Một tài nguyên tuyệt vời để tính toán các tổng đang chạy trong SQL Server là tài liệu này
bởi Itzik Ben Gan đã được gửi đến Nhóm máy chủ SQL như một phần của chiến dịch của anh ấy để có OVER được mở rộng thêm từ việc triển khai SQL Server 2005 ban đầu của nó. Trong đó, anh ấy chỉ ra cách một khi bạn vào hàng chục nghìn hàng, con trỏ thực hiện các giải pháp dựa trên bộ. SQL Server 2012 đã thực sự mở rộng OVER mệnh đề làm cho loại truy vấn này dễ dàng hơn nhiều.
SELECT col1,
SUM(col1) OVER (ORDER BY ind ROWS UNBOUNDED PRECEDING)
FROM @tmp
Tuy nhiên, khi bạn đang sử dụng SQL Server 2005, điều này không khả dụng với bạn.
Adam Machanic hiển thị ở đây cách CLR có thể được sử dụng để cải thiện hiệu suất của con trỏ TSQL tiêu chuẩn.
Đối với định nghĩa bảng này
CREATE TABLE RunningTotals
(
ind int identity(1,1) primary key,
col1 int
)
Tôi tạo bảng có cả 2.000 và 10.000 hàng trong cơ sở dữ liệu với ALLOW_SNAPSHOT_ISOLATION ON và một với cài đặt này bị tắt (Lý do cho điều này là vì kết quả ban đầu của tôi nằm trong DB với cài đặt trên dẫn đến một khía cạnh khó hiểu của kết quả).
Các chỉ mục nhóm cho tất cả các bảng chỉ có 1 trang gốc. Số lượng trang lá cho mỗi trang được hiển thị bên dưới.
+-------------------------------+-----------+------------+
| | 2,000 row | 10,000 row |
+-------------------------------+-----------+------------+
| ALLOW_SNAPSHOT_ISOLATION OFF | 5 | 22 |
| ALLOW_SNAPSHOT_ISOLATION ON | 8 | 39 |
+-------------------------------+-----------+------------+
Tôi đã thử nghiệm các trường hợp sau (Liên kết hiển thị kế hoạch thực thi)
- Tham gia Trái và Nhóm Theo
- Truy vấn con có liên quan Sơ đồ hàng 2000 , Sơ đồ hàng 10000
- CTE từ câu trả lời của Mikael (đã cập nhật)
- CTE bên dưới
Lý do đưa vào tùy chọn CTE bổ sung là để cung cấp giải pháp CTE vẫn hoạt động nếu ind cột không được đảm bảo tuần tự.
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
DECLARE @col1 int, @sumcol1 bigint;
WITH RecursiveCTE
AS (
SELECT TOP 1 ind, col1, CAST(col1 AS BIGINT) AS Total
FROM RunningTotals
ORDER BY ind
UNION ALL
SELECT R.ind, R.col1, R.Total
FROM (
SELECT T.*,
T.col1 + Total AS Total,
rn = ROW_NUMBER() OVER (ORDER BY T.ind)
FROM RunningTotals T
JOIN RecursiveCTE R
ON R.ind < T.ind
) R
WHERE R.rn = 1
)
SELECT @col1 =col1, @sumcol1=Total
FROM RecursiveCTE
OPTION (MAXRECURSION 0);
Tất cả các truy vấn đều có CAST(col1 AS BIGINT) được thêm vào để tránh lỗi tràn khi chạy. Ngoài ra, đối với tất cả chúng, tôi đã gán kết quả cho các biến như trên để loại bỏ thời gian xem xét gửi lại kết quả.
