm được cả hai thì đó là điều cần khắc phục ngay bây giờ - như trong, hãy ngừng đọc phần này, tải xuống các tập lệnh của Ola Hallengren, lên lịch cho chúng và đảm bảo rằng bạn đã thiết lập thông báo. (Một giải pháp thay thế cụ thể khác để duy trì chỉ mục, mà chúng tôi cũng đề xuất cho khách hàng, là SQL Sentry Fragmentation Manager.)
Nếu bạn không biết liệu công việc của mình có được đặt để gửi email cho bạn hay không nếu chúng không thành công, hãy sử dụng truy vấn sau:
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
Tuy nhiên, chủ động về bảo trì sẽ tiến thêm một bước nữa. Ngoài việc đảm bảo công việc của bạn chạy, bạn cần biết chúng mất bao lâu. Bạn có thể sử dụng bảng hệ thống trong msdb để theo dõi điều này:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; Hoặc, nếu bạn đang sử dụng các tập lệnh và thông tin ghi nhật ký của Ola, bạn có thể truy vấn bảng CommandLog của anh ấy:
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
Tập lệnh trên liệt kê thời lượng sao lưu cho mỗi bản sao lưu đầy đủ cho cơ sở dữ liệu AdventureWorks2014. Bạn có thể mong đợi rằng thời lượng tác vụ bảo trì sẽ từ từ tăng lên theo thời gian, khi cơ sở dữ liệu phát triển lớn hơn. Do đó, bạn đang tìm kiếm các mức tăng lớn hoặc giảm bất ngờ trong thời gian. Ví dụ:tôi có một khách hàng có thời lượng sao lưu trung bình dưới 30 phút. Đột nhiên, các bản sao lưu bắt đầu mất hơn một giờ. Cơ sở dữ liệu không thay đổi đáng kể về kích thước, không có cài đặt nào thay đổi cho phiên bản hoặc cơ sở dữ liệu, không có gì thay đổi với cấu hình phần cứng hoặc đĩa. Vài tuần sau, thời lượng sao lưu giảm xuống dưới nửa giờ. Một tháng sau đó, họ lại đi lên. Cuối cùng, chúng tôi đã xác định mối tương quan giữa sự thay đổi trong thời lượng sao lưu để chuyển đổi dự phòng giữa các nút cụm. Trên một nút, quá trình sao lưu mất chưa đầy nửa giờ. Mặt khác, họ mất hơn một giờ. Một cuộc điều tra nhỏ về cấu hình của NIC và kết cấu SAN và chúng tôi có thể xác định chính xác vấn đề.
Hiểu thời gian thực hiện trung bình cho các hoạt động CHECKDB cũng rất quan trọng. Đây là điều mà Paul nói đến trong Sự kiện hòa nhập vào khả năng sẵn sàng cao và khôi phục sau thảm họa của chúng tôi:bạn phải biết CHECKDB thường mất bao lâu để chạy, để nếu bạn phát hiện thấy lỗi và bạn chạy kiểm tra trên toàn bộ cơ sở dữ liệu, bạn sẽ biết nó sẽ mất bao lâu lấy CHECKDB để hoàn thành. Khi sếp của bạn hỏi, "Còn bao lâu nữa cho đến khi chúng tôi biết được mức độ của vấn đề?" bạn sẽ có thể đưa ra câu trả lời định lượng về khoảng thời gian tối thiểu mà bạn cần chờ đợi. Nếu CHECKDB mất nhiều thời gian hơn bình thường, thì bạn biết nó đã tìm thấy thứ gì đó (có thể không nhất thiết là lỗi; bạn phải luôn để quá trình kiểm tra kết thúc).
