IGNORE_DUP_KEY tùy chọn cho các chỉ mục duy nhất chỉ định cách Máy chủ SQL phản hồi nỗ lực INSERT các giá trị trùng lặp:Nó chỉ áp dụng cho bảng (không phải dạng xem) và chỉ cho phần chèn. Bất kỳ phần chèn nào của MERGE câu lệnh bỏ qua bất kỳ IGNORE_DUP_KEY nào cài đặt chỉ mục.
Khi IGNORE_DUP_KEY OFF , bản sao đầu tiên gặp phải dẫn đến lỗi và không có hàng mới nào được chèn.
Khi IGNORE_DUP_KEY ON , các hàng đã chèn vi phạm tính duy nhất sẽ bị loại bỏ. Các hàng còn lại được chèn thành công. Một cảnh báo thông báo được phát ra thay vì lỗi:
Tóm tắt Bài viết
IGNORE_DUP_KEY tùy chọn chỉ mục có thể được chỉ định cho cả chỉ mục duy nhất được phân nhóm và không phân nhóm. Sử dụng nó trên một chỉ mục được phân nhóm có thể dẫn đến hiệu suất kém hơn nhiều so với chỉ mục duy nhất không phân biệt.
Quy mô của sự khác biệt về hiệu suất phụ thuộc vào số lượng vi phạm về tính duy nhất gặp phải trong quá trình INSERT hoạt động. Càng nhiều vi phạm, chỉ số duy nhất được nhóm lại càng hoạt động kém hơn khi so sánh. Nếu không có vi phạm nào, chèn chỉ mục theo nhóm thậm chí có thể hoạt động tốt hơn.
Chèn chỉ mục duy nhất theo nhóm
Đối với chỉ mục duy nhất được nhóm với IGNORE_DUP_KEY , các bản sao được xử lý bởi công cụ lưu trữ .
Phần lớn công việc liên quan đến việc chèn mỗi hàng được thực hiện trước khi bản sao được phát hiện. Ví dụ:một Chèn chỉ mục theo cụm toán tử điều hướng xuống cây b-chỉ mục được phân cụm đến điểm mà hàng mới sẽ đến, lấy chốt trang và hệ thống phân cấp thông thường của khóa, trước khi nó phát hiện ra khóa trùng lặp.
Khi điều kiện khóa trùng lặp được phát hiện, một lỗi được nuôi dưỡng. Thay vì hủy thực thi và trả lại lỗi cho máy khách, lỗi được xử lý nội bộ. Hàng có vấn đề không được chèn và quá trình thực thi vẫn tiếp tục, tìm kiếm hàng tiếp theo để chèn. Nếu hàng đó gặp một khóa trùng lặp, một lỗi khác sẽ xuất hiện và xử lý, v.v.
Các trường hợp ngoại lệ là rất tốn kém để ném và bắt. Một số lượng lớn các bản sao sẽ làm chậm quá trình thực thi một cách đáng kể.
Chèn chỉ mục duy nhất không phân biệt
Đối với chỉ mục duy nhất không phân biệt với IGNORE_DUP_KEY bộ, các bản sao được xử lý bởi bộ xử lý truy vấn . Các bản sao được phát hiện và một cảnh báo được phát ra, trước khi mỗi lần chèn được thử.
Bộ xử lý truy vấn loại bỏ các bản sao khỏi luồng chèn, đảm bảo rằng không có bản sao nào được công cụ lưu trữ nhìn thấy. Do đó, không có lỗi vi phạm chính duy nhất nào được phát sinh hoặc xử lý nội bộ.
Sự đánh đổi
Có sự đánh đổi giữa chi phí phát hiện và loại bỏ các khóa trùng lặp trong kế hoạch thực thi, so với chi phí thực hiện các công việc quan trọng liên quan đến chèn và ném và bắt lỗi khi tìm thấy một bản sao.
Nếu các bản sao được mong đợi là rất hiếm , giải pháp công cụ lưu trữ (chỉ mục theo cụm) có thể hiệu quả hơn. Khi các bản sao ít hiếm hơn, cách tiếp cận của bộ xử lý truy vấn có thể sẽ trả cổ tức. Điểm giao nhau chính xác sẽ phụ thuộc vào các yếu tố như hiệu quả thời gian chạy của các thành phần kế hoạch thực thi được sử dụng để phát hiện và loại bỏ các bản sao.