Kết quả
+------------------+----------+--------+------------+---------------+------------+---------------+-------+---------+
| | | | Base Table | Work Table | Time |
+------------------+----------+--------+------------+---------------+------------+---------------+-------+---------+
| | Snapshot | Rows | Scan count | logical reads | Scan count | logical reads | cpu | elapsed |
| Group By | On | 2,000 | 2001 | 12709 | | | 1469 | 1250 |
| | On | 10,000 | 10001 | 216678 | | | 30906 | 30963 |
| | Off | 2,000 | 2001 | 9251 | | | 1140 | 1160 |
| | Off | 10,000 | 10001 | 130089 | | | 29906 | 28306 |
+------------------+----------+--------+------------+---------------+------------+---------------+-------+---------+
| Sub Query | On | 2,000 | 2001 | 12709 | | | 844 | 823 |
| | On | 10,000 | 2 | 82 | 10000 | 165025 | 24672 | 24535 |
| | Off | 2,000 | 2001 | 9251 | | | 766 | 999 |
| | Off | 10,000 | 2 | 48 | 10000 | 165025 | 25188 | 23880 |
+------------------+----------+--------+------------+---------------+------------+---------------+-------+---------+
| CTE No Gaps | On | 2,000 | 0 | 4002 | 2 | 12001 | 78 | 101 |
| | On | 10,000 | 0 | 20002 | 2 | 60001 | 344 | 342 |
| | Off | 2,000 | 0 | 4002 | 2 | 12001 | 62 | 253 |
| | Off | 10,000 | 0 | 20002 | 2 | 60001 | 281 | 326 |
+------------------+----------+--------+------------+---------------+------------+---------------+-------+---------+
| CTE Alllows Gaps | On | 2,000 | 2001 | 4009 | 2 | 12001 | 47 | 75 |
| | On | 10,000 | 10001 | 20040 | 2 | 60001 | 312 | 413 |
| | Off | 2,000 | 2001 | 4006 | 2 | 12001 | 94 | 90 |
| | Off | 10,000 | 10001 | 20023 | 2 | 60001 | 313 | 349 |
+------------------+----------+--------+------------+---------------+------------+---------------+-------+---------+
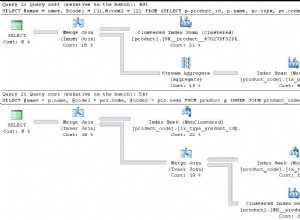
Cả truy vấn con tương quan và GROUP BY phiên bản sử dụng các phép nối vòng lặp lồng nhau "hình tam giác" được điều khiển bởi quá trình quét chỉ mục theo cụm trên RunningTotals bảng (T1 ) và, đối với mỗi hàng được trả về bởi quá trình quét đó, tìm kiếm trở lại bảng (T2 ) tự tham gia trên T2.ind<=T1.ind .
Điều này có nghĩa là các hàng giống nhau được xử lý lặp đi lặp lại. Khi T1.ind=1000 hàng được xử lý, truy xuất tự nối và tính tổng tất cả các hàng bằng ind <= 1000 , sau đó cho hàng tiếp theo, nơi T1.ind=1001 1000 hàng giống nhau được truy xuất lại và được tổng hợp cùng với một hàng bổ sung, v.v.
Tổng số thao tác như vậy đối với bảng 2.000 hàng là 2.001.000, đối với 10k hàng là 50.005.000 hoặc nói chung hơn (n² + n) / 2
rõ ràng tăng trưởng theo cấp số nhân.
Trong trường hợp hàng 2.000, sự khác biệt chính giữa GROUP BY và các phiên bản truy vấn con là phiên bản trước có tổng hợp luồng sau phép nối và do đó có ba cột cấp dữ liệu vào đó (T1.ind , T2.col1 , T2.col1 ) và một GROUP BY thuộc tính của T1.ind trong khi cái sau được tính là tổng hợp vô hướng, với tổng luồng trước khi tham gia, chỉ có T2.col1 đưa vào nó và không có GROUP BY tài sản được thiết lập ở tất cả. Sự sắp xếp đơn giản hơn này có thể mang lại lợi ích có thể đo lường được khi giảm thời gian sử dụng CPU.
Đối với trường hợp 10.000 hàng, có sự khác biệt bổ sung trong kế hoạch truy vấn phụ. Nó thêm một cuộn háo hức
mà sao chép tất cả ind,cast(col1 as bigint) giá trị thành tempdb . Trong trường hợp cách ly ảnh chụp nhanh, điều này hoạt động nhỏ gọn hơn so với cấu trúc chỉ mục nhóm và hiệu quả thực là giảm số lần đọc khoảng 25% (vì bảng cơ sở giữ lại khá nhiều không gian trống cho thông tin lập phiên bản), khi tắt tùy chọn này, nó hoạt động kém gọn gàng hơn (có lẽ là do bigint so với int khác biệt) và kết quả đọc nhiều hơn. Điều này làm giảm khoảng cách giữa truy vấn phụ và nhóm theo các phiên bản nhưng truy vấn phụ vẫn thắng.
Tuy nhiên, người chiến thắng rõ ràng là CTE đệ quy. Đối với phiên bản "không có khoảng trống", các lần đọc logic từ bảng cơ sở hiện là 2 x (n + 1) phản ánh n chỉ mục tìm kiếm chỉ mục cấp 2 để truy xuất tất cả các hàng cộng với hàng bổ sung ở cuối mà không trả về gì và kết thúc đệ quy. Tuy nhiên, điều đó vẫn có nghĩa là 20.002 lần đọc để xử lý một bảng 22 trang!
Số lần đọc bảng logic cho phiên bản CTE đệ quy rất cao. Nó dường như hoạt động ở 6 lần đọc bảng làm việc cho mỗi hàng nguồn. Chúng đến từ ống chỉ mục lưu trữ đầu ra của hàng trước đó sau đó được đọc lại từ lần lặp tiếp theo (giải thích tốt về điều này bởi Umachandar Jayachandran tại đây ). Mặc dù con số cao, đây vẫn là nghệ sĩ hoạt động tốt nhất.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}