Ngày nay, chúng ta thường thấy một lượng lớn dữ liệu trong cơ sở dữ liệu của công ty, nhưng tùy thuộc vào kích thước, nó có thể khó quản lý và hiệu suất có thể bị ảnh hưởng khi lưu lượng truy cập cao nếu chúng ta không định cấu hình hoặc triển khai nó một cách chính xác . Nói chung, nếu chúng tôi có một cơ sở dữ liệu khổng lồ và chúng tôi muốn có thời gian phản hồi thấp, chúng tôi sẽ muốn mở rộng nó. PostgreSQL không phải là ngoại lệ cho đến thời điểm này. Có nhiều cách tiếp cận có sẵn để mở rộng PostgreSQL, nhưng trước tiên, chúng ta hãy tìm hiểu quy mô là gì.
Khả năng mở rộng là thuộc tính của hệ thống / cơ sở dữ liệu để xử lý lượng nhu cầu ngày càng tăng bằng cách thêm tài nguyên.
Các lý do giải thích cho số lượng nhu cầu này có thể là tạm thời, chẳng hạn như nếu chúng tôi tung ra một đợt giảm giá hoặc vĩnh viễn để tăng lượng khách hàng hoặc nhân viên. Trong mọi trường hợp, chúng tôi có thể thêm hoặc xóa tài nguyên để quản lý những thay đổi này theo yêu cầu hoặc sự gia tăng lưu lượng truy cập.
Trong blog này, chúng ta sẽ xem xét cách chúng ta có thể mở rộng cơ sở dữ liệu PostgreSQL của mình và khi nào chúng ta cần làm điều đó.
Tỷ lệ theo chiều ngang so với Tỷ lệ theo chiều dọc
Có hai cách chính để mở rộng cơ sở dữ liệu của chúng tôi ...
- Chia tỷ lệ theo chiều ngang (mở rộng quy mô):Nó được thực hiện bằng cách thêm nhiều nút cơ sở dữ liệu hơn để tạo hoặc tăng một cụm cơ sở dữ liệu.
- Chia tỷ lệ theo chiều dọc (mở rộng quy mô):Nó được thực hiện bằng cách thêm nhiều tài nguyên phần cứng hơn (CPU, Bộ nhớ, Đĩa) vào một nút cơ sở dữ liệu hiện có.
Đối với Tỷ lệ theo chiều ngang, chúng ta có thể thêm nhiều nút cơ sở dữ liệu làm nút phụ. Nó có thể giúp chúng tôi cải thiện hiệu suất đọc cân bằng lưu lượng giữa các nút. Trong trường hợp này, chúng tôi sẽ cần thêm bộ cân bằng tải để phân phối lưu lượng truy cập đến đúng nút tùy thuộc vào chính sách và trạng thái của nút.
Để tránh một điểm không thành công khi chỉ thêm một bộ cân bằng tải, chúng ta nên xem xét thêm hai hoặc nhiều nút cân bằng tải và sử dụng một số công cụ như “Keepalived”, để đảm bảo tính khả dụng.
Vì PostgreSQL không có hỗ trợ đa tổng thể, nên nếu chúng tôi muốn triển khai nó để cải thiện hiệu suất ghi, chúng tôi sẽ cần sử dụng một công cụ bên ngoài cho tác vụ này.
Đối với Tỷ lệ theo chiều dọc, có thể cần thay đổi một số tham số cấu hình để cho phép PostgreSQL sử dụng tài nguyên phần cứng mới hoặc tốt hơn. Hãy xem một số tham số này từ tài liệu PostgreSQL.
- work_mem:Chỉ định dung lượng bộ nhớ được sử dụng bởi các hoạt động sắp xếp nội bộ và bảng băm trước khi ghi vào các tệp đĩa tạm thời. Một số phiên đang chạy có thể thực hiện các thao tác như vậy đồng thời, vì vậy tổng bộ nhớ được sử dụng có thể gấp nhiều lần giá trị của work_mem.
- duy trì_work_mem:Chỉ định dung lượng bộ nhớ tối đa được sử dụng bởi các hoạt động bảo trì, chẳng hạn như VACUUM, CREATE INDEX và ALTER TABLE ADD FOREIGN KEY. Các cài đặt lớn hơn có thể cải thiện hiệu suất cho việc hút bụi và khôi phục các kết xuất cơ sở dữ liệu.
- autovacuum_work_mem:Chỉ định dung lượng bộ nhớ tối đa được sử dụng bởi mỗi quy trình autovacuum worker.
- autovacuum_max_workers:Chỉ định số lượng quy trình autovacuum tối đa có thể đang chạy cùng một lúc.
- max_worker_processes:Đặt số lượng quy trình nền tối đa mà hệ thống có thể hỗ trợ. Chỉ định giới hạn của quy trình như hút bụi, điểm kiểm tra và các công việc bảo trì khác.
