Tìm hiểu cách sử dụng các công cụ OCR, Apache Spark và các thành phần Apache Hadoop khác để xử lý hình ảnh PDF trên quy mô lớn.
Công nghệ nhận dạng ký tự quang học (OCR) đã phát triển đáng kể trong 20 năm qua. Tuy nhiên, trong thời gian đó, có rất ít hoặc không có nỗ lực kết hợp OCR với các kiến trúc phân tán như Apache Hadoop để xử lý số lượng lớn hình ảnh trong thời gian gần thực.
Trong bài đăng này, bạn sẽ học cách sử dụng các công cụ mã nguồn mở tiêu chuẩn cùng với các thành phần Hadoop như Apache Spark, Apache Solr và Apache HBase để thực hiện điều đó đối với trường hợp sử dụng thông tin thiết bị y tế. Cụ thể, bạn sẽ sử dụng tập dữ liệu công khai để chuyển văn bản tường thuật thành các trường có thể tìm kiếm được.
Mặc dù ví dụ này tập trung vào thông tin thiết bị y tế, nhưng nó có thể được áp dụng trong nhiều trường hợp khác khi yêu cầu xử lý và lưu giữ hình ảnh. Ví dụ:các công ty bảo hiểm có thể tìm kiếm tất cả các tài liệu đã quét của họ trong các tệp yêu cầu bồi thường để giải quyết yêu cầu bồi thường tốt hơn. Tương tự, bộ phận chuỗi cung ứng trong một cơ sở sản xuất có thể quét tất cả các bảng dữ liệu kỹ thuật từ các nhà cung cấp linh kiện và làm cho chúng có thể tìm kiếm được bởi các nhà phân tích.
Trường hợp sử dụng:Đăng ký thiết bị y tế
Những năm gần đây đã chứng kiến một loạt thay đổi trong lĩnh vực đăng ký sản phẩm thuốc điện tử. Tiêu chuẩn ISO IDMP (Nhận dạng sản phẩm y tế) là một trong những định dạng thông báo như vậy để đăng ký sản phẩm và các chất có trong chúng, với ID sản phẩm thuốc, ID bao bì và ID lô được sử dụng để theo dõi sản phẩm trong trường hợp có trải nghiệm bất lợi, bất hợp pháp nhập khẩu, chống hàng giả, và các vấn đề khác về cảnh giác dược. Tiêu chuẩn yêu cầu rằng không chỉ các sản phẩm mới cần phải được đăng ký, mà hồ sơ cũ hơn / đã lưu trữ của mọi sản phẩm mà công chúng có thể tiếp xúc cũng phải được cung cấp dưới dạng điện tử.
Để tuân thủ các tiêu chuẩn IDMP ở các công ty khác nhau, các công ty phải có khả năng lấy và xử lý dữ liệu từ nhiều nguồn dữ liệu, chẳng hạn như RDBMS cũng như trong một số trường hợp, bảng dữ liệu sản phẩm kế thừa. Mặc dù người ta biết cách nhập dữ liệu từ RDBMS thông qua các công nghệ như Apache Sqoop, việc xử lý tài liệu kế thừa đòi hỏi nhiều công việc hơn một chút. Đối với hầu hết các phần, các tài liệu cần được nhập và văn bản có liên quan cần được trích xuất theo chương trình ở quy mô lớn bằng cách sử dụng các công nghệ OCR hiện có.
Tập dữ liệu
Chúng tôi sẽ sử dụng bộ dữ liệu từ FDA chứa tất cả 510 (k) hồ sơ mà các nhà sản xuất thiết bị y tế đã gửi từ năm 1976. Mục 510 (k) của Đạo luật Thực phẩm, Dược phẩm và Mỹ phẩm yêu cầu các nhà sản xuất thiết bị phải đăng ký thông báo FDA về ý định tiếp thị thiết bị y tế trước ít nhất 90 ngày.
Tập dữ liệu này hữu ích vì một số lý do trong trường hợp này:
- Dữ liệu miễn phí và thuộc miền công cộng.
- Dữ liệu phù hợp với quy định của Châu Âu, quy định này sẽ được kích hoạt vào tháng 7 năm 2016 (nơi các nhà sản xuất phải tuân thủ các tiêu chuẩn dữ liệu mới). Các chất bổ sung của FDA có thông tin quan trọng liên quan để có được cái nhìn đầy đủ về IDMP.
- Định dạng của tài liệu (PDF) cho phép chúng tôi thể hiện các kỹ thuật OCR đơn giản nhưng hiệu quả khi xử lý các tài liệu có nhiều định dạng.
