Gần đây tôi đã có rất nhiều cuộc trò chuyện về các loại khối lượng công việc - cụ thể là hiểu khối lượng công việc được tham số hóa, adhoc hay hỗn hợp. Đó là một trong những điều chúng tôi xem xét trong quá trình kiểm tra sức khỏe và Kimberly có một truy vấn tuyệt vời từ bộ nhớ cache trong Kế hoạch của cô ấy và tối ưu hóa cho khối lượng công việc adhoc bài đăng đó là một phần trong bộ công cụ của chúng tôi. Tôi đã sao chép truy vấn bên dưới.
SELECT objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC; Nếu tôi chạy truy vấn này với môi trường sản xuất, chúng tôi có thể nhận được kết quả như sau:
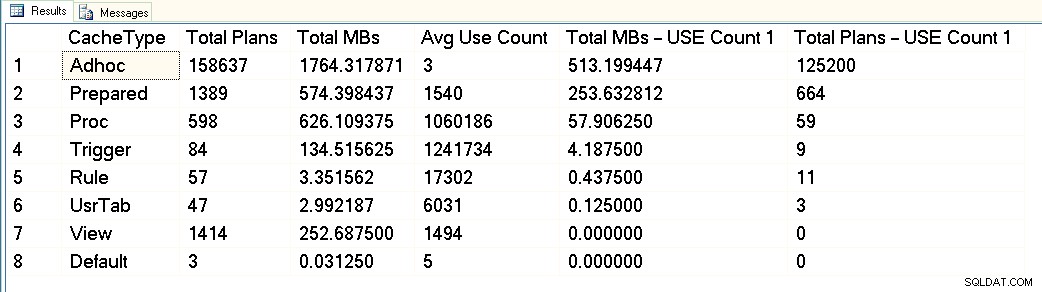
Từ ảnh chụp màn hình này, bạn có thể thấy rằng chúng tôi có tổng cộng khoảng 3GB dành riêng cho bộ nhớ cache của gói và 1,7GB đó là dành cho các gói của hơn 158.000 truy vấn adhoc. Trong số 1,7 GB đó, khoảng 500 MB được sử dụng cho 125.000 gói thực thi ONE Chỉ thời gian. Khoảng 1GB bộ nhớ đệm của gói dành cho các gói đã chuẩn bị và quy trình, và chúng chỉ chiếm khoảng 300 MB dung lượng. Nhưng lưu ý số lượng sử dụng trung bình - hơn 1 triệu cho các thủ tục. Khi xem xét kết quả này, tôi sẽ phân loại khối lượng công việc này là hỗn hợp - một số truy vấn được tham số hóa, một số truy vấn adhoc.
Bài đăng trên blog của Kimberly thảo luận về các tùy chọn để quản lý bộ nhớ cache của gói chứa rất nhiều truy vấn adhoc. Kế hoạch bộ nhớ cache phình ra chỉ là một vấn đề bạn phải đối mặt khi bạn có khối lượng công việc adhoc và trong bài đăng này, tôi muốn khám phá tác động của nó đối với CPU do kết quả của tất cả các quá trình tổng hợp phải xảy ra. Khi một truy vấn thực thi trong SQL Server, nó sẽ trải qua quá trình biên dịch và tối ưu hóa, và có chi phí liên quan đến quá trình này, thường biểu hiện dưới dạng chi phí CPU. Khi một kế hoạch truy vấn nằm trong bộ nhớ cache, nó có thể được sử dụng lại. Các truy vấn được tham số hóa cuối cùng có thể sử dụng lại một kế hoạch đã có trong bộ nhớ cache, vì văn bản truy vấn hoàn toàn giống nhau. Khi một truy vấn adhoc thực thi, nó sẽ chỉ sử dụng lại kế hoạch trong bộ nhớ cache nếu nó có chính xác cùng một văn bản và (các) giá trị đầu vào .