- max_parallel_workers:Đặt số lượng công nhân tối đa mà hệ thống có thể hỗ trợ cho các hoạt động song song. Các công nhân song song được lấy từ nhóm các quy trình công nhân được thiết lập bởi tham số trước đó.
- max_parallel_maintenance_workers:Đặt số lượng công nhân song song tối đa có thể được khởi động bằng một lệnh tiện ích. Hiện tại, lệnh tiện ích song song duy nhất hỗ trợ việc sử dụng công nhân song song là CREATE INDEX và chỉ khi tạo chỉ mục B-tree.
- effect_cache_size:Đặt giả định của người lập kế hoạch về kích thước hiệu quả của bộ nhớ cache trên đĩa khả dụng cho một truy vấn. Điều này được tính vào các ước tính về chi phí sử dụng một chỉ số; giá trị cao hơn thì khả năng quét chỉ mục sẽ được sử dụng nhiều hơn, giá trị thấp hơn khiến khả năng quét tuần tự sẽ được sử dụng nhiều hơn.
- shared_buffers:Đặt dung lượng bộ nhớ mà máy chủ cơ sở dữ liệu sử dụng cho các vùng đệm bộ nhớ được chia sẻ. Thường cần cài đặt cao hơn đáng kể so với mức tối thiểu để có hiệu suất tốt.
- temp_buffers:Đặt số lượng bộ đệm tạm thời tối đa được sử dụng bởi mỗi phiên cơ sở dữ liệu. Đây là các bộ đệm phiên-cục bộ chỉ được sử dụng để truy cập vào các bảng tạm thời.
- effect_io_concurrency:Đặt số lượng các hoạt động I / O đĩa đồng thời mà PostgreSQL mong đợi có thể được thực thi đồng thời. Việc nâng giá trị này sẽ làm tăng số lượng hoạt động I / O mà bất kỳ phiên PostgreSQL riêng lẻ nào cố gắng thực hiện song song. Hiện tại, cài đặt này chỉ ảnh hưởng đến các lần quét vùng bitmap.
- max_connections:Xác định số lượng tối đa các kết nối đồng thời đến máy chủ cơ sở dữ liệu. Việc tăng thông số này cho phép PostgreSQL chạy đồng thời nhiều quy trình phụ trợ hơn.
Tại thời điểm này, có một câu hỏi mà chúng ta phải đặt ra. Làm thế nào chúng tôi có thể biết liệu chúng tôi có cần mở rộng cơ sở dữ liệu của mình hay không và làm thế nào chúng tôi có thể biết cách tốt nhất để làm điều đó?
Giám sát
Mở rộng cơ sở dữ liệu PostgreSQL của chúng tôi là một quá trình phức tạp, vì vậy chúng tôi nên kiểm tra một số chỉ số để có thể xác định chiến lược tốt nhất để mở rộng cơ sở dữ liệu đó.
Chúng tôi có thể theo dõi việc sử dụng CPU, Bộ nhớ và Đĩa để xác định xem có vấn đề về cấu hình nào đó không hoặc nếu thực sự, chúng tôi cần mở rộng cơ sở dữ liệu của mình. Ví dụ:nếu chúng tôi thấy máy chủ tải cao nhưng hoạt động cơ sở dữ liệu thấp, có thể không cần mở rộng quy mô, chúng tôi chỉ cần kiểm tra các thông số cấu hình để khớp với tài nguyên phần cứng của chúng tôi.
Kiểm tra dung lượng đĩa được sử dụng bởi nút PostgreSQL trên mỗi cơ sở dữ liệu có thể giúp chúng tôi xác nhận xem chúng tôi có cần thêm đĩa hoặc thậm chí là phân vùng bảng hay không. Để kiểm tra dung lượng ổ đĩa được sử dụng bởi cơ sở dữ liệu / bảng, chúng ta có thể sử dụng một số hàm PostgreSQL như pg_database_size hoặc pg_table_size.
Từ phía cơ sở dữ liệu, chúng ta nên kiểm tra
- Số lượng kết nối
- Đang chạy các truy vấn
- Sử dụng chỉ mục
- Bloat
- Trễ sao chép
Đây có thể là những số liệu rõ ràng để xác nhận xem có cần mở rộng cơ sở dữ liệu của chúng tôi hay không.
ClusterControl như một hệ thống giám sát và mở rộng quy mô
ClusterControl có thể giúp chúng tôi đối phó với cả hai cách mở rộng mà chúng tôi đã thấy trước đó và theo dõi tất cả các số liệu cần thiết để xác nhận yêu cầu mở rộng. Hãy xem cách ...
