Trong hướng dẫn Hadoop trước đây của chúng tôi , chúng tôi đã nghiên cứu về Hadoop Partitioner chi tiết. Bây giờ chúng ta sẽ thảo luận về InputSplit trong Hadoop MapReduce.
Ở đây, chúng ta sẽ đề cập đến Hadoop InputSplit là gì, sự cần thiết của InputSplit trong MapReduce. Chúng tôi cũng sẽ thảo luận chi tiết về cách tạo các InputSplits này trong Hadoop MapReduce.
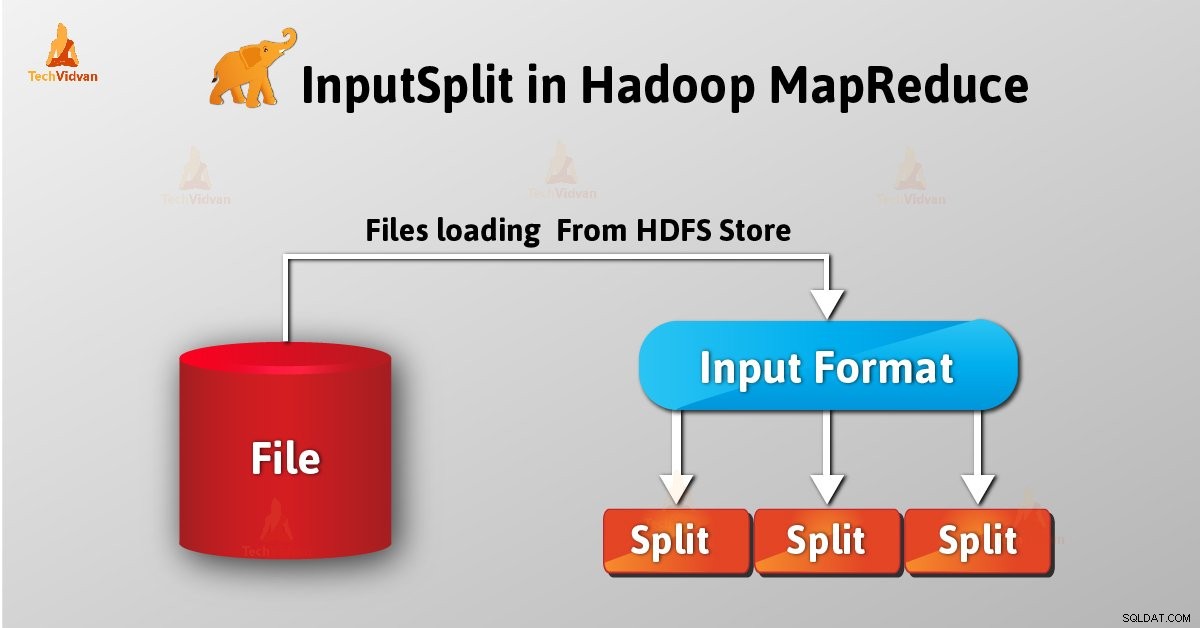
Giới thiệu về InputSplit trong Hadoop
InputSplit là biểu diễn logic của dữ liệu trong Hadoop MapReduce. Nó đại diện cho dữ liệu mà người lập bản đồ riêng lẻ các quy trình. Vì vậy, số lượng nhiệm vụ bản đồ bằng số lượng InputSplits. Framework chia tách thành các bản ghi, mà trình ánh xạ xử lý.
Độ dài MapReduce InputSplit đã được đo bằng byte. Mọi InputSplit đều có vị trí lưu trữ (chuỗi tên máy chủ). Hệ thống MapReduce đặt các tác vụ bản đồ càng gần với dữ liệu của phần tách càng tốt bằng cách sử dụng các vị trí lưu trữ.
Các quy trình của Framework Ánh xạ các tác vụ theo thứ tự kích thước của các phần tách sao cho phần lớn nhất được xử lý trước (thuật toán xấp xỉ tham lam). Điều này giảm thiểu thời gian chạy công việc.
Điều chính cần tập trung là Inputsplit không chứa dữ liệu đầu vào; nó chỉ là một tham chiếu đến dữ liệu.
Cách tạo InputSplits trong Hadoop MapReduce?
Với tư cách là người dùng, chúng tôi không xử lý trực tiếp InputSplit trong Hadoop với tư cách là InputFormat (vì InputFormat chịu trách nhiệm tạo Inputsplit và phân chia thành các bản ghi) tạo ra nó. FileInputFormat chia một tệp thành các phần 128MB.
Ngoài ra, bằng cách đặt được lập bản đồ . tối thiểu . tách . kích thước tham số trong mapred-site . xml người dùng có thể thay đổi giá trị theo yêu cầu. Cũng bằng cách này, chúng tôi có thể ghi đè tham số trong đối tượng Job được sử dụng để gửi một công việc MapReduce cụ thể.
Bằng cách viết InputFormat tùy chỉnh, chúng tôi cũng có thể kiểm soát cách tệp được chia thành các phần.
InputSplit do người dùng xác định. Người dùng cũng có thể kiểm soát kích thước phân chia dựa trên kích thước dữ liệu trong chương trình MapReduce. Do đó, trong một công việc MapReduce, số lượng nhiệm vụ bản đồ thực thi bằng số lượng InputSplits.
Bằng cách gọi ‘getSplit ()’ , khách hàng tính toán sự phân chia cho công việc. Sau đó, nó được gửi đến ứng dụng chính, sử dụng vị trí lưu trữ của chúng để lên lịch các tác vụ bản đồ sẽ xử lý chúng trên cụm.
Sau khi tác vụ bản đồ đó chuyển phần tách cho createRecordReader () phương pháp. Từ đó nó nhận được RecordReader cho sự phân chia. Sau đó, RecordReader tạo bản ghi (cặp khóa-giá trị) , nó được chuyển đến chức năng bản đồ.
Kết luận
Kết luận, chúng ta có thể nói rằng, InputSplit đại diện cho dữ liệu mà người lập bản đồ riêng lẻ xử lý. Đối với mỗi phần tách, một nhiệm vụ bản đồ được tạo. Do đó, InputFormat tạo InputSplit.
Nếu bạn có bất kỳ câu hỏi nào về InputSplit trong MapReduce, vui lòng để lại nhận xét trong phần đưa ra bên dưới.