Bây giờ, nếu bạn đang quản lý hàng trăm cơ sở dữ liệu, bạn không muốn chạy truy vấn trên cho mọi cơ sở dữ liệu hoặc mọi công việc. Thay vào đó, bạn có thể chỉ muốn tìm công việc nằm ngoài thời lượng trung bình theo một tỷ lệ phần trăm nhất định, bạn có thể nhận được bằng cách sử dụng truy vấn sau:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; Truy vấn này liệt kê các công việc mất nhiều thời gian hơn 25% so với mức trung bình. Truy vấn sẽ yêu cầu một số điều chỉnh để cung cấp thông tin cụ thể mà bạn muốn - một số công việc có thời lượng nhỏ (ví dụ:dưới 5 phút) sẽ hiển thị nếu chúng chỉ mất thêm vài phút - điều đó có thể không đáng lo ngại. Tuy nhiên, truy vấn này là một khởi đầu tốt và nhận ra rằng có nhiều cách để tìm sai lệch - bạn cũng có thể so sánh mỗi lần thực hiện với lần trước và tìm kiếm công việc mất một tỷ lệ phần trăm nhất định so với lần trước.
Rõ ràng, thời hạn công việc là số nhận dạng hợp lý nhất để sử dụng cho các vấn đề tiềm ẩn - cho dù đó là công việc sao lưu, kiểm tra tính toàn vẹn hay công việc loại bỏ phân mảnh và cập nhật số liệu thống kê. Tôi nhận thấy rằng sự thay đổi lớn nhất về thời lượng thường nằm trong các tác vụ xóa phân mảnh và cập nhật thống kê. Tùy thuộc vào ngưỡng của bạn cho việc xây dựng lại so với xây dựng lại và sự biến động của dữ liệu, bạn có thể mất nhiều ngày với hầu hết các bản tải lại, sau đó đột nhiên có một vài bản xây dựng lại chỉ mục bắt đầu hoạt động cho các bảng lớn, nơi những bản xây dựng lại đó hoàn toàn thay đổi thời lượng trung bình. Bạn có thể muốn thay đổi ngưỡng của mình cho một số chỉ mục hoặc điều chỉnh hệ số lấp đầy để việc xây dựng lại diễn ra thường xuyên hơn hoặc ít thường xuyên hơn - tùy thuộc vào chỉ số và mức độ phân mảnh. Để thực hiện những điều chỉnh này, bạn cần xem tần suất từng chỉ mục được xây dựng lại hoặc tổ chức lại, điều này bạn chỉ có thể thực hiện nếu bạn đang sử dụng tập lệnh của Ola và đăng nhập vào bảng CommandLog hoặc nếu bạn đã triển khai giải pháp của riêng mình và đang ghi nhật ký. mỗi lần tổ chức lại hoặc xây dựng lại. Để xem điều này bằng cách sử dụng bảng CommandLog, bạn có thể bắt đầu bằng cách kiểm tra xem chỉ mục nào bị thay đổi thường xuyên nhất:
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
Từ kết quả đầu ra này, bạn có thể bắt đầu xem bảng nào (và do đó chỉ mục) có mức độ biến động cao nhất và sau đó xác định xem có cần điều chỉnh ngưỡng cho việc sắp xếp lại so với xây dựng lại hay hệ số lấp đầy được sửa đổi hay không.