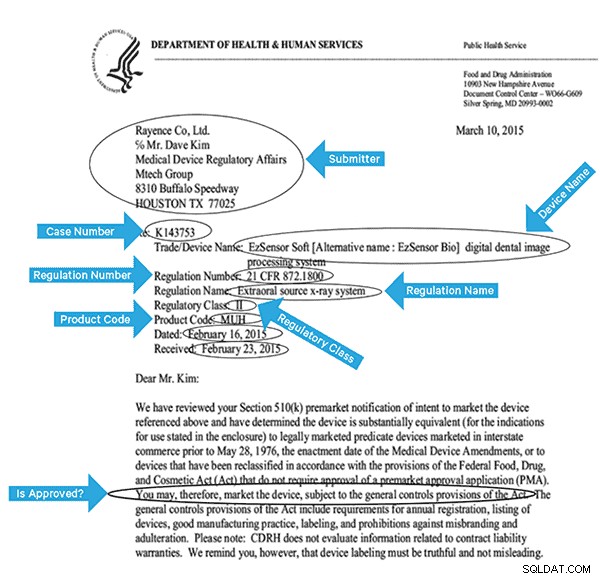
Để lập chỉ mục dữ liệu này một cách hiệu quả, chúng tôi sẽ cần trích xuất một số trường từ hình ảnh. Dưới đây là tài liệu mẫu, với các trường tiềm năng có thể được trích xuất.
Kiến trúc cấp cao
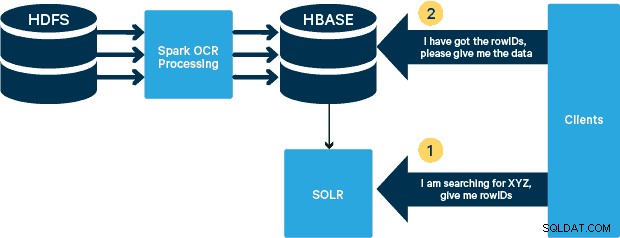
Đối với trường hợp sử dụng này, các tệp PDF được lưu trữ trong HDFS và được xử lý bằng thư viện Spark và OCR. (Bước nhập nằm ngoài phạm vi của bài đăng này, nhưng nó có thể đơn giản như chạy hdfs -dfs -put hoặc sử dụng giao diện webhdfs.) Spark cho phép sử dụng mã gần giống hệt nhau trong ứng dụng Spark Streaming để phát trực tuyến gần thời gian thực và HBase là phương tiện lưu trữ hoàn hảo để truy cập ngẫu nhiên có độ trễ thấp — và rất phù hợp để lưu trữ hình ảnh, với chức năng MOB mới, để khởi động. Cloudera Search (được xây dựng trên Apache Solr) là giải pháp tìm kiếm duy nhất tích hợp nguyên bản với HBase, do đó cho phép bạn tạo các chỉ mục phụ.
Thiết lập bảng thiết bị y tế trong HBase
Chúng tôi sẽ giữ giản đồ cho trường hợp sử dụng của chúng tôi. RowID sẽ là tên tệp và sẽ có hai họ cột:“thông tin” và “đối tượng”. Họ cột "thông tin" sẽ chứa tất cả các trường mà chúng tôi trích xuất từ hình ảnh. Họ cột "obj" sẽ chứa các byte của đối tượng nhị phân thực, trong trường hợp này là PDF. Tên của bảng trong trường hợp của chúng ta sẽ là “mdds”.
Chúng tôi sẽ tận dụng chức năng HBase MOB (đối tượng trung bình) được giới thiệu trong HBASE-11339. Để thiết lập HBase để xử lý MOB, bạn cần thực hiện thêm một số bước, nhưng thuận tiện, bạn có thể tìm thấy hướng dẫn trên liên kết này.
Có nhiều cách để tạo bảng trong HBase theo chương trình (API Java, API REST hoặc một phương pháp tương tự). Ở đây, chúng tôi sẽ sử dụng vỏ HBase để tạo bảng “mdds” (cố ý sử dụng tên họ cột mô tả để làm cho mọi thứ dễ theo dõi hơn). Chúng tôi muốn sao chép họ cột “thông tin” sang Solr, nhưng không phải dữ liệu MOB.
Lệnh dưới đây sẽ tạo bảng và cho phép sao chép trên một họ cột được gọi là “thông tin”. Điều quan trọng là chỉ định tùy chọn REPLICATION_SCOPE => '1' , nếu không thì HBase Lily Indexer sẽ không nhận được bất kỳ bản cập nhật nào từ HBase. Chúng tôi muốn sử dụng đường dẫn MOB trong HBase cho các đối tượng lớn hơn 10MB. Để thực hiện điều đó, chúng tôi cũng tạo một họ cột khác, được gọi là "obj", sử dụng các tham số sau cho MOB:
IS_MOB => true, MOB_THRESHOLD => 10240000
IS_MOB tham số chỉ định xem họ cột này có thể lưu trữ các MOB hay không, trong khi MOB_THRESHOLD chỉ định sau khi đối tượng phải có kích thước lớn như thế nào để nó được coi là MOB. Vì vậy, hãy tạo bảng:
tạo 'mdds', {NAME => 'thông tin', DATA_BLOCK_ENCODING => 'FAST_DIFF', REPLICATION_SCOPE => '1'}, {NAME => 'obj', IS_MOB => true, MOB_THRESHOLD => 10240000} Để xác nhận bảng đã được tạo đúng cách, hãy chạy lệnh sau trong HBase shell:
hbase (main):001:0> description 'mdds'Mddsable is ENABLEDmddsCOLUMN FAMILIES DESCRIPTION {NAME =>' info ', DATA_BLOCK_ENCODING =>' FAST_DIFF ', BLOOMFILTER =>' ROW ', REPLICATION_SCOPE =>' 1 ' , VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'} {NAME => 'obj', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', COMPRESSION => 'NONE', VERSIONS => '1', MIN_VERSIONS => '0', TTL => 'FOREVER', MOB_THRESHOLD => '10240000', IS_MOB => 'true', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'} 2 hàng trong 0,3440 giây Xử lý hình ảnh được quét bằng Tesseract
OCR đã đi một chặng đường dài trong việc giải quyết các vấn đề về biến thể phông chữ, nhiễu hình ảnh và căn chỉnh. Ở đây, chúng tôi sẽ sử dụng công cụ OCR mã nguồn mở Tesseract, công cụ này ban đầu được phát triển dưới dạng phần mềm độc quyền tại các phòng thí nghiệm của HP. Sự phát triển Tesseract kể từ đó đã được phát hành dưới dạng phần mềm mã nguồn mở và được tài trợ bởi Google từ năm 2006.
Tesseract là một thư viện phần mềm có tính di động cao. Nó sử dụng thư viện xử lý hình ảnh Leptonica để tạo hình ảnh nhị phân bằng cách thực hiện việc tạo ngưỡng thích ứng trên hình ảnh màu xám hoặc màu.
Quá trình xử lý theo quy trình từng bước truyền thống. Sau đây là quy trình sơ bộ của các bước:
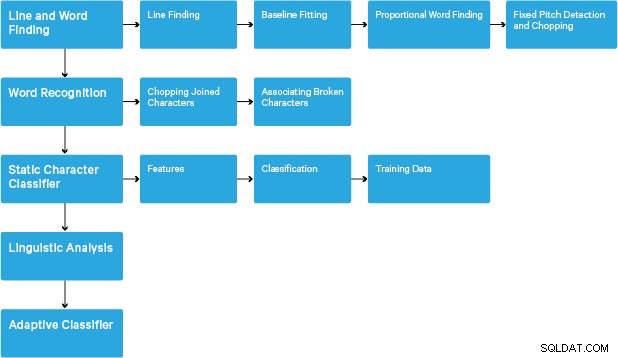
Quá trình xử lý bắt đầu với phân tích thành phần được kết nối, kết quả là lưu trữ các thành phần được tìm thấy. Bước này giúp kiểm tra sự lồng ghép của các phác thảo và số lượng các phác thảo con và cháu.
Ở giai đoạn này, các phác thảo được tập hợp lại với nhau, hoàn toàn bằng cách lồng vào nhau, thành các Đối tượng Lớn Nhị phân (BLOB). BLOB được tổ chức thành các dòng văn bản và các dòng và vùng được phân tích để tìm cao độ cố định hoặc văn bản tỷ lệ. Các dòng văn bản được chia thành các từ khác nhau tùy theo loại khoảng cách ký tự. Văn bản cao độ cố định được cắt ngay lập tức bởi các ô ký tự. Văn bản theo tỷ lệ được chia thành các từ bằng cách sử dụng dấu cách xác định và dấu cách mờ.
Sau đó, công nhận sẽ tiến hành như một quá trình hai lần. Trong lần vượt qua đầu tiên, một nỗ lực được thực hiện để nhận ra lần lượt từng từ. Mỗi từ đạt yêu cầu sẽ được chuyển đến bộ phân loại thích ứng dưới dạng dữ liệu huấn luyện. Sau đó, trình phân loại thích ứng có cơ hội nhận dạng chính xác hơn văn bản ở dưới trang. Vì trình phân loại thích ứng có thể đã học được điều gì đó hữu ích quá muộn để thực hiện đóng góp ở gần đầu trang, nên lần chuyển thứ hai sẽ chạy qua trang, trong đó các từ không được nhận dạng đủ tốt sẽ được nhận dạng lại. Giai đoạn cuối cùng giải quyết các khoảng mờ và kiểm tra các giả thuyết thay thế cho chiều cao x để xác định văn bản có chữ cap nhỏ.
Tesseract ở dạng hiện tại hoàn toàn có khả năng unicode và được đào tạo cho một số ngôn ngữ. Dựa trên nghiên cứu của chúng tôi, nó là một trong những thư viện mã nguồn mở chính xác nhất hiện có cho OCR. Như đã đề cập trước đó, Tesseract sử dụng Leptonica. Chúng tôi cũng sử dụng Ghostscript để chia các tệp PDF thành hình ảnh. (Bạn có thể chia thành định dạng nén hình ảnh mà bạn chọn; chúng tôi đã chọn PNG.) Ba thư viện này được viết bằng C ++ và để gọi chúng từ các chương trình Java / Scala, chúng ta cần sử dụng các triển khai của Java Native Interfaces tương ứng. Trong công việc của mình, chúng tôi sử dụng các ràng buộc JNI từ JavaPresets. (Bạn có thể tìm thấy hướng dẫn xây dựng bên dưới.) Chúng tôi đã sử dụng Scala để viết trình điều khiển Spark.
trình kết xuất val:SimpleRenderer = new Hình ảnh val của SimpleRenderer () renderer.setResolution (300):List [Image] =renderer.render (document)
Leptonica đọc các hình ảnh được tách từ bước trước.
ImageIO.write (x.asInstanceOf [RenderedImage], "png", imageByteStream) val pix:PIX =pixReadMem (ByteBuffer.wrap (imageByteStream.toByteArray ()) .array (), ByteBuffer.wrap (imageByteArray. )) .capacity ())
Sau đó, chúng tôi sử dụng lệnh gọi API Tesseract để trích xuất văn bản. Chúng tôi giả sử các tài liệu ở đây bằng tiếng Anh, do đó tham số thứ hai của phương thức Init là “eng.”
val api:TessBaseAPI =new TessBaseAPI () api.Init (null, "eng") api.SetImage (pix) api.GetUTF8Text (). getString ()
Sau khi hình ảnh được xử lý, chúng tôi trích xuất một số trường từ văn bản và gửi chúng đến HBase.
def populateHbase (fileName:String, lines:String, pdf:org.apache.spark.input.PortableDataStream):Unit ={/ ** Định cấu hình và mở kết nối HBase * / val mddsTbl =_conn.getTable (TableName. valueOf ("mdds")); val cf ="info" val put =new Put (Bytes.toBytes (fileName)) / ** * Trích xuất các trường tại đây bằng cách sử dụng Regexes * Tạo đối tượng Put và gửi đến HBase * / val aAndCP ="" "(? s) (? m). * \ d \ d \ d \ d \ d- \ d \ d \ d \ d (. *) \ nRe:(\ w \ d \ d \ d \ d \ d \ d). * "" ".r …… .. dòng khớp với {case aAndCP (addr, casenum) => put.add (Bytes.toBytes (cf), Bytes.toBytes (" submitter_info "), Bytes.toBytes (addr)) .add (Bytes .toBytes (cf), Bytes.toBytes ("case_num"), Bytes.toBytes (casenum)) case _ => println ("không khớp với regex")} ……. lines.split ("\ n"). foreach {val regNumRegex ="" "Số quy định:\ s + (. +)" "". r val regNameRegex ="" "Tên quy định:\ s + (. +)" "" .r …… .. ……. _ match {case regNumRegex (regNum) => put.add (Bytes.toBytes (cf), Bytes.toBytes ("reg_num"), …….… .. case _ => print ("")}} put.add (Bytes.toBytes (cf), Bytes.toBytes ("text"), Bytes.toBytes (lines)) val pdfBytes =pdf.toArray.clone put.add (Bytes.toBytes ("obj"), Bytes.toBytes (" pdf "), pdfBytes) mddsTbl.put (đặt) …….} Nếu bạn xem xét kỹ đoạn mã ở trên, ngay trước khi chúng tôi gửi đối tượng Put tới HBase, chúng tôi sẽ chèn các byte PDF thô vào họ cột “obj” của bảng. Chúng tôi sử dụng HBase làm lớp lưu trữ cho các trường được trích xuất cũng như hình ảnh thô. Điều này giúp ứng dụng trích xuất ảnh gốc nhanh chóng và thuận tiện, nếu cần. Mã đầy đủ có thể được tìm thấy ở đây. (Cần lưu ý rằng trong khi chúng tôi sử dụng các API HBase tiêu chuẩn để tạo các đối tượng Đặt cho HBase, trong một hệ thống sản xuất thực tế, sẽ là điều khôn ngoan khi xem xét sử dụng các API SparkOnHBase, cho phép cập nhật hàng loạt cho HBase từ Spark RDD.)
Đường ống thực thi
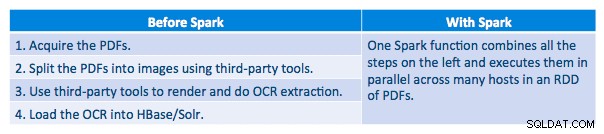
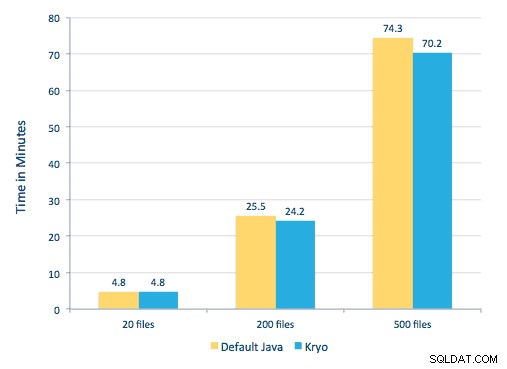
Chúng tôi có thể xử lý từng tệp PDF trong một khuôn khổ nối tiếp. Để mở rộng quy mô xử lý, chúng tôi đã chọn xử lý các tệp PDF này theo kiểu phân tán bằng Spark. Biểu đồ sau minh họa cách chúng tôi kết hợp các giai đoạn khác nhau của quá trình xử lý này để biến quy trình công việc thành một lệnh gọi macro đơn giản từ Spark và tải dữ liệu vào HBase.
Chúng tôi cũng đã thử so sánh giữa các phương pháp tuần tự hóa, nhưng với tập dữ liệu của mình, chúng tôi không thấy sự khác biệt đáng kể về hiệu suất.
Thiết lập Môi trường
Phần cứng được sử dụng:Cụm năm nút với bộ nhớ 15GB, 4 vCPU và SSD 2x40GB
Vì chúng tôi đang sử dụng thư viện C ++ để xử lý, chúng tôi đã sử dụng các liên kết JNI có thể tìm thấy tại đây.
Xây dựng các liên kết JNI cho Tesseract và Leptonica từ các cài đặt trước của javaCPP:
-
- Trên tất cả các nút:
yum -y install automake autoconf libtool zlib-devel libjpeg-devel giflib libtiff-devel libwebp libwebp-devel libicu-devel openjpeg-devel cairo-devel -
git clone https://github.com/bytedeco/javacpp-presets.git -
cd javacpp-presets - Xây dựng Leptonica.
cd leptonica./cppbuild.sh cài đặt leptonicacd cppbuild / linux-x86_64 / leptonica-1.72 / LDFLAGS ="- Wl, -rpath -Wl, / usr / local / lib" ./configuremake &&sudo make installcd ../../../mvn clean installcd ..
- Xây dựng Khối lập phương.
- Trên tất cả các nút:
cd tesseract./cppbuild.sh install tesseractcd tesseract / cppbuild / linux-x86_64 / tesseract-3.03LDFLAGS ="- Wl, -rpath -Wl, / usr / local / lib" ./configuremake &&make installcd ../ ../../mvn clean installcd ..
- Xây dựng các cài đặt trước javaCPP.
mvn clean install --projects leptonica, tesseract
Chúng tôi sử dụng Ghostscript để trích xuất hình ảnh từ các tệp PDF. Hướng dẫn xây dựng Ghostscript, tương ứng với các phiên bản Tesseract và Leptonica được sử dụng tại đây, như sau. (Đảm bảo rằng Ghostscript không được cài đặt trong hệ thống thông qua trình quản lý gói.)
wget https://downloads.ghostscript.com/public/ghostscript-9.16.tar.gztar zxvf ghostcript-9.16.tar.gzcd ghostcript-9.16./autogen.sh &&./configure --prefix=/ usr - -disable-compile-inits --enable-dynamicudo make &&make soinstall &&install -v -m644 base / *. h / usr / include / ghostcript &&ln -v -s ghostcript / usr / include / ps (Tùy thuộc vào ldpath của bạn cài đặt, bạn có thể phải làm):sudo ln -sf /usr/lib/libgs.so /usr/local/lib/libgs.so
Đảm bảo rằng tất cả các thư viện cần thiết đều nằm trong classpath. Chúng tôi đặt tất cả các lọ có liên quan trong một thư mục có tên là lib. Dấu phẩy rất quan trọng bên dưới:
$ cho tôi trong `ls lib / *`; xuất MY_JARS =. / $ i, $ MY_JARS; donetesseract.jar, tesseract-linux-x86_64.jar, javacpp.jar, ghost4j-1.0.0.jar, leptonica.jar, leptonica-1.72-1.0.jar, leptonica-linux-x86_64.jar
Chúng tôi gọi chương trình Spark như sau. Chúng ta cần chỉ định extraLibraryPath cho các thư viện Ghostscript gốc; conf khác là cần thiết cho Tesseract.
spark-submit --jars $ MY_JARS --num-Operating 12 --executor-memory 4G --executor-core 1 --conf spark.executor.extraLibraryPath =/ usr / local / lib --confspark.executorEnv. TESSDATA_PREFIX =/ home / vsingh / javacpp-presets / tesseract / cppbuild / 1-x86_64 / share / tessdata / --confspark.executor.extraClassPath =/ etc / hbase / conf:/ opt / cloudera / parcels / CDH / lib / hbase /lib/htrace-core-3.1.0-incubating.jar --driver-class-path / etc / hbase / conf:/opt/cloudera/parcels/CDH/lib/hbase/lib/htrace-core-3.1.0 -incubating.jar --conf spark.serializer =org.apache.spark.serializer.KryoSerializer - conf spark.kryoserializer.buffer.mb =24 --class com.cloudera.sa.OCR.IdmpExtraction
Tạo Bộ sưu tập Solr
Solr tích hợp khá liền mạch với HBase thông qua Lily HBase Indexer. Để hiểu cách thực hiện tích hợp Tích hợp Lily Indexer với HBase, bạn có thể xem qua bài đăng trước của chúng tôi trong phần “Tìm hiểu về nhân bản HBase và Trình lập chỉ mục Lily HBase”.
Dưới đây, chúng tôi phác thảo các bước cần thực hiện để tạo chỉ mục:
- Tạo tệp cấu hình schema.xml mẫu:
solrctl --zk localhost:2181 instancedir --generate $HOME/solrcfg - Chỉnh sửa tệp schema.xml trong
$HOME/solrcfg, chỉ định các trường chúng ta cần cho bộ sưu tập của mình. Toàn bộ tệp có thể được tìm thấy tại đây. - Tải các cấu hình Solr lên ZooKeeper:
solrctl --zk localhost:2181/solr instancedir --create mdds_collection $HOME/solrcfg - Tạo bộ sưu tập Solr với 2 phân đoạn (-s 2) và 2 bản sao (-r 2):
solrctl --zk localhost:2181/solr --solr localhost:8983/solr collection --create mdds_collection -s 2 -r 2
Trong lệnh trên, chúng tôi đã tạo một bộ sưu tập Solr với hai tham số phân đoạn (-s 2) và hai bản sao (-r 2). Các tham số là đủ cho kho tài liệu của chúng tôi, nhưng trong một triển khai thực tế, người ta sẽ phải đặt số lượng dựa trên các cân nhắc khác ngoài phạm vi thảo luận của chúng tôi tại đây.
Đăng ký Trình chỉ mục
Bước này là cần thiết để thêm và cấu hình trình chỉ mục và bản sao HBase. Lệnh dưới đây sẽ cập nhật ZooKeeper và thêm mdds_indexer như một trình nhân bản ngang hàng cho HBase. Nó cũng sẽ chèn các cấu hình vào ZooKeeper, mà Lily HBase Indexer sẽ sử dụng để trỏ đến đúng bộ sưu tập trong Solr. |
hbase-indexer add-indexer -n mdds_indexer -c indexer-config.xml -cp solr.zk =localhost:2181 / solr -cp solr.collection =mdds_collection.
Lập luận:
-
-n mdds_indexer- chỉ định tên của trình chỉ mục sẽ được đăng ký trong ZooKeeper -
-c indexer-config.xml- tệp cấu hình sẽ chỉ định hành vi của người lập chỉ mục -
-cp solr.zk=localhost:2181/solr- chỉ định vị trí của cấu hình ZooKeeper và Solr. Điều này sẽ được cập nhật với vị trí môi trường cụ thể của ZooKeeper. -
-cp solr.collection=mdds_collection- chỉ định bộ sưu tập nào cần cập nhật. Nhớ lại bước Cấu hình Solr nơi chúng ta đã tạo bộ sưu tập1.
index-config.xml tệp tương đối đơn giản trong trường hợp này; tất cả những gì nó làm là chỉ định cho người lập chỉ mục xem bảng nào, lớp sẽ được sử dụng như một trình ánh xạ (com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper ), và vị trí của tệp cấu hình Morphline. Theo mặc định, loại ánh xạ được đặt thành hàng , trong trường hợp đó tài liệu Solr trở thành hàng đầy đủ. Param name="morphlineFile" chỉ định vị trí của tệp cấu hình Morphlines. Vị trí có thể là một đường dẫn tuyệt đối của tệp Morphlines của bạn, nhưng vì bạn đang sử dụng Trình quản lý Cloudera, hãy chỉ định đường dẫn tương đối là morphlines.conf.
Bạn có thể tìm thấy nội dung của tệp cấu hình hbase-indexer tại đây.
Định cấu hình và khởi động Trình chỉ mục Lily HBase
Khi bật Trình lập chỉ mục Lily HBase, bạn cần chỉ định logic chuyển đổi Morphlines sẽ cho phép trình lập chỉ mục này phân tích cú pháp cập nhật cho bảng Thiết bị y tế và trích xuất tất cả các trường liên quan. Đi tới Dịch vụ và chọn Trình lập chỉ mục Lily HBase mà bạn đã thêm trước đó. Chọn Cấu hình-> Xem và chỉnh sửa-> Toàn dịch vụ-> Đường hình thái . Sao chép và dán tệp Morphlines.
Thư viện morphlines thiết bị y tế sẽ thực hiện các tác vụ sau:
- Đọc các sự kiện email HBase bằng
extractHBaseCellslệnh - Chuyển đổi ngày / dấu thời gian thành trường mà Solr sẽ hiểu, với
convertTimestamplệnh - Bỏ tất cả các trường bổ sung mà chúng tôi không chỉ định trong schema.xml, với
sanitizeUknownSolrFieldslệnh
Tải xuống bản sao của tệp Morphlines này từ đây.
Một lưu ý quan trọng là trường id sẽ được tạo tự động bởi Lily HBase Indexer. Bạn có thể định cấu hình cài đặt đó trong tệp index-config.xml ở trên bằng cách chỉ định thuộc tính duy nhất-key-field. Cách tốt nhất là để lại tên mặc định của id — vì nó không được chỉ định trong tệp xml ở trên, trường id mặc định đã được tạo và sẽ là sự kết hợp của RowID.
Truy cập dữ liệu
Bạn có thể lựa chọn nhiều công cụ trực quan để truy cập các hình ảnh được lập chỉ mục. HUE và Solr GUI đều là những lựa chọn rất tốt. HBase cũng cho phép một số kỹ thuật truy cập, không chỉ từ GUI mà còn thông qua HBase shell, API và thậm chí cả các kỹ thuật tập lệnh đơn giản.
Tích hợp với Solr mang lại cho bạn tính linh hoạt cao và cũng có thể cung cấp các tùy chọn tìm kiếm rất đơn giản cũng như nâng cao cho dữ liệu của bạn. Ví dụ:việc định cấu hình tệp schema.xml của Solr sao cho tất cả các trường trong đối tượng email được lưu trữ trong Solr cho phép người dùng truy cập nội dung thư đầy đủ thông qua một tìm kiếm đơn giản, với sự đánh đổi của không gian lưu trữ và độ phức tạp của tính toán. Ngoài ra, bạn có thể định cấu hình Solr để chỉ lưu trữ một số trường giới hạn, chẳng hạn như id. Với các phần tử này, người dùng có thể nhanh chóng tìm kiếm Solr và lấy ra rowID, từ đó có thể được sử dụng để truy xuất các trường riêng lẻ hoặc toàn bộ hình ảnh từ chính HBase.
Ví dụ trên chỉ lưu trữ rowID trong Solr nhưng lập chỉ mục trên tất cả các trường được trích xuất từ hình ảnh. Tìm kiếm Solr trong trường hợp này truy xuất ID hàng HBase, sau đó bạn có thể sử dụng để truy vấn HBase. Kiểu thiết lập này lý tưởng cho Solr vì nó giữ cho chi phí lưu trữ thấp và tận dụng hết khả năng lập chỉ mục của Solr.
Truy vấn mẫu
Dưới đây là một số truy vấn ví dụ có thể được thực hiện từ ứng dụng vào Solr. Ý tưởng là lúc đầu khách hàng sẽ truy vấn các chỉ mục Solr, trả về rowID từ HBase. Sau đó, truy vấn HBase cho phần còn lại của các trường và / hoặc hình ảnh thô ban đầu.
- Cung cấp cho tôi tất cả các tài liệu được gửi trong khoảng thời gian sau:
https://hbase-solr2-1.vpc.cloudera.com:8983/solr/mdds_collection/select?q=renition:[2010-01 -06T23:59:59,999Z ĐẾN 2010-02-06T23:59:59,999Z]
- Cung cấp cho tôi các tài liệu đã được nộp theo tên quy định của Hệ thống X-quang Di động:
https://hbase-solr2-1.vpc.cloudera.com:8983/solr/mdds_collection/select?q=reg_name:Mobile hệ thống x-quang
- Cung cấp cho tôi tất cả tài liệu được gửi từ các nhà sản xuất Trung Quốc:
https://hbase-solr2-1.vpc.cloudera.com:8983/solr/mdds_collection/select?q=submitter_info:*China*
Id từ tài liệu Solr là ID hàng trong HBase; phần thứ hai của truy vấn sẽ là HBase để trích xuất dữ liệu (bao gồm cả tệp PDF thô nếu được yêu cầu).
Truy cập qua HUE
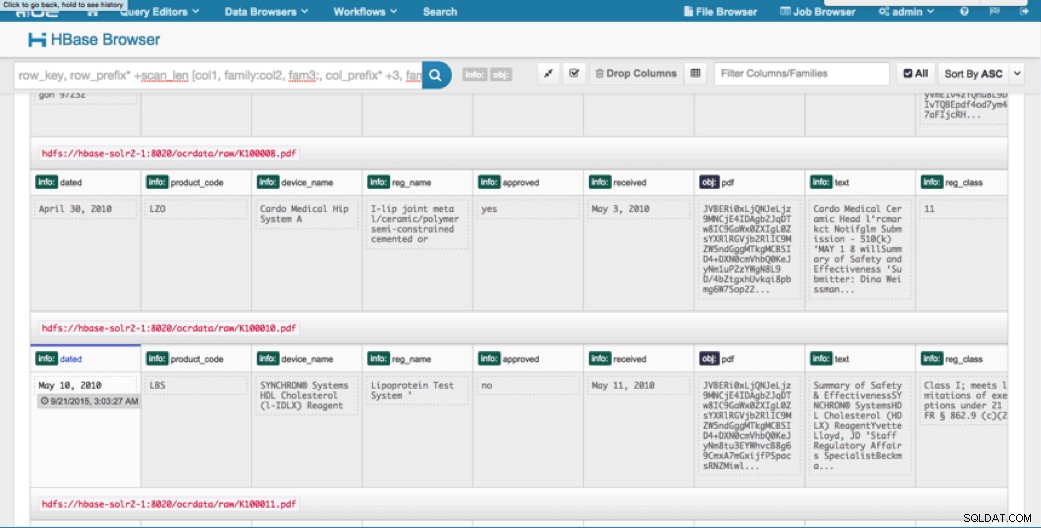
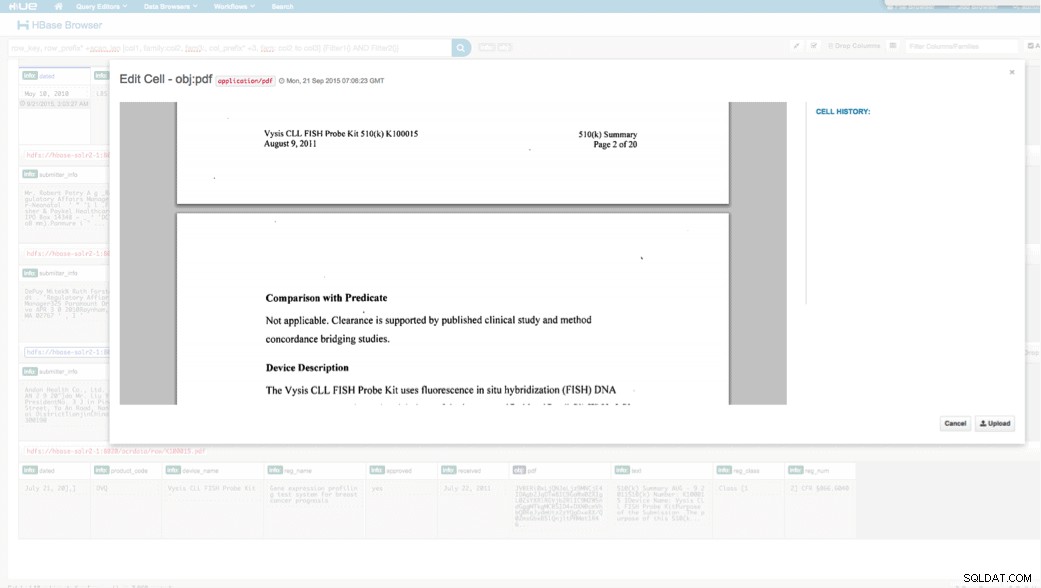
Chúng tôi có thể xem dữ liệu đã tải lên thông qua Trình duyệt HBase ở HUẾ. Một điều tuyệt vời về HUE là nó có thể phát hiện các tệp nhị phân cho PDF và hiển thị chúng khi được nhấp vào.
Dưới đây là ảnh chụp nhanh chế độ xem các trường được phân tích cú pháp trong các hàng HBase và cũng là chế độ xem được kết xuất của một trong các đối tượng PDF được lưu trữ dưới dạng MOB trong họ cột obj.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách sử dụng các công nghệ nguồn mở tiêu chuẩn để thực hiện OCR trên các tài liệu được quét bằng chương trình Spark có thể mở rộng, lưu trữ vào HBase để truy xuất nhanh và lập chỉ mục thông tin được trích xuất trong Solr. Cần phải rõ ràng rằng:
- Với định dạng đặc tả thông báo, chúng tôi có thể trích xuất các trường và cặp giá trị và làm cho chúng có thể tìm kiếm được thông qua Solr.
- Các trường này từ dữ liệu có thể đáp ứng các yêu cầu của IDMP về việc tạo dữ liệu cũ ở dạng điện tử, sẽ có hiệu lực vào năm sau.
- Các trường cũng như hình ảnh thô có thể được duy trì trong HBase và được truy cập thông qua các API tiêu chuẩn.
Nếu bạn thấy mình cần xử lý các tài liệu được quét và kết hợp dữ liệu với nhiều nguồn khác trong doanh nghiệp của mình, hãy cân nhắc sử dụng kết hợp Spark, HBase, Solr, cùng với Tesseract và Leptonica. Nó có thể giúp bạn tiết kiệm đáng kể thời gian và tiền bạc!
Jeff Shmain là Kiến trúc sư Giải pháp Cấp cao tại Cloudera. Ông có hơn 16 năm kinh nghiệm trong ngành tài chính với sự hiểu biết sâu sắc về giao dịch chứng khoán, rủi ro và các quy định. Trong vài năm qua, anh ấy đã làm việc trong nhiều triển khai trường hợp sử dụng khác nhau tại 8 trong số 10 ngân hàng đầu tư lớn nhất thế giới.
Vartika Singh là Chuyên gia Tư vấn Giải pháp Cấp cao tại Cloudera. Cô đã có hơn 12 năm kinh nghiệm trong lĩnh vực máy học ứng dụng và phát triển phần mềm.