Nếu bạn chưa sử dụng ClusterControl, bạn có thể cài đặt nó và triển khai hoặc nhập cơ sở dữ liệu PostgreSQL hiện tại của mình bằng cách chọn tùy chọn “Nhập” và làm theo các bước, để tận dụng tất cả các tính năng của ClusterControl như sao lưu, chuyển đổi dự phòng tự động, cảnh báo, giám sát, và hơn thế nữa.
Tỷ lệ theo chiều ngang
Đối với tính năng mở rộng theo chiều ngang, nếu chúng tôi chuyển đến các hành động cụm và chọn “Thêm mô hình nhân rộng”, chúng tôi có thể tạo bản sao mới từ đầu hoặc thêm cơ sở dữ liệu PostgreSQL hiện có làm bản sao.
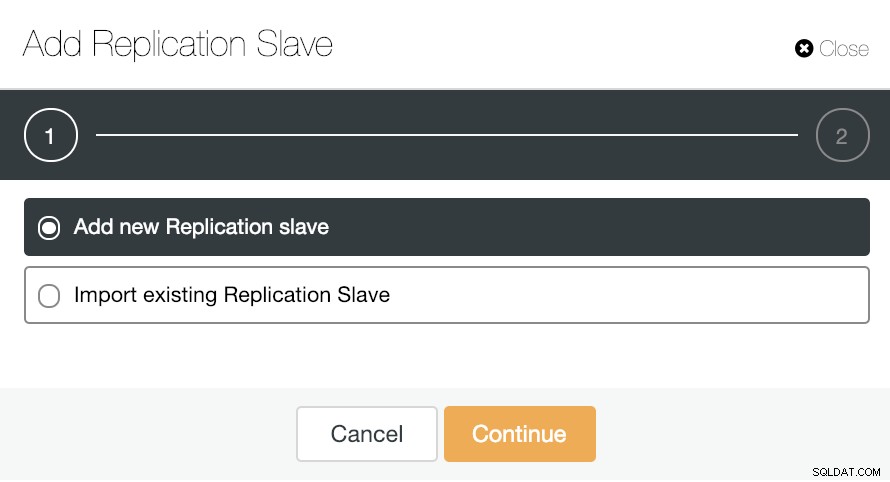
Hãy xem việc thêm một nô lệ sao chép mới có thể là một nhiệm vụ thực sự dễ dàng như thế nào.
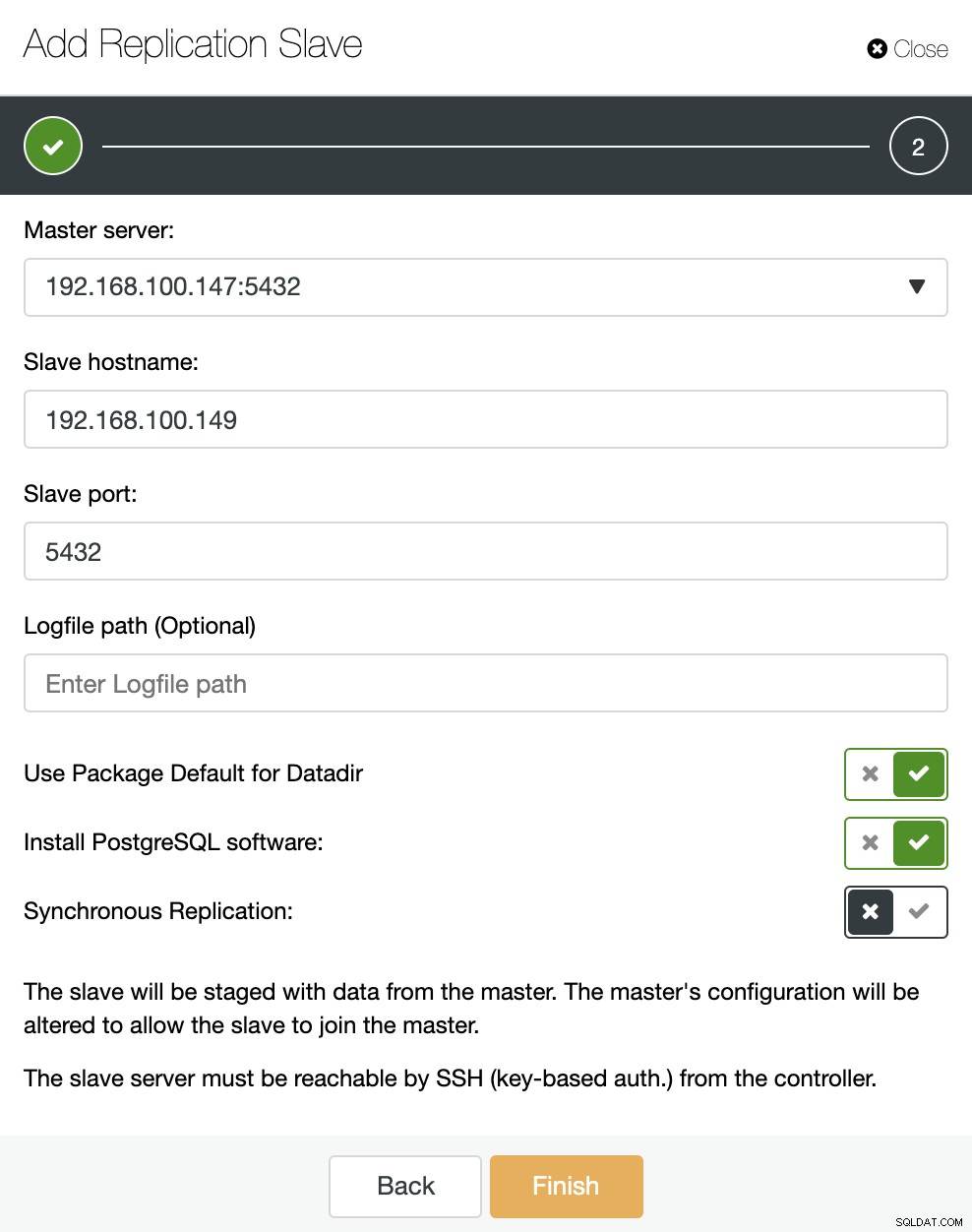
Như bạn có thể thấy trong hình, chúng ta chỉ cần chọn máy chủ Master của mình, nhập địa chỉ IP cho máy chủ nô lệ mới của chúng tôi và cổng cơ sở dữ liệu. Sau đó, chúng tôi có thể chọn nếu chúng tôi muốn ClusterControl cài đặt phần mềm cho chúng tôi và nếu nô lệ nhân bản phải là Đồng bộ hoặc Không đồng bộ.