Làm cho cuộc sống trở nên dễ dàng hơn
Giờ đây, có một giải pháp dễ dàng hơn là viết các truy vấn của riêng bạn, miễn là bạn đang sử dụng SQL Sentry Event Manager (EM). Công cụ giám sát tất cả các công việc Agent được thiết lập trên một phiên bản và sử dụng chế độ xem lịch, bạn có thể nhanh chóng xem công việc nào bị lỗi, bị hủy hoặc chạy lâu hơn bình thường:
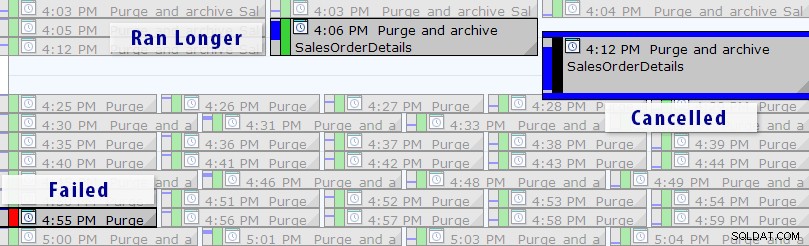 Chế độ xem lịch SQL Sentry Event Manager (có thêm nhãn trong Photoshop)
Chế độ xem lịch SQL Sentry Event Manager (có thêm nhãn trong Photoshop)
Bạn cũng có thể đi sâu vào các lần thực thi riêng lẻ để xem công việc mất bao lâu để chạy và cũng có các biểu đồ thời gian chạy tiện dụng cho phép bạn nhanh chóng hình dung bất kỳ mẫu nào về thời lượng bất thường hoặc điều kiện lỗi. Trong trường hợp này, tôi có thể thấy rằng cứ sau 15 phút, thời lượng thời gian chạy cho công việc cụ thể này đã tăng gần 400%:
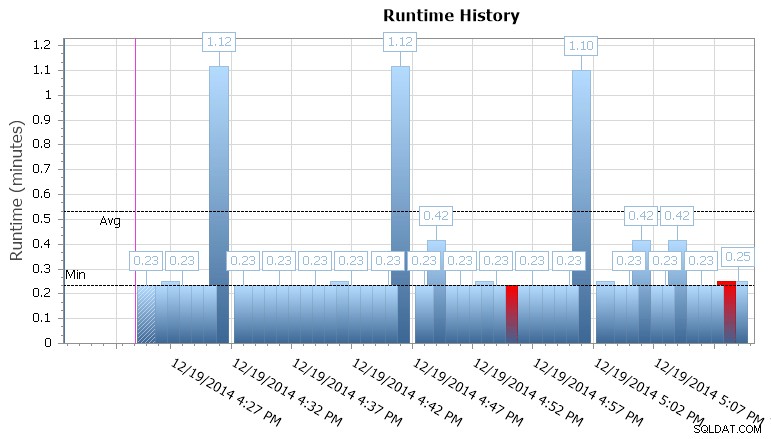 Biểu đồ thời gian chạy SQL Sentry Event Manager
Biểu đồ thời gian chạy SQL Sentry Event Manager
Điều này cho tôi manh mối rằng tôi nên xem xét các công việc đã lên lịch khác có thể gây ra một số vấn đề đồng thời ở đây. Tôi có thể thu nhỏ trên lịch một lần nữa để xem những công việc khác đang chạy cùng thời điểm, hoặc tôi thậm chí có thể không cần nhìn để nhận ra rằng đây là một số công việc báo cáo hoặc sao lưu chạy dựa trên cơ sở dữ liệu này.
Tóm tắt
Tôi dám cá rằng hầu hết các bạn đều đã có sẵn các công việc bảo trì cần thiết và bạn cũng có các thông báo được thiết lập cho các trường hợp thất bại trong công việc. Nếu bạn không quen với thời lượng trung bình cho các công việc của mình, thì đó là bước tiếp theo để bạn chủ động. Lưu ý:bạn cũng có thể cần phải kiểm tra xem bạn đang lưu giữ lịch sử công việc trong bao lâu. Khi tìm kiếm sự sai lệch trong thời gian công việc, tôi thích xem xét dữ liệu của một vài tháng hơn là một vài tuần. Bạn không cần phải ghi nhớ những thời gian chạy đó, nhưng sau khi đã xác minh rằng bạn đang giữ đủ dữ liệu để có lịch sử sử dụng cho nghiên cứu, sau đó bắt đầu tìm kiếm các biến thể một cách thường xuyên. Trong một tình huống lý tưởng, thời gian chạy tăng lên có thể cảnh báo bạn về một vấn đề tiềm ẩn, cho phép bạn giải quyết nó trước khi sự cố xảy ra trong môi trường sản xuất của bạn.