Phần còn lại của bài viết này cung cấp một bản trình diễn và xem xét chi tiết hơn tại sao cách tiếp cận công cụ lưu trữ có thể hoạt động kém như vậy.
Demo
Tập lệnh sau tạo một bảng tạm thời với một triệu hàng. Nó có 1.000 giá trị duy nhất và 1.000 hàng cho mỗi giá trị duy nhất. Tập dữ liệu này sẽ được sử dụng làm nguồn dữ liệu để chèn vào các bảng có cấu hình chỉ mục khác nhau.
DROP TABLE IF EXISTS #Data;
GO
CREATE TABLE #Data (c1 integer NOT NULL);
GO
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE
@Loop integer = 1,
@N integer = 1;
WHILE @N <= 1000
BEGIN
SET @Loop = 1;
BEGIN TRANSACTION;
-- Add 1,000 copies of the current loop value
WHILE @Loop <= 50
BEGIN
INSERT #Data
(c1)
VALUES
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N);
SET @Loop += 1;
END;
COMMIT TRANSACTION;
SET @N += 1;
END;
CREATE CLUSTERED INDEX cx
ON #Data (c1)
WITH (MAXDOP = 1); Đường cơ sở
Việc chèn sau vào một biến bảng có chỉ mục được phân nhóm không phải là duy nhất mất khoảng 900 mili giây :
DECLARE @T table
(
c1 integer NOT NULL
INDEX cuq CLUSTERED (c1)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D;
Lưu ý thiếu IGNORE_DUP_KEY trên biến bảng mục tiêu.
Chỉ mục duy nhất được nhóm
Chèn cùng một dữ liệu vào một nhóm duy nhất lập chỉ mục với IGNORE_DUP_KEY đặt ON mất khoảng 15,900 mili giây - tệ hơn gần 18 lần:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Chỉ mục duy nhất không phân biệt
Chèn dữ liệu vào một không bao gồm duy nhất lập chỉ mục với IGNORE_DUP_KEY đặt ON mất khoảng 700 mili giây :
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE NONCLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Tóm tắt hiệu suất
Thử nghiệm cơ bản mất 900 mili giây để chèn tất cả một triệu hàng. Kiểm tra chỉ mục không phân biệt mất 700 mili giây chỉ để chèn 1.000 khóa riêng biệt. Kiểm tra chỉ mục theo nhóm mất 15,900ms để chèn cùng 1.000 hàng duy nhất.
Thử nghiệm này được cố tình thiết lập để làm nổi bật hiệu suất kém của việc triển khai công cụ lưu trữ, bằng cách tạo ra 999 đơn vị công việc bị lãng phí (chốt, khóa, xử lý lỗi) cho mỗi hàng thành công.
Thông điệp dự định không phải là IGNORE_DUP_KEY sẽ luôn hoạt động kém trên các chỉ mục được phân nhóm, chỉ là điều đó có thể xảy ra và có thể có sự khác biệt lớn giữa các chỉ mục được phân nhóm và không được phân nhóm.
Kế hoạch thực thi chỉ mục theo cụm
Không có số lượng lớn để xem trong kế hoạch chèn chỉ mục theo nhóm:
Có 1.000.000 hàng được chuyển đến Chèn chỉ mục theo cụm toán tử, được hiển thị dưới dạng 'trả về' 1.000 hàng. Đi sâu vào chi tiết kế hoạch, chúng ta có thể thấy:
- 1.244.008 lần đọc logic tại toán tử chèn.
- Phần lớn thời gian thực hiện được dành cho Chèn toán tử.
- 11ms của
SOS_SCHEDULER_YIELDđang đợi (tức là không có sự chờ đợi nào khác).
Không có gì thực sự giải thích được 15,900 mili giây trong tổng thời gian đã trôi qua.
Tại sao hiệu suất quá kém
Rõ ràng là kế hoạch này sẽ phải làm rất nhiều việc cho từng hàng:
- Điều hướng các cấp b-cây của chỉ mục được phân nhóm, chốt và khóa khi nó hoạt động, để tìm điểm chèn cho bản ghi mới.
- Nếu bất kỳ trang chỉ mục nào cần thiết không có trong bộ nhớ, chúng sẽ cần được tìm nạp từ đĩa.
- Tạo một hàng b-tree mới trong bộ nhớ.
- Chuẩn bị hồ sơ nhật ký.