Thiết lập
Đối với thử nghiệm của chúng tôi, chúng tôi sẽ tạo một chuỗi ngẫu nhiên trong TSQL và nối nó với một truy vấn để mỗi lần thực thi có một giá trị chữ khác nhau. Tôi đã gói nó trong một thủ tục được lưu trữ gọi truy vấn bằng cách sử dụng Thực thi chuỗi động (EXEC @QueryString), vì vậy nó hoạt động giống như một câu lệnh adhoc. Gọi nó từ bên trong một thủ tục được lưu trữ có nghĩa là chúng ta có thể thực thi nó một số lần đã biết.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DBCC FREEPROCCACHE;
GO
EXEC dbo.[RandomSelects] @NumRows = 10;
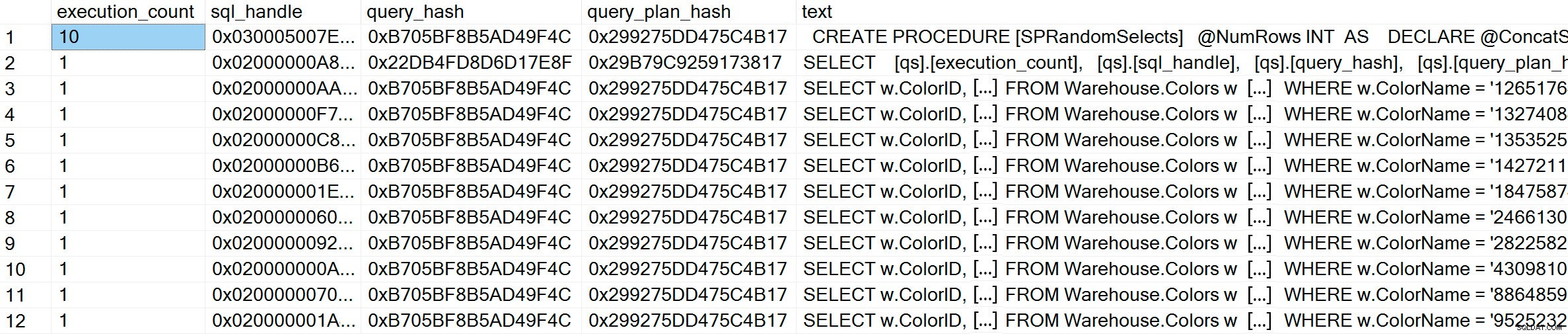
GO Sau khi thực thi, nếu chúng ta kiểm tra bộ nhớ cache của kế hoạch, chúng ta có thể thấy rằng chúng ta có 10 mục nhập duy nhất, mỗi mục có số_lượng_thực_hiện là 1 (phóng to hình ảnh nếu cần để xem các giá trị duy nhất cho vị từ):
SELECT [qs].[execution_count], [qs].[sql_handle], [qs].[query_hash], [qs].[query_plan_hash], [st].[text] FROM sys.dm_exec_query_stats AS [qs] CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st] CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp] WHERE [st].[text] LIKE '%Warehouse%' ORDER BY [st].[text], [qs].[execution_count] DESC; GO

Bây giờ chúng ta tạo một thủ tục được lưu trữ gần như giống hệt nhau thực thi cùng một truy vấn, nhưng được tham số hóa:
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = @ConcatString;
SELECT @RowLoop = @RowLoop + 1;
END
GO
EXEC dbo.[SPRandomSelects] @NumRows = 10;
GO Trong bộ nhớ cache của kế hoạch, ngoài 10 truy vấn adhoc, chúng tôi thấy một mục nhập cho truy vấn được tham số hóa đã được thực thi 10 lần. Bởi vì đầu vào được tham số hóa, ngay cả khi các chuỗi cực kỳ khác nhau được truyền vào tham số, văn bản truy vấn vẫn hoàn toàn giống nhau:
Thử nghiệm
Bây giờ chúng ta đã hiểu những gì xảy ra trong bộ nhớ cache của kế hoạch, hãy tạo thêm tải. Chúng tôi sẽ sử dụng một tệp dòng lệnh gọi cùng một tệp .sql trên 10 luồng khác nhau, với mỗi tệp gọi thủ tục được lưu trữ 10.000 lần. Chúng tôi sẽ xóa bộ nhớ cache của kế hoạch trước khi bắt đầu và nắm bắt Tổng số% CPU và SQL Compilations / giây bằng PerfMon trong khi các tập lệnh thực thi.
Nội dung tệp Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 10000;
Nội dung tệp parameterized.sql:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 10000;
Tệp lệnh mẫu (được xem trong Notepad) gọi tệp .sql:
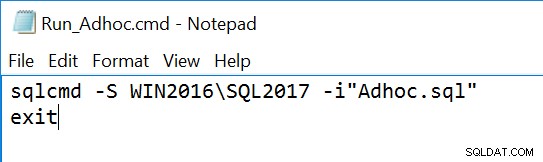
Tệp lệnh mẫu (được xem trong Notepad) tạo 10 chuỗi, mỗi chuỗi gọi tệp Run_Adhoc.cmd:
Sau khi chạy mỗi nhóm truy vấn tổng cộng 100.000 lần, nếu chúng ta nhìn vào bộ nhớ cache của gói, chúng ta thấy như sau:

Có hơn 10.000 kế hoạch adhoc trong bộ nhớ cache của kế hoạch. Bạn có thể thắc mắc tại sao không có một kế hoạch cho tất cả 100.000 truy vấn adhoc được thực thi và nó liên quan đến cách hoạt động của bộ đệm kế hoạch (kích thước của nó dựa trên bộ nhớ khả dụng, khi các gói không sử dụng đã hết hạn sử dụng, v.v.). Điều quan trọng là so nhiều kế hoạch adhoc tồn tại, so với những gì chúng tôi thấy đối với phần còn lại của các loại bộ nhớ cache.
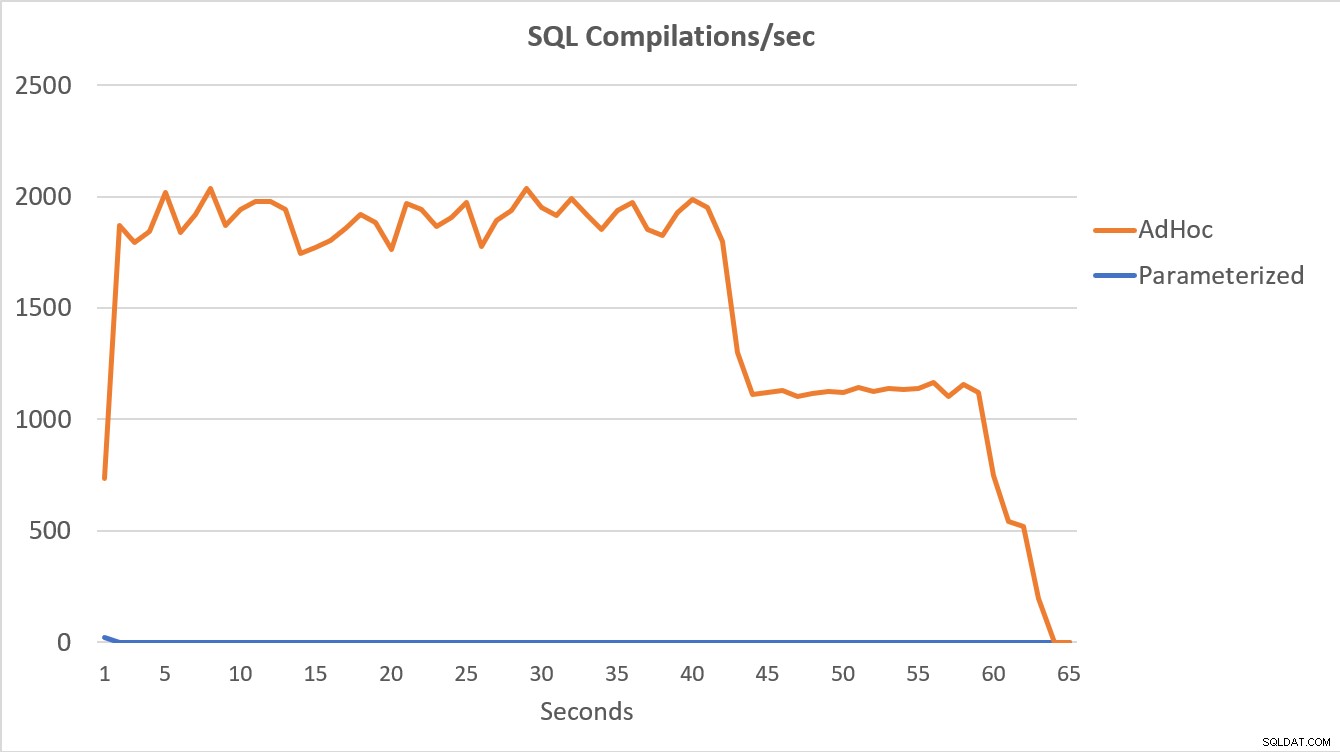
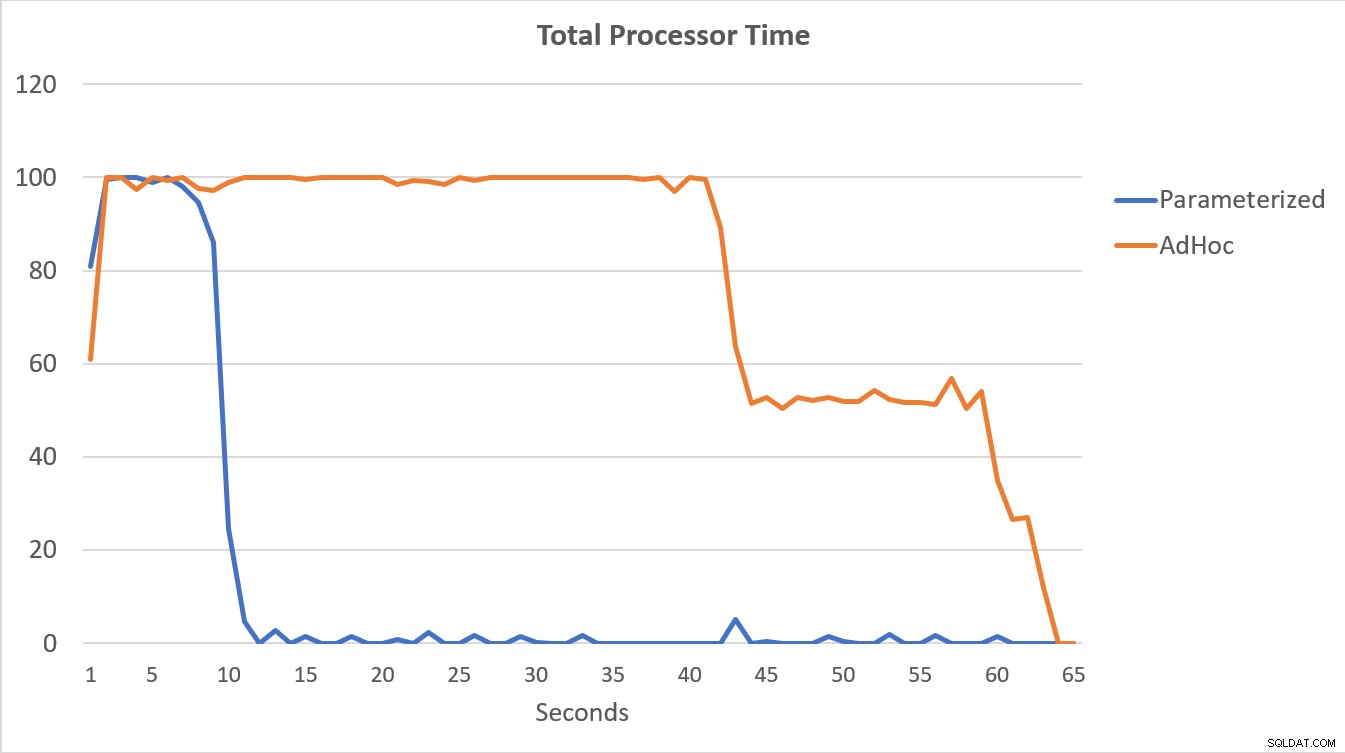
Dữ liệu PerfMon, được vẽ biểu đồ bên dưới, là đáng chú ý nhất. Việc thực thi 100.000 truy vấn tham số hoàn tất trong vòng chưa đầy 15 giây và có một sự tăng đột biến nhỏ về Tổng hợp / giây khi bắt đầu, điều này hầu như không đáng chú ý trên biểu đồ. Số lần thực thi adhoc tương tự chỉ mất hơn 60 giây để hoàn thành, với Tổng hợp / giây tăng vọt gần 2000 trước khi giảm xuống gần 1000 vào khoảng 45 giây, với CPU gần bằng hoặc ở mức 100% trong phần lớn thời gian.
Tóm tắt
Thử nghiệm của chúng tôi cực kỳ đơn giản ở chỗ chúng tôi chỉ gửi các biến thể cho một truy vấn adhoc, trong khi trong môi trường sản xuất, chúng tôi có thể có hàng trăm hoặc hàng nghìn biến thể khác nhau cho hàng trăm hoặc hàng nghìn của các truy vấn adhoc khác nhau. Tác động đến hiệu suất của các truy vấn adhoc này không chỉ là sự phình to của bộ đệm ẩn kế hoạch xảy ra, mặc dù vậy, hãy xem bộ đệm của kế hoạch là một nơi tuyệt vời để bắt đầu nếu bạn không quen với loại khối lượng công việc mình có. Một