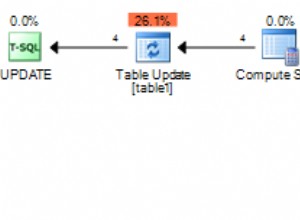
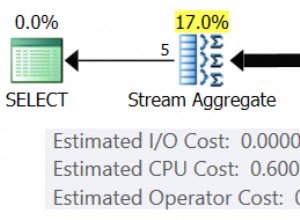
SQL Server là tốt nhất trong các hoạt động dựa trên tập hợp, trong khi CASCADE về bản chất, việc xóa dựa trên bản ghi.
SQL Server , không giống như các máy chủ khác, cố gắng tối ưu hóa các hoạt động dựa trên thiết lập tức thì, tuy nhiên, nó chỉ hoạt động sâu ở một cấp độ. Nó cần phải xóa các bản ghi trong các bảng cấp trên để xóa các bản ghi đó trong các bảng cấp dưới.
Nói cách khác, hoạt động xếp tầng hoạt động từ trên xuống, trong khi giải pháp của bạn hoạt động từ dưới lên, dựa trên thiết lập và hiệu quả hơn.
Đây là một lược đồ mẫu:
CREATE TABLE t_g (id INT NOT NULL PRIMARY KEY)
CREATE TABLE t_p (id INT NOT NULL PRIMARY KEY, g INT NOT NULL, CONSTRAINT fk_p_g FOREIGN KEY (g) REFERENCES t_g ON DELETE CASCADE)
CREATE TABLE t_c (id INT NOT NULL PRIMARY KEY, p INT NOT NULL, CONSTRAINT fk_c_p FOREIGN KEY (p) REFERENCES t_p ON DELETE CASCADE)
CREATE INDEX ix_p_g ON t_p (g)
CREATE INDEX ix_c_p ON t_c (p)
, truy vấn này:
DELETE
FROM t_g
WHERE id > 50000
và kế hoạch của nó:
|--Sequence
|--Table Spool
| |--Clustered Index Delete(OBJECT:([test].[dbo].[t_g].[PK__t_g__176E4C6B]), WHERE:([test].[dbo].[t_g].[id] > (50000)))
|--Index Delete(OBJECT:([test].[dbo].[t_p].[ix_p_g]) WITH ORDERED PREFETCH)
| |--Sort(ORDER BY:([test].[dbo].[t_p].[g] ASC, [test].[dbo].[t_p].[id] ASC))
| |--Table Spool
| |--Clustered Index Delete(OBJECT:([test].[dbo].[t_p].[PK__t_p__195694DD]) WITH ORDERED PREFETCH)
| |--Sort(ORDER BY:([test].[dbo].[t_p].[id] ASC))
| |--Merge Join(Inner Join, MERGE:([test].[dbo].[t_g].[id])=([test].[dbo].[t_p].[g]), RESIDUAL:([test].[dbo].[t_p].[g]=[test].[dbo].[t_g].[id]))
| |--Table Spool
| |--Index Scan(OBJECT:([test].[dbo].[t_p].[ix_p_g]), ORDERED FORWARD)
|--Index Delete(OBJECT:([test].[dbo].[t_c].[ix_c_p]) WITH ORDERED PREFETCH)
|--Sort(ORDER BY:([test].[dbo].[t_c].[p] ASC, [test].[dbo].[t_c].[id] ASC))
|--Clustered Index Delete(OBJECT:([test].[dbo].[t_c].[PK__t_c__1C330188]) WITH ORDERED PREFETCH)
|--Table Spool
|--Sort(ORDER BY:([test].[dbo].[t_c].[id] ASC))
|--Hash Match(Inner Join, HASH:([test].[dbo].[t_p].[id])=([test].[dbo].[t_c].[p]))
|--Table Spool
|--Index Scan(OBJECT:([test].[dbo].[t_c].[ix_c_p]), ORDERED FORWARD)
Đầu tiên, SQL Server xóa các bản ghi khỏi t_g , sau đó kết hợp các bản ghi đã xóa với t_p và xóa khỏi cái sau, cuối cùng, kết hợp các bản ghi đã xóa khỏi t_p với t_c và xóa khỏi t_c .
Một phép nối ba bảng sẽ hiệu quả hơn nhiều trong trường hợp này và đây là những gì bạn làm với cách giải quyết của mình.
Nếu nó làm cho bạn cảm thấy tốt hơn, Oracle không tối ưu hóa các hoạt động xếp tầng theo bất kỳ cách nào:chúng luôn là NESTED LOOPS và Chúa sẽ giúp bạn nếu bạn quên tạo chỉ mục trên cột tham chiếu.