Bằng cách này, chúng tôi có thể thêm bao nhiêu bản sao tùy thích và lan truyền lưu lượng đọc giữa chúng bằng cách sử dụng bộ cân bằng tải, mà chúng tôi cũng có thể triển khai với ClusterControl.
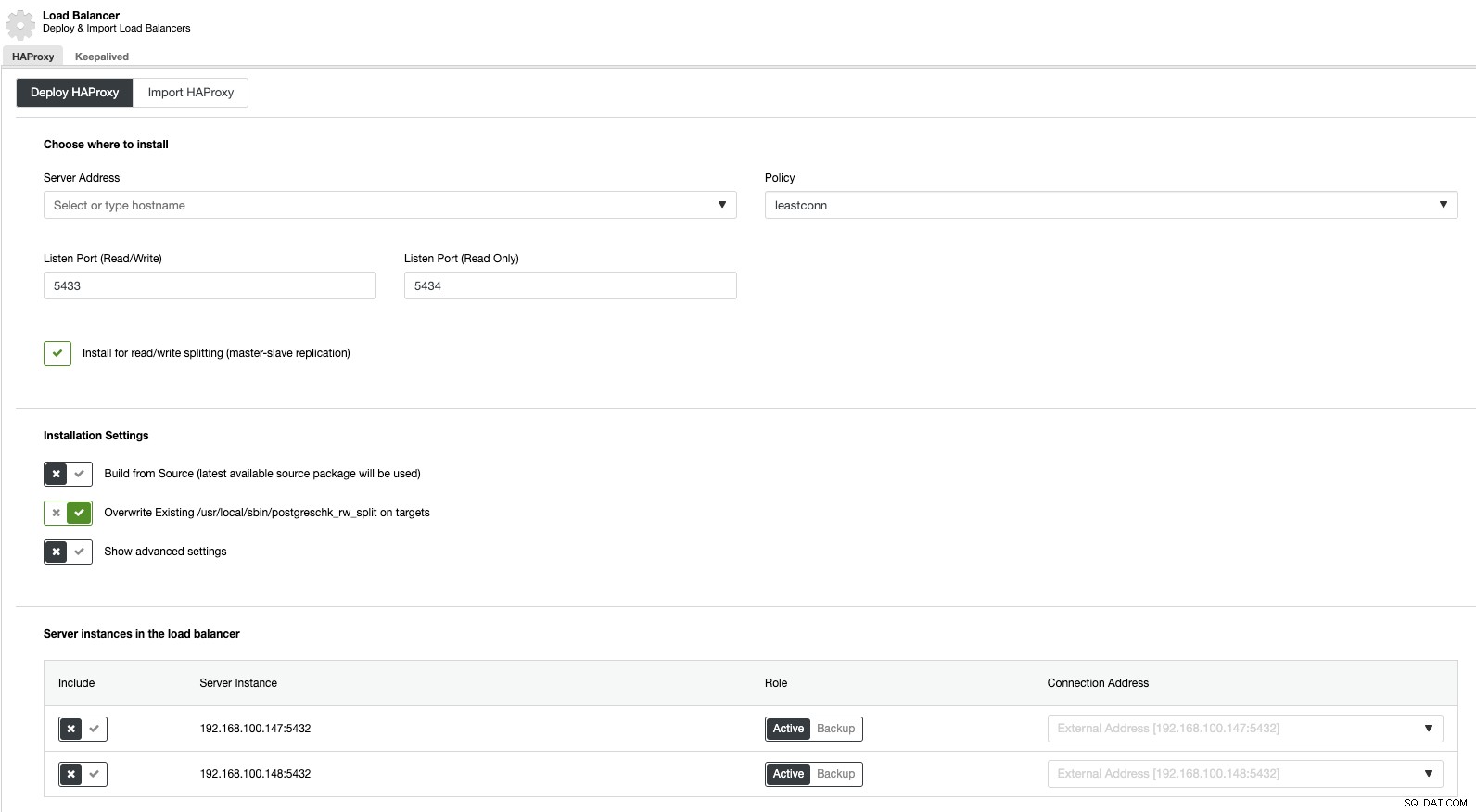
Bây giờ, nếu chúng ta chuyển đến các hành động cụm và chọn “Thêm Bộ cân bằng tải”, chúng ta có thể triển khai Bộ cân bằng tải HAProxy mới hoặc thêm một bộ cân bằng tải hiện có.
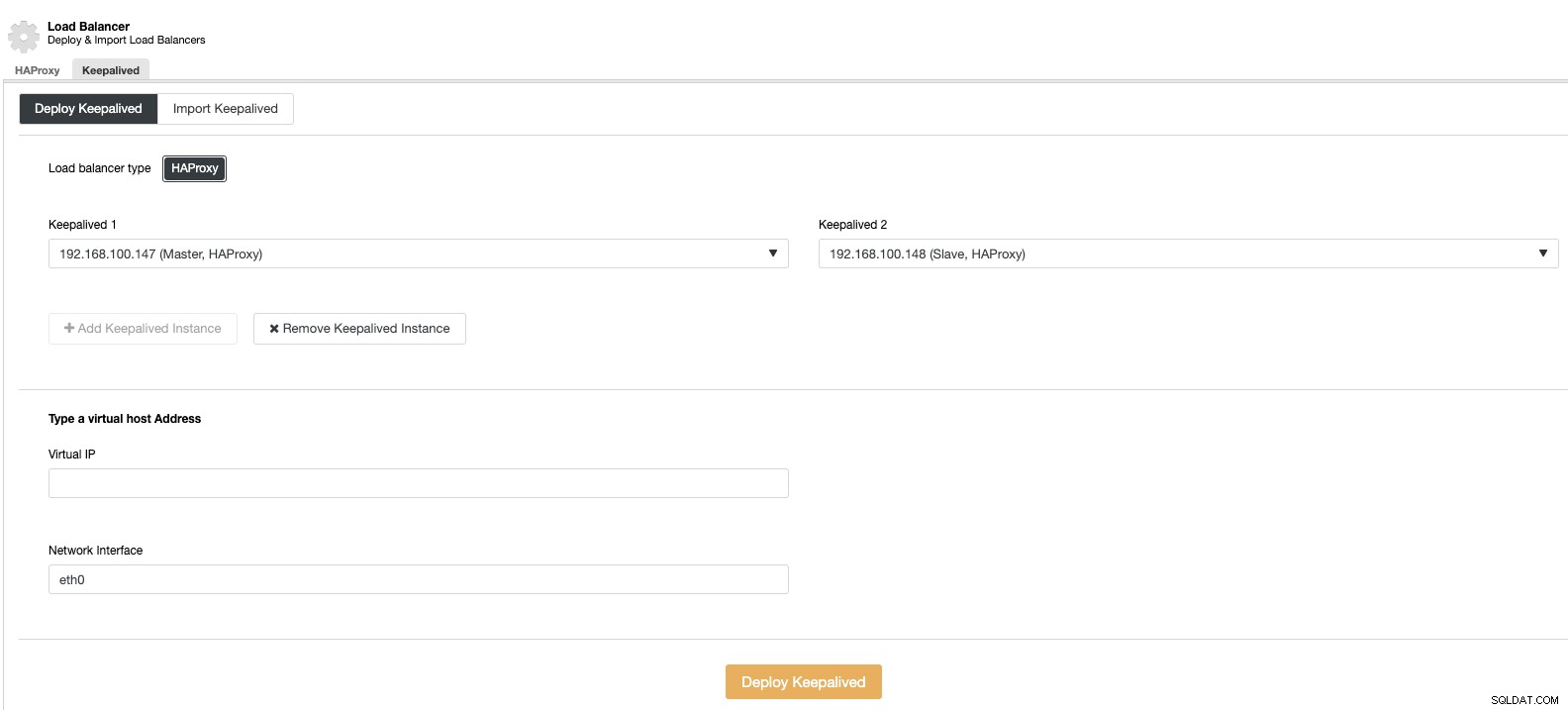
Và sau đó, trong cùng phần cân bằng tải, chúng ta có thể thêm dịch vụ Keepalived chạy trên các nút của bộ cân bằng tải để cải thiện môi trường khả dụng cao của chúng tôi.