lượng lớn các truy vấn adhoc có thể thúc đẩy quá trình biên dịch và do đó CPU, đôi khi có thể bị che lấp bằng cách thêm nhiều phần cứng hơn, nhưng hoàn toàn có thể đến lúc CPU trở thành nút cổ chai. Nếu bạn cho rằng đây có thể là sự cố hoặc sự cố tiềm ẩn trong môi trường của mình, thì hãy xem xét để xác định truy vấn adhoc nào đang chạy thường xuyên nhất và xem bạn có những tùy chọn nào để tham số hóa chúng. Đừng hiểu lầm tôi - có những vấn đề tiềm ẩn với các truy vấn được tham số hóa (ví dụ:độ ổn định của kế hoạch do lệch dữ liệu) và đó là một vấn đề khác mà bạn có thể phải giải quyết. Bất kể khối lượng công việc của bạn là bao nhiêu, điều quan trọng là phải hiểu rằng hiếm khi có phương pháp "đặt nó và quên nó" để mã hóa, cấu hình, bảo trì, v.v. Các giải pháp SQL Server đang tồn tại, thực thể luôn thay đổi và liên tục chăm sóc và cung cấp cho thực hiện một cách đáng tin cậy. Một trong những nhiệm vụ của DBA là luôn cập nhật sự thay đổi đó và quản lý hiệu suất tốt nhất có thể - cho dù nó liên quan đến các thách thức hiệu suất adhoc hay tham số hóa.