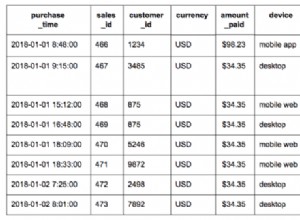
Bạn có thể DELETE từ một cte:
WITH cte AS (SELECT *,ROW_NUMBER() OVER(PARTITION BY uniqueid ORDER BY col2)'RowRank'
FROM Table)
DELETE FROM cte
WHERE RowRank > 1
ROW_NUMBER() hàm gán một số cho mỗi hàng. PARTITION BY được sử dụng để bắt đầu đánh số lại cho từng mục trong nhóm đó, trong trường hợp này là mỗi giá trị của uniqueid sẽ bắt đầu đánh số từ 1 và đi lên từ đó. ORDER BY xác định thứ tự các con số đi vào. Vì mỗi uniqueid được đánh số bắt đầu từ 1, bất kỳ bản ghi nào có ROW_NUMBER() lớn hơn 1 có uniqueid trùng lặp
Để hiểu về cách ROW_NUMBER() chức năng hoạt động, chỉ cần dùng thử:
SELECT *,ROW_NUMBER() OVER(PARTITION BY uniqueid ORDER BY col2)'RowRank'
FROM Table
ORDER BY uniqueid
Bạn có thể điều chỉnh logic của ROW_NUMBER() chức năng điều chỉnh bản ghi nào bạn sẽ giữ hoặc xóa.
Ví dụ:có lẽ bạn muốn thực hiện việc này theo nhiều bước, trước tiên hãy xóa các bản ghi có cùng họ nhưng tên khác, bạn có thể thêm họ vào PARTITION BY :
WITH cte AS (SELECT *,ROW_NUMBER() OVER(PARTITION BY uniqueid, col3 ORDER BY col2)'RowRank'
FROM Table)
DELETE FROM cte
WHERE RowRank > 1