Tỷ lệ theo chiều dọc
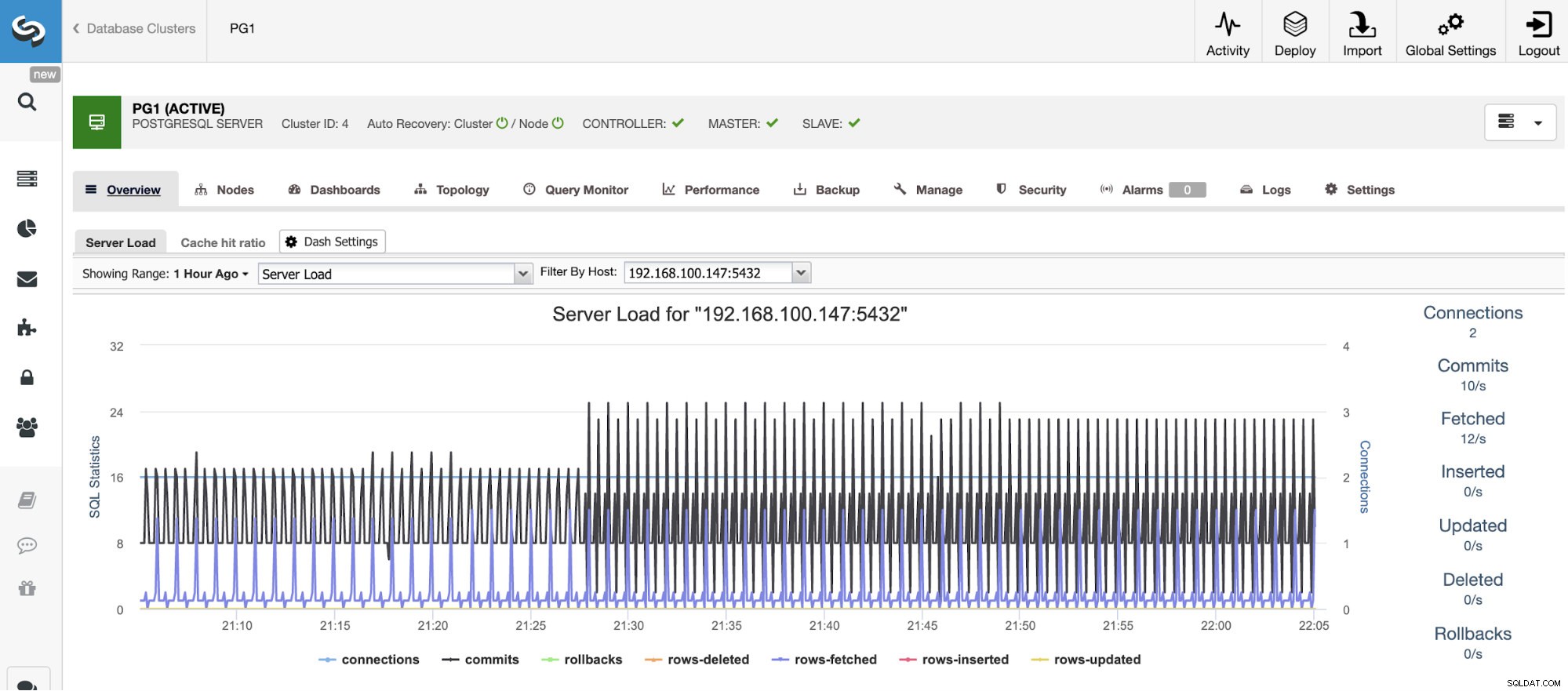
Để mở rộng quy mô dọc, với ClusterControl, chúng ta có thể giám sát các nút cơ sở dữ liệu của mình từ cả hệ điều hành và phía cơ sở dữ liệu. Chúng tôi có thể kiểm tra một số chỉ số như mức sử dụng CPU, Bộ nhớ, kết nối, truy vấn hàng đầu, truy vấn đang chạy và thậm chí hơn thế nữa. Chúng tôi cũng có thể bật phần Trang tổng quan, cho phép chúng tôi xem các số liệu chi tiết hơn và theo cách thân thiện hơn các số liệu của chúng tôi.
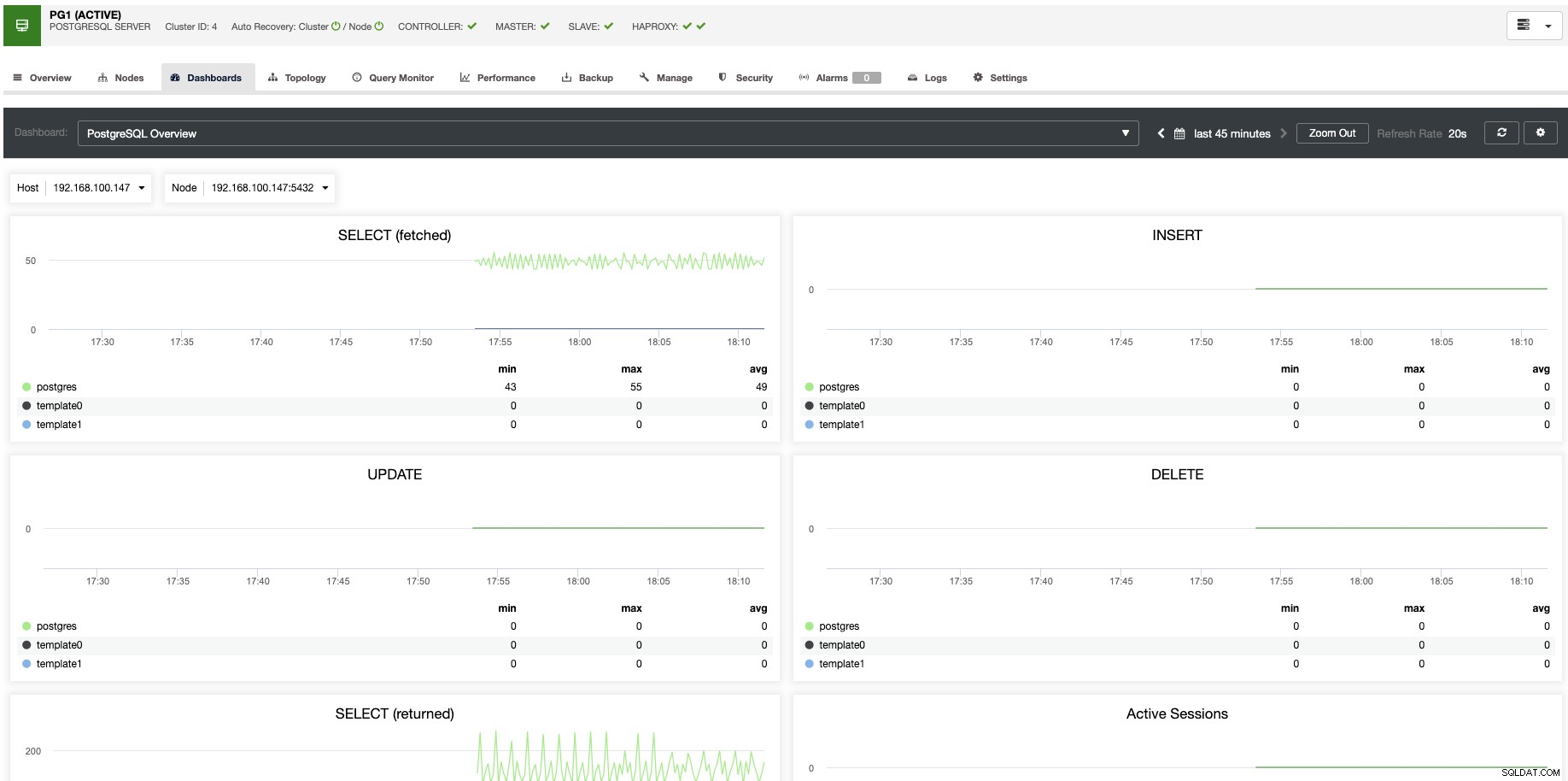
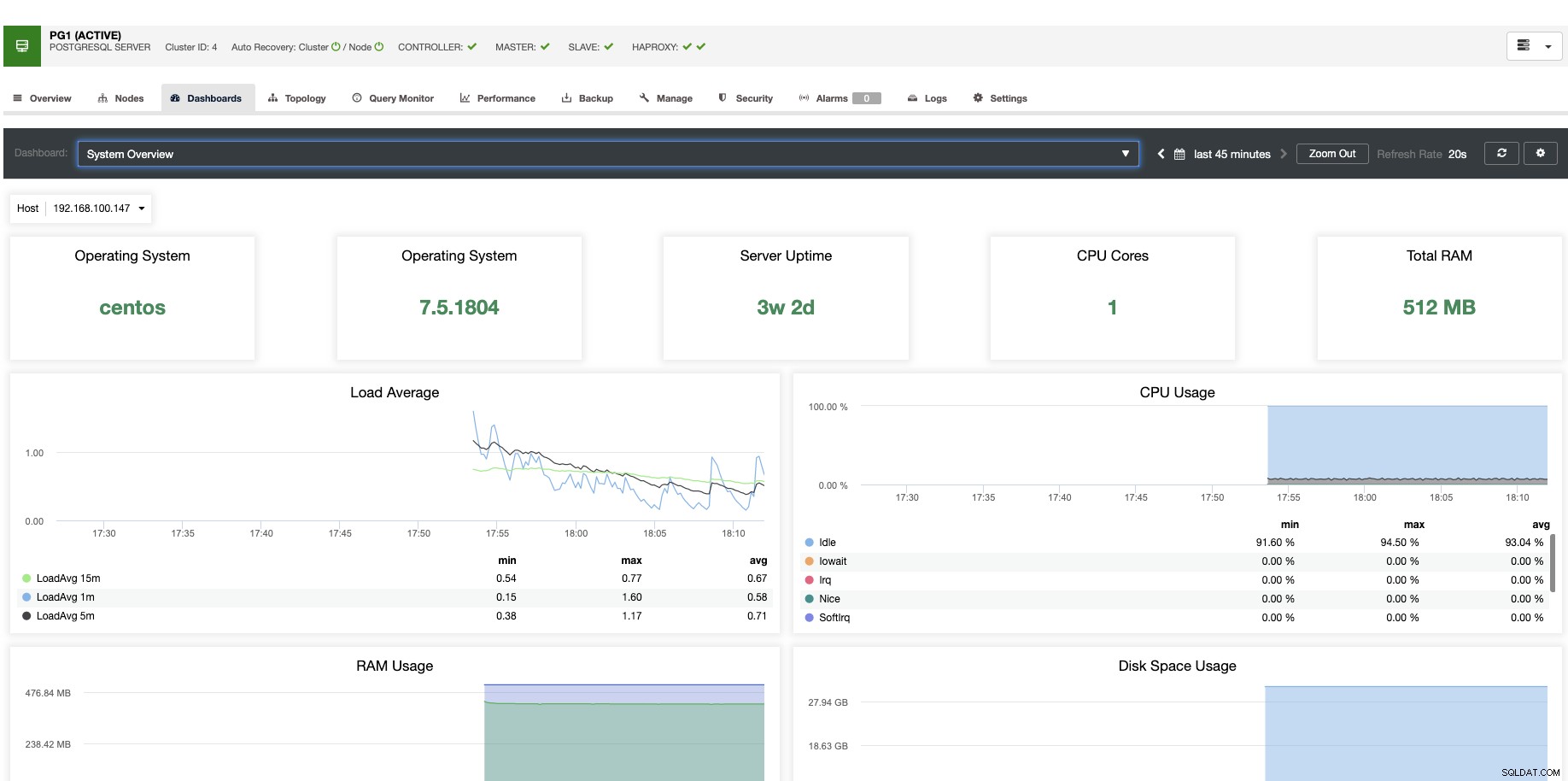
Từ ClusterControl, bạn cũng có thể thực hiện các tác vụ quản lý khác nhau như Khởi động lại máy chủ, Xây dựng lại bản sao Slave hoặc Thúc đẩy Slave, chỉ với một cú nhấp chuột.
Kết luận
Mở rộng quy mô cơ sở dữ liệu PostgreSQL có thể là một công việc tốn thời gian. Chúng ta cần biết những gì chúng ta cần mở rộng quy mô và cách tốt nhất để làm điều đó. Cuối cùng, việc quản lý và mở rộng các cụm theo cách thủ công trở nên khá nặng nề sau một thời điểm nhất định, vì vậy hầu hết chuyển sang các công cụ như của chúng tôi.
Nếu bạn chọn lộ trình thủ công, hãy kiểm tra thời điểm cân nhắc thêm một nút bổ sung vào cụm của bạn. Bạn muốn tránh những rắc rối? Đánh giá ClusterControl miễn phí trong 30 ngày để xem các tính năng của nó làm cho việc xử lý quy mô lớn, mã nguồn mở trở nên đơn giản và hiệu quả như thế nào.
Tuy nhiên, bạn muốn quản lý và mở rộng quy mô cơ sở dữ liệu của mình, hãy theo dõi chúng tôi trên Twitter hoặc LinkedIn hoặc đăng ký nhận bản tin của chúng tôi để nhận tin tức mới nhất và các phương pháp hay nhất khi quản lý cơ sở hạ tầng cơ sở dữ liệu mã nguồn mở và chúng tôi sẽ sớm gặp lại bạn!