- Nếu tìm thấy bản sao khóa (đó không phải là bản ghi ma), hãy nêu lỗi, xử lý lỗi đó trong nội bộ, giải phóng hàng hiện tại và tiếp tục tại một điểm thích hợp trong mã để xử lý hàng ứng viên tiếp theo.
Đó là một khối lượng công việc hợp lý và hãy nhớ rằng tất cả đều xảy ra cho mỗi hàng .
Phần mà tôi muốn tập trung là việc phát hiện và xử lý lỗi, vì nó cực kỳ đắt tiền. Các khía cạnh còn lại được lưu ý ở trên đã được thực hiện rẻ nhất có thể bằng cách sử dụng biến bảng và bảng tạm thời trong bản demo.
Ngoại lệ
Điều đầu tiên tôi muốn làm là hiển thị rằng Chèn chỉ mục theo cụm toán tử thực sự đưa ra một ngoại lệ khi nó gặp một khóa trùng lặp.
Một cách để hiển thị điều này trực tiếp là bằng cách đính kèm trình gỡ lỗi và ghi lại dấu vết ngăn xếp tại điểm ngoại lệ được ném ra:
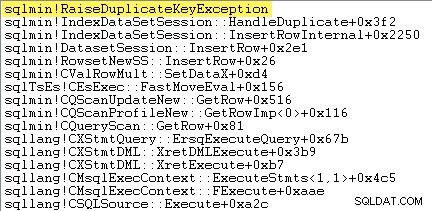
Điểm quan trọng ở đây là việc ném và bắt các trường hợp ngoại lệ rất tốn kém.
Giám sát SQL Server bằng Windows Performance Recorder trong khi chạy thử nghiệm và phân tích kết quả trong Windows Performance Analyzer cho thấy:
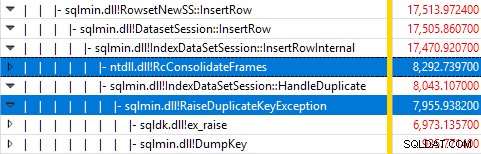
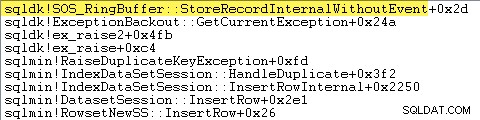
Hầu như tất cả thời gian thực thi truy vấn được dành cho sqlmin!IndexDataSetSession::InsertRowInternal như mong đợi đối với một truy vấn thực hiện một số việc khác ngoại trừ việc chèn hàng.
Điều ngạc nhiên là 45% thời gian đó được dành để nâng cao các ngoại lệ thông qua sqlmin!RaiseDuplicateKeyException và 47% khác được sử dụng trong khối bắt ngoại lệ được liên kết (ntdll!RcConsolidateFrames phân cấp).
Tóm lại:Việc nâng và bắt các trường hợp ngoại lệ chiếm 92% thời gian thực hiện của truy vấn chèn chỉ mục được phân cụm thử nghiệm của chúng tôi.
Các vấn đề về thu thập dữ liệu
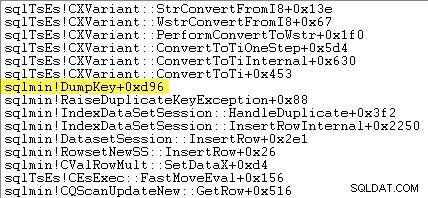
Những độc giả tinh mắt có thể nhận thấy một lượng đáng kể - khoảng 12% - thời gian tăng ngoại lệ dành cho sqlmin!DumpKey trong đồ họa của Windows Performance Analyzer. Điều này đáng để khám phá nhanh chóng, cùng với một số mục liên quan.
Là một phần của việc nâng cao ngoại lệ, SQL Server phải thu thập một số dữ liệu chỉ có sẵn tại thời điểm xảy ra lỗi. Số lỗi liên quan đến ngoại lệ khóa trùng lặp là 2627. Nội dung thông báo trong sys.messages cho số lỗi đó là:
Thông tin để điền các điểm đánh dấu địa điểm đó cần được thu thập tại thời điểm lỗi được phát sinh - thông tin này sẽ không khả dụng sau này! Điều đó có nghĩa là tra cứu và định dạng kiểu ràng buộc, tên của nó, tên đầy đủ của đối tượng đích và giá trị khóa cụ thể. Tất cả điều đó cần có thời gian.
Dấu vết ngăn xếp sau đây cho thấy máy chủ định dạng giá trị khóa trùng lặp dưới dạng chuỗi Unicode trong DumpKey gọi:
Xử lý ngoại lệ cũng liên quan đến việc ghi lại dấu vết ngăn xếp:
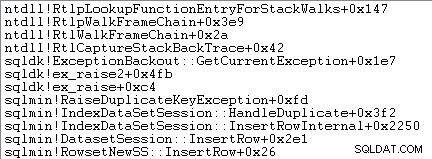
SQL Server cũng ghi lại thông tin về các ngoại lệ (bao gồm cả các khung ngăn xếp) trong một bộ đệm vòng nhỏ, như sau cho thấy:
Bạn có thể xem các mục nhập bộ đệm chuông đó bằng cách sử dụng lệnh như:
SELECT TOP (10)
date_time =
DATEADD
(
MILLISECOND,
DORB.[timestamp] - DOSI.ms_ticks,
SYSDATETIME()
),
record = CONVERT(xml, DORB.record)
FROM sys.dm_os_ring_buffers AS DORB
CROSS JOIN sys.dm_os_sys_info AS DOSI
WHERE
DORB.ring_buffer_type = N'RING_BUFFER_EXCEPTION'
ORDER BY
DORB.[timestamp] DESC; Sau đây là một ví dụ về bản ghi xml cho một ngoại lệ khóa trùng lặp. Lưu ý các khung ngăn xếp:
<Record id="4611442" type="RING_BUFFER_EXCEPTION" time="93079430">
<Exception>
<Task address="0x00000245B5E1FC28" />
<Error>2627</Error>
<Severity>14</Severity>
<State>1</State>
<UserDefined>0</UserDefined>
<Origin>0</Origin>
</Exception>
<Stack>
<frame id="0">0X00007FFAC659E80A</frame>
<frame id="1">0X00007FFACBAC0EFD</frame>
<frame id="2">0X00007FFACBAA1252</frame>
<frame id="3">0X00007FFACBA9E040</frame>
<frame id="4">0X00007FFACAB55D53</frame>
<frame id="5">0X00007FFACAB55C06</frame>
<frame id="6">0X00007FFACB3E3D0B</frame>
<frame id="7">0X00007FFAC92020EC</frame>
<frame id="8">0X00007FFACAB5B2FA</frame>
<frame id="9">0X00007FFACABA3B9B</frame>
<frame id="10">0X00007FFACAB3D89F</frame>
<frame id="11">0X00007FFAC6A9D108</frame>
<frame id="12">0X00007FFAC6AB2BBF</frame>
<frame id="13">0X00007FFAC6AB296F</frame>
<frame id="14">0X00007FFAC6A9B7D0</frame>
<frame id="15">0X00007FFAC6A9B233</frame>
</Stack>
</Record> Tất cả công việc nền này xảy ra cho mọi ngoại lệ. Trong thử nghiệm của chúng tôi, điều đó có nghĩa là nó xảy ra 999.000 lần - một lần cho mỗi hàng gặp lỗi vi phạm khóa trùng lặp.
Có nhiều cách để xem điều này, ví dụ:bằng cách chạy theo dõi Hồ sơ bằng cách sử dụng Ngoại lệ sự kiện trong Lỗi và Cảnh báo lớp. Trong trường hợp thử nghiệm của chúng tôi, điều này sẽ cuối cùng tạo ra 999.000 hàng với Dữ liệu văn bản các phần tử như thế này:
Vi phạm ràng buộc KHÓA DUY NHẤT 'UQ __ # AC166DE__3213663B8B6E2E0E'Không thể chèn khóa trùng lặp trong đối tượng 'dbo. @ T'.
Giá trị khóa trùng lặp là (173).
Đính kèm Hồ sơ có nghĩa là mỗi sự kiện xử lý ngoại lệ thu được rất nhiều chi phí bổ sung, vì dữ liệu bổ sung cần thiết được thu thập và định dạng. Dữ liệu mặc định được đề cập trước đây luôn được thu thập, ngay cả khi không có ai tích cực sử dụng thông tin.
Nói rõ hơn:Các con số hiệu suất được báo cáo trong bài viết này đều được thu thập mà không có trình gỡ lỗi đính kèm và không có hoạt động giám sát nào khác.
Kế hoạch thực thi chỉ mục không bao gồm
Mặc dù nhanh hơn rất nhiều, nhưng kế hoạch chèn chỉ mục không phân bổ khá phức tạp hơn một chút, vì vậy tôi sẽ chia nó thành hai phần.
Chủ đề chung là kế hoạch này nhanh hơn vì nó loại bỏ các bản sao trước cố gắng chèn chúng vào bảng mục tiêu.
Phần 1
Đầu tiên, phía bên phải của kế hoạch chỉ mục không phân biệt:
Phần này của kế hoạch từ chối bất kỳ hàng nào có khớp chính trong bảng mục tiêu cho chỉ mục duy nhất với IGNORE_DUP_KEY đặt ON .
Bạn có thể mong đợi thấy một Tham gia chống bán người bán ở đây, nhưng SQL Server không có cơ sở hạ tầng cần thiết để đưa ra cảnh báo khóa trùng lặp được yêu cầu với Anti Semi Join nhà điều hành. (Nếu điều đó vẫn chưa có ý nghĩa, nó sẽ sớm xảy ra.)
Thay vào đó, chúng tôi nhận được một kế hoạch với một số tính năng thú vị:
- Quét chỉ mục theo cụm là
Ordered:Trueđể cung cấp đầu vào cho Kết hợp bán phần bên trái hợp nhất được sắp xếp theo cộtc1trong#Databảng. - Quét chỉ mục của biến bảng là
Ordered:False - Sắp xếp sắp xếp các hàng theo cột
c1trong biến bảng. Đơn đặt hàng này có thể được cung cấp bởi một đơn đặt hàng quét chỉ mục biến bảng trênc1, nhưng trình tối ưu hóa quyết định Sắp xếp là cách rẻ nhất để cung cấp mức độ Bảo vệ Halloween cần thiết. - Biến bảng Quét chỉ mục có
UPDLOCKnội bộ vàSERIALIZABLEcác gợi ý được áp dụng để đảm bảo mục tiêu ổn định trong quá trình thực hiện kế hoạch. - Kết hợp bán phần bên trái hợp nhất kiểm tra các kết quả phù hợp trong biến bảng cho từng giá trị của
c1được trả về từ#Databàn. Không giống như phép nối bán thông thường, nó phát ra mọi hàng nhận được ở đầu vào phía trên của nó. Nó đặt cờ trong cột thăm dò để cho biết hàng hiện tại có tìm thấy hàng trùng khớp hay không. Cột thăm dò được phát ra từ Kết hợp bán phần bên trái hợp nhất dưới dạng một biểu thức có tênExpr1012. - Khẳng định toán tử kiểm tra giá trị của cột thăm dò
Expr1012. Lần đầu tiên nó nhìn thấy một hàng có giá trị cột thăm dò không phải null (cho biết rằng một khóa chỉ mục đã được tìm thấy), nó sẽ phát ra một “Khóa trùng lặp đã bị bỏ qua” tin nhắn. - Khẳng định chỉ truyền trên các hàng có cột thăm dò là rỗng. Điều này giúp loại bỏ các hàng đến sẽ tạo ra lỗi khóa trùng lặp.
Tất cả điều đó có vẻ phức tạp, nhưng về cơ bản nó đơn giản như đặt cờ nếu tìm thấy kết quả phù hợp, phát ra cảnh báo khi cờ được đặt lần đầu tiên và chỉ chuyển các hàng về phía chèn chưa tồn tại trong bảng đích .
Phần 2
Phần thứ hai của kế hoạch theo sau Khẳng định nhà điều hành:
Phần trước của kế hoạch đã loại bỏ các hàng trùng khớp trong bảng mục tiêu. Phần này của kế hoạch loại bỏ các bản sao trong bộ chèn .
Ví dụ:hãy tưởng tượng không có hàng nào trong bảng đích mà c1 = 1 . Chúng tôi vẫn có thể gây ra lỗi khóa trùng lặp nếu chúng tôi cố gắng chèn hai hàng bằng c1 = 1 từ bảng nguồn. Chúng ta cần tránh điều đó để tôn trọng ngữ nghĩa của IGNORE_DUP_KEY = ON .
Khía cạnh này do Phân đoạn xử lý và Trên cùng toán tử.
Phân đoạn toán tử đặt một cờ mới (có nhãn Segment1015 ) khi nó gặp một hàng có giá trị mới cho c1 . Vì các hàng được trình bày trong c1 đơn đặt hàng (nhờ Hợp nhất bảo toàn đơn hàng ), kế hoạch có thể dựa trên tất cả các hàng có cùng c1 giá trị đến một luồng liền kề.
Trên cùng toán tử chuyển trên một hàng cho mỗi nhóm trùng lặp, như được chỉ ra bởi Phân đoạn lá cờ. Nếu Trên cùng toán tử gặp nhiều hơn một hàng cho cùng một Phân đoạn nhóm (c1 value), nó phát ra “Khóa trùng lặp đã bị bỏ qua” cảnh báo, nếu đó là lần đầu tiên kế hoạch gặp phải tình trạng đó.
Kết quả thực sự của tất cả những điều này là chỉ một hàng được chuyển đến các toán tử chèn cho mỗi giá trị duy nhất của c1 và một cảnh báo sẽ được tạo nếu cần.
Kế hoạch thực thi hiện đã loại bỏ tất cả các vi phạm chính có khả năng trùng lặp, vì vậy phần Chèn bảng còn lại và Chèn chỉ mục toán tử có thể chèn các hàng vào chỉ mục heap và nonclustered một cách an toàn mà không sợ lỗi khóa trùng lặp.
Hãy nhớ rằng UPDLOCK và SERIALIZABLE các gợi ý được áp dụng cho bảng đích đảm bảo rằng tập hợp không thể thay đổi trong quá trình thực thi. Nói cách khác, một câu lệnh đồng thời không thể thay đổi bảng mục tiêu, do đó lỗi khóa trùng lặp sẽ xảy ra tại Chèn các toán tử. Đó không phải là mối quan tâm ở đây vì chúng tôi đang sử dụng một biến bảng riêng, nhưng SQL Server vẫn thêm các gợi ý như một biện pháp an toàn chung.
Nếu không có những gợi ý đó, một quy trình đồng thời có thể thêm một hàng vào bảng mục tiêu sẽ tạo ra vi phạm khóa trùng lặp, bất chấp các kiểm tra được thực hiện bởi phần 1 của kế hoạch. SQL Server cần đảm bảo rằng kết quả kiểm tra sự tồn tại vẫn hợp lệ.
Người đọc tò mò có thể thấy một số tính năng được mô tả ở trên bằng cách bật cờ theo dõi 3604 và 8607 để xem cây đầu ra của trình tối ưu hóa:
PhyOp_RestrRemap
PhyOp_StreamUpdate(INS TBL: @T, iid 0x2 as IDX, Sort(QCOL: .c1, )), {
- COL: Bmk10001013 = COL: Bmk1000
- COL: c11014 = QCOL: .c1}
PhyOp_StreamUpdate(INS TBL: @T, iid 0x0 as TBLInsLocator(COL: Bmk1000 ) REPORT-COUNT), {
- QCOL: .c1= QCOL: [D].c1}
PhyOp_GbTop Group(QCOL: [D].c1,) WARN-DUP
PhyOp_StreamCheck (WarnIgnoreDuplicate TABLE)
PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL: Expr1012 ( QCOL: [D].c1) = ( QCOL: .c1)
PhyOp_Range TBL: #Data(alias TBL: D)(1) ASC
PhyOp_Sort +s -d QCOL: .c1
PhyOp_Range TBL: @T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX )
ScaOp_Comp x_cmpIs
ScaOp_Identifier QCOL: [D].c1
ScaOp_Identifier QCOL: .c1
ScaOp_Logical x_lopIsNotNull
ScaOp_Identifier COL: Expr1012
Kết luận
IGNORE_DUP_KEY tùy chọn chỉ mục không phải là thứ mà hầu hết mọi người sẽ sử dụng rất thường xuyên. Tuy nhiên, thật thú vị khi xem cách chức năng này được triển khai và tại sao có thể có sự khác biệt lớn về hiệu suất giữa IGNORE_DUP_KEY trên các chỉ mục được phân nhóm và không phân nhóm.
Trong nhiều trường hợp, bạn sẽ phải trả tiền để tuân theo sự dẫn dắt của bộ xử lý truy vấn và tìm cách viết các truy vấn loại bỏ các bản sao một cách rõ ràng, thay vì dựa vào IGNORE_DUP_KEY . Trong ví dụ của chúng tôi, điều đó có nghĩa là viết:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED -- no IGNORE_DUP_KEY!
);
INSERT @T
(c1)
SELECT DISTINCT -- Remove duplicates
D.c1
FROM #Data AS D; Quá trình này thực thi trong khoảng 400 mili giây , chỉ để ghi lại.