Đã có rất nhiều cuộc thảo luận về OLTP trong bộ nhớ (tính năng trước đây được gọi là "Hekaton") và cách nó có thể trợ giúp khối lượng công việc rất cụ thể, khối lượng lớn. Giữa một cuộc trò chuyện khác, tôi tình cờ nhận thấy điều gì đó trong CREATE TYPE tài liệu cho SQL Server 2014 khiến tôi nghĩ rằng có thể có một trường hợp sử dụng chung hơn:

Các bổ sung tương đối yên tĩnh và không được báo trước vào tài liệu TẠO LOẠI
Dựa trên sơ đồ cú pháp, có vẻ như các tham số giá trị bảng (TVP) có thể được tối ưu hóa bộ nhớ, giống như các bảng vĩnh viễn có thể. Và cùng với đó, các bánh xe ngay lập tức bắt đầu quay.
Một điều tôi đã sử dụng TVP là để giúp khách hàng loại bỏ các phương pháp tách chuỗi đắt tiền trong T-SQL hoặc CLR (xem thông tin cơ bản trong các bài viết trước tại đây, tại đây và tại đây). Trong các thử nghiệm của tôi, việc sử dụng TVP thông thường có hiệu suất tốt hơn các mẫu tương đương bằng cách sử dụng các hàm tách CLR hoặc T-SQL với một biên độ đáng kể (25-50%). Tôi tự hỏi một cách hợp lý:Liệu có tăng hiệu suất nào từ TVP được tối ưu hóa bộ nhớ không?
Có một số e ngại về OLTP trong bộ nhớ nói chung, vì có nhiều hạn chế và lỗ hổng tính năng, bạn cần một nhóm tệp riêng cho dữ liệu được tối ưu hóa bộ nhớ, bạn cần di chuyển toàn bộ bảng sang bộ nhớ được tối ưu hóa và lợi ích tốt nhất thường là đạt được bằng cách tạo ra các thủ tục được lưu trữ được biên dịch nguyên bản (có các giới hạn riêng của chúng). Như tôi sẽ trình bày, giả sử loại bảng của bạn chứa cấu trúc dữ liệu đơn giản (ví dụ:đại diện cho một tập hợp các số nguyên hoặc chuỗi), việc sử dụng công nghệ này chỉ dành cho TVP sẽ loại bỏ một số trong số những vấn đề này.
Bài kiểm tra
Bạn sẽ vẫn cần một nhóm tệp được tối ưu hóa bộ nhớ ngay cả khi bạn không tạo các bảng vĩnh viễn, được tối ưu hóa cho bộ nhớ. Vì vậy, hãy tạo một cơ sở dữ liệu mới với cấu trúc thích hợp tại chỗ:
TẠO CƠ SỞ DỮ LIỆU xtp; CƠ SỞ DỮ LIỆU MỤC TIÊU xtp THÊM FILEGROUP xtp CHỨA MEMORY_OPTIMIZED_DATA; MỤC TIÊU CƠ SỞ DỮ LIỆU xtp THÊM TẬP TIN (name ='xtpmod', filename ='c:\ ... \ xtp.mod') ĐỂ FILEGROTER xtp SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT =ON; GO
Bây giờ, chúng ta có thể tạo một loại bảng thông thường, như chúng ta làm ngày nay và một loại bảng được tối ưu hóa bộ nhớ với chỉ số băm không phân cụm và số lượng nhóm mà tôi đã đưa ra (thêm thông tin về cách tính yêu cầu bộ nhớ và số lượng nhóm trong thế giới thực ở đây):
SỬ DỤNG xtp; ĐI TẠO LOẠI dbo.ClassicTVP AS BẢNG (Mục INT PRIMARY KEY); TẠO LOẠI dbo.InMemoryTVP LÀM BẢNG (Mục INT NOT NULL PRIMARY KEY NONCLUSTERED HASH VỚI (BUCKET_COUNT =256)) VỚI (MEMORY_OPTIMIZED =ON);
Nếu bạn thử điều này trong cơ sở dữ liệu không có nhóm tệp được tối ưu hóa bộ nhớ, bạn sẽ nhận được thông báo lỗi này, giống như khi bạn cố gắng tạo một bảng thông thường được tối ưu hóa bộ nhớ:
Msg 41337, Mức 16, Trạng thái 0, Dòng 9Nhóm tệp MEMORY_OPTIMIZED_DATA không tồn tại hoặc trống. Không thể tạo bảng được tối ưu hóa bộ nhớ cho cơ sở dữ liệu cho đến khi cơ sở dữ liệu có một nhóm tệp MEMORY_OPTIMIZED_DATA không trống.
Để kiểm tra một truy vấn so với một bảng thông thường, không được tối ưu hóa bộ nhớ, tôi chỉ cần kéo một số dữ liệu vào một bảng mới từ cơ sở dữ liệu mẫu AdventureWorks2012, sử dụng SELECT INTO để bỏ qua tất cả các ràng buộc, chỉ mục và thuộc tính mở rộng khó chịu đó, sau đó tạo một chỉ mục nhóm trên cột mà tôi biết là tôi sẽ tìm kiếm trên đó (ProductID ):
SELECT * INTO dbo.Products FROM AdventureWorks2012.Production.Product; - 504 hàng TẠO CHỈ SỐ ĐƯỢC ĐIỀU CHỈNH DUY NHẤT p TRÊN dbo.Products (ProductID);
Tiếp theo, tôi tạo bốn thủ tục được lưu trữ:hai thủ tục cho mỗi loại bảng; từng sử dụng EXISTS và JOIN (Tôi thường thích kiểm tra cả hai, mặc dù tôi thích EXISTS; sau này bạn sẽ thấy lý do tại sao tôi không muốn giới hạn thử nghiệm của mình chỉ ở EXISTS ). Trong trường hợp này, tôi chỉ chỉ định một hàng tùy ý cho một biến, để tôi có thể quan sát số lượng thực thi cao mà không phải xử lý các tập kết quả cũng như đầu ra và chi phí khác:
- TVP cũ sử dụng EXISTS:TẠO QUY TRÌNH dbo.ClassicTVP_Exists @Classic dbo.ClassicTVP READONLYASBEGIN ĐẶT SỐ TÀI KHOẢN BẬT; DECLARE @name NVARCHAR (50); SELECT @name =p.Name FROM dbo. Sản phẩm AS p WHERE TỒN TẠI (CHỌN 1 TỪ @Classic AS t WHERE t.Item =p.ProductID); ENDGO - TVP trong bộ nhớ sử dụng EXISTS:TẠO QUY TRÌNH dbo.InMemoryTVP_Exists @InMemory dbo.InMemoryTVP READONLYASBEGIN ĐẶT SỐ TÀI KHOẢN BẬT; DECLARE @name NVARCHAR (50); CHỌN @name =p.Name FROM dbo. Sản phẩm NHƯ p CÓ TỒN TẠI (CHỌN 1 TỪ @InMemory AS t WHERE t.Item =p.ProductID); ENDGO - TVP cũ sử dụng THAM GIA:TẠO QUY TRÌNH dbo.ClassicTVP_Join @ Cổ điển dbo.ClassicTVP READONLYASBEGIN ĐẶT SỐ TÀI KHOẢN; DECLARE @name NVARCHAR (50); SELECT @name =p.Name FROM dbo.Products AS p INNER JOIN @Classic AS t ON t.Item =p.ProductID; ENDGO - In-Memory TVP sử dụng JOIN:CREATE PROCEDURE dbo.InMemoryTVP_Join @InMemory dbo.InMemoryTVP READONLYASBEGIN ĐẶT SỐ TÀI KHOẢN BẬT; DECLARE @name NVARCHAR (50); CHỌN @name =p.Name FROM dbo.Products AS p INNER JOIN @InMemory AS t ON t.Item =p.ProductID; ENDGO
Tiếp theo, tôi cần mô phỏng loại truy vấn thường đi ngược lại với loại bảng này và yêu cầu TVP hoặc mẫu tương tự ngay từ đầu. Hãy tưởng tượng một biểu mẫu có danh sách thả xuống hoặc tập hợp các hộp kiểm chứa danh sách các sản phẩm và người dùng có thể chọn 20 hoặc 50 hoặc 200 mà họ muốn so sánh, liệt kê, bạn có những gì. Các giá trị sẽ không nằm trong một tập hợp liền kề đẹp mắt; chúng thường sẽ nằm rải rác khắp nơi (nếu đó là một phạm vi liền kề có thể dự đoán được, truy vấn sẽ đơn giản hơn nhiều:giá trị bắt đầu và giá trị kết thúc). Vì vậy, tôi chỉ chọn 20 giá trị tùy ý từ bảng (cố gắng ở dưới, chẳng hạn như 5% kích thước bảng), được sắp xếp ngẫu nhiên. Một cách dễ dàng để tạo VALUES có thể tái sử dụng mệnh đề như sau:
DECLARE @x VARCHAR (4000) =''; CHỌN ĐẦU (20) @x + ='(' + RTRIM (ProductID) + '),' TỪ dbo. ĐẶT HÀNG SẢN PHẨM BẰNG NEWID (); CHỌN @x; Kết quả (của bạn gần như chắc chắn sẽ khác nhau):
(725), (524), (357), (405), (477), (821), (323), (526), (952), (473), (442), (450), (735 ), (441), (409), (454), (780), (966), (988), (512),
Không giống như một INSERT...SELECT , điều này giúp bạn khá dễ dàng thao tác đầu ra đó thành một câu lệnh có thể sử dụng lại để điền nhiều lần các TVP của chúng tôi với các giá trị giống nhau và trong suốt nhiều lần lặp lại thử nghiệm:
ĐẶT SỐ TÀI KHOẢN BẬT; KHAI BÁO @ClassicTVP dbo.ClassicTVP; KHAI BÁO @InMemoryTVP dbo.InMemoryTVP; CHÈN @ClassicTVP (Mục) GIÁ TRỊ (725), (524), (357), (405), (477), (821), (323), (526), (952), (473), (442) , (450), (735), (441), (409), (454), (780), (966), (988), (512); CHÈN @InMemoryTVP (Mục) GIÁ TRỊ (725), (524), (357), (405), (477), (821), (323), (526), (952), (473), (442) , (450), (735), (441), (409), (454), (780), (966), (988), (512); EXEC dbo.ClassicTVP_Exists @Classic =@ClassicTVP; EXEC dbo.InMemoryTVP_Exists @InMemory =@InMemoryTVP; EXEC dbo.ClassicTVP_Join @Classic =@ClassicTVP; EXEC dbo.InMemoryTVP_Join @ trongNếu chúng tôi chạy lô này bằng cách sử dụng SQL Sentry Plan Explorer, các kế hoạch kết quả cho thấy một sự khác biệt lớn:TVP trong bộ nhớ có thể sử dụng tham gia vòng lặp lồng nhau và tìm kiếm chỉ mục nhóm 20 hàng đơn, so với tham gia hợp nhất được cung cấp 502 hàng bằng quét chỉ mục theo nhóm cho TVP cổ điển. Và trong trường hợp này, EXISTS và JOIN mang lại các kế hoạch giống hệt nhau. Điều này có thể mẹo với số lượng giá trị cao hơn nhiều, nhưng hãy tiếp tục với giả định rằng số lượng giá trị sẽ nhỏ hơn 5% kích thước bảng:
Các gói TVP cổ điển và trong bộ nhớ
Chú giải công cụ cho toán tử quét / tìm kiếm, nêu bật những điểm khác biệt chính - Cổ điển ở bên trái, Trong- Bộ nhớ ở bên phải
Bây giờ điều này có nghĩa là gì trên quy mô? Hãy tắt bất kỳ bộ sưu tập chương trình nào và thay đổi một chút tập lệnh thử nghiệm để chạy mỗi quy trình 100.000 lần, ghi lại thời gian chạy tích lũy theo cách thủ công:
DECLARE @i TINYINT =1, @j INT =1; WHILE @i <=4BEGIN CHỌN SYSDATETIME (); WHILE @j <=100000 BẮT ĐẦU NẾU @i =1 BẮT ĐẦU THỰC HIỆN dbo.ClassicTVP_Exists @Classic =@ClassicTVP; KẾT THÚC NẾU @i =2 BẮT ĐẦU THỰC HIỆN dbo.InMemoryTVP_Exists @InMemory =@InMemoryTVP; HẾT NẾU @i =3 BẮT ĐẦU THỰC HIỆN dbo.ClassicTVP_Join @Classic =@ClassicTVP; KẾT THÚC NẾU @i =4 BẮT ĐẦU THỰC HIỆN dbo.InMemoryTVP_Join @InMemory =@InMemoryTVP; KẾT THÚC ĐẶT @j + =1; KẾT THÚC CHỌN @i + =1, @j =1; KẾT THÚC CHỌN SYSDATETIME ();Trong kết quả, tính trung bình trên 10 lần chạy, chúng tôi thấy rằng, ít nhất trong trường hợp thử nghiệm giới hạn này, việc sử dụng loại bảng được tối ưu hóa bộ nhớ mang lại sự cải thiện gần gấp 3 lần đối với chỉ số hiệu suất được cho là quan trọng nhất trong OLTP (thời lượng chạy):
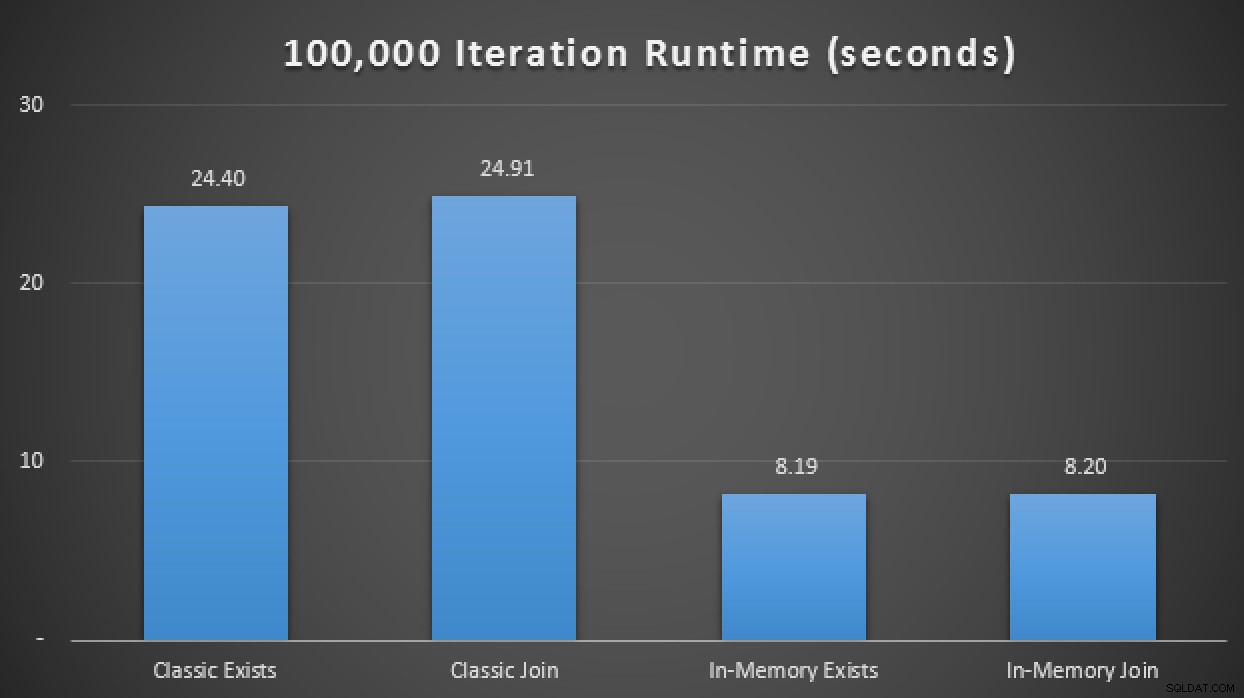
Kết quả thời gian chạy cho thấy sự cải thiện gấp 3 lần với TVP trong bộ nhớTrong bộ nhớ + Bộ nhớ trong + Bộ nhớ trong:Khởi động trong bộ nhớ
Bây giờ chúng ta đã thấy những gì chúng ta có thể làm bằng cách chỉ cần thay đổi loại bảng thông thường của chúng ta thành một loại bảng được tối ưu hóa bộ nhớ, hãy xem liệu chúng ta có thể tăng thêm bất kỳ hiệu suất nào từ cùng một mẫu truy vấn này khi chúng ta áp dụng bộ ba:một trong bộ nhớ bảng, sử dụng thủ tục lưu trữ tối ưu hóa bộ nhớ được biên dịch nguyên bản, chấp nhận một bảng bảng trong bộ nhớ dưới dạng tham số có giá trị bảng.
Đầu tiên, chúng ta cần tạo một bản sao mới của bảng và điền nó từ bảng cục bộ mà chúng ta đã tạo:
CREATE TABLE dbo.Products_InMemory (ProductID INT NOT NULL, Name NVARCHAR (50) NOT NULL, ProductNumber NVARCHAR (25) NOT NULL, MakeFlag BIT NOT NULL, FireadyGoodsFlag BIT NULL, Color NVARCHAR (15) NULL, SafetyStockLevel SMALLIN NULL , ReorderPoint SMALLINT NOT NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Size] NVARCHAR (5) NULL, SizeUnitMeasureCode NCHAR (3) NULL, WeightUnitMeasureCode NCHAR (3) NULL, [Weight] DECIMAL (8, 2) NULL, DaysToMan production INT NOT NULL, ProductLine NCHAR (2) NULL, [Class] NCHAR (2) NULL, Style NCHAR (2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, Se llStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMARY KEY NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT =256) CHÈN dbo.Products_InMemory CHỌN * TỪ dbo.Products;Tiếp theo, chúng tôi tạo một thủ tục được lưu trữ được biên dịch nguyên bản lấy loại bảng được tối ưu hóa bộ nhớ hiện có của chúng tôi làm TVP:
TẠO THỦ TỤC dbo.InMemoryProcedure @InMemory dbo.InMemoryTVP READONLYWITH NATIVE_COMPILATION, SCHEMABINDING, THỰC HIỆN NHƯ CHỦ SỞ HỮU NHƯ BẮT ĐẦU VỚI (CẤP ĐỘ GIAO DỊCH =SNAPSHOT, LANGUAGE =N'us_english '); DECLARE @Name NVARCHAR (50); SELECT @Name =Name FROM dbo.Products_InMemory AS p INNER JOIN @InMemory AS t ON t.Item =p.ProductID; END GOMột vài lưu ý. Chúng tôi không thể sử dụng loại bảng thông thường, không được tối ưu hóa bộ nhớ làm tham số cho một thủ tục được lưu trữ được biên dịch nguyên bản. Nếu chúng tôi cố gắng, chúng tôi nhận được:
Msg 41323, Mức 16, Trạng thái 1, Thủ tục InMemoryProcedure
Loại bảng 'dbo.ClassicTVP' không phải là loại bảng được tối ưu hóa bộ nhớ và không thể được sử dụng trong quy trình được lưu trữ được biên dịch nguyên bản.Ngoài ra, chúng tôi không thể sử dụng
Msg 12311, Cấp 16, Trạng thái 37, Thủ tục NativeCompiled_ExistsEXISTSở đây cũng có; khi chúng tôi cố gắng, chúng tôi nhận được:
Truy vấn con (truy vấn lồng trong một truy vấn khác) không được hỗ trợ với các thủ tục được lưu trữ được biên dịch nguyên bản.Có nhiều cảnh báo và hạn chế khác với OLTP trong bộ nhớ và các thủ tục được lưu trữ được biên dịch nguyên bản, tôi chỉ muốn chia sẻ một số điều có thể rõ ràng là còn thiếu trong quá trình thử nghiệm.
Vì vậy, thêm thủ tục lưu trữ được biên dịch tự nhiên mới này vào ma trận kiểm tra ở trên, tôi thấy rằng - một lần nữa, trung bình hơn 10 lần chạy - nó thực hiện 100.000 lần lặp chỉ trong 1,25 giây. Điều này thể hiện sự cải thiện gần 20 lần so với TVP thông thường và cải tiến gấp 6-7 lần so với TVP trong bộ nhớ sử dụng các bảng và quy trình truyền thống:
Kết quả thời gian chạy hiển thị cải thiện tới 20 lần với tính năng Trong bộ nhớKết luận
Nếu bây giờ bạn đang sử dụng TVP hoặc bạn đang sử dụng các mẫu có thể được thay thế bằng TVP, bạn hoàn toàn phải cân nhắc việc thêm TVP được tối ưu hóa bộ nhớ vào kế hoạch thử nghiệm của mình, nhưng hãy nhớ rằng bạn có thể không thấy những cải tiến tương tự trong kịch bản của mình. (Và, tất nhiên, hãy nhớ rằng TVP nói chung có rất nhiều cảnh báo và hạn chế, và chúng cũng không phù hợp với mọi tình huống. Erland Sommarskog có một bài viết rất hay về TVP ngày nay tại đây.)
Trên thực tế, bạn có thể thấy rằng ở mức thấp nhất của khối lượng và đồng thời, không có sự khác biệt - nhưng hãy kiểm tra ở quy mô thực tế. Đây là một bài kiểm tra rất đơn giản và phức tạp trên một máy tính xách tay hiện đại với một ổ SSD duy nhất, nhưng khi bạn đang nói về khối lượng thực và / hoặc các đĩa cơ quay, các đặc điểm hiệu suất này có thể có trọng lượng hơn nhiều. Sẽ có phần tiếp theo với một số minh chứng về kích thước dữ liệu lớn